 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPVTON: Image-based 3D Virtual Try-on with Image Prompt Adapter
Jan 26, 2025
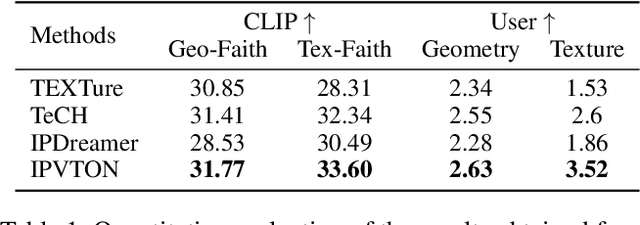
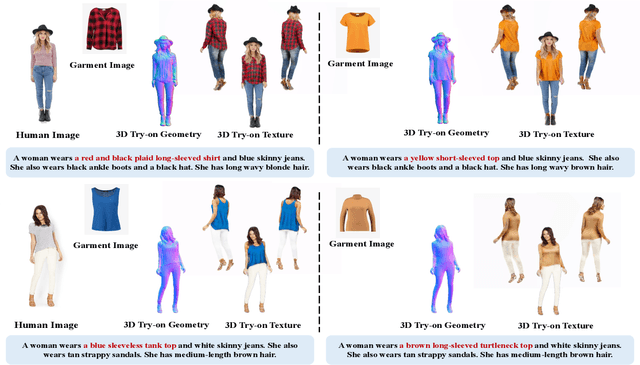
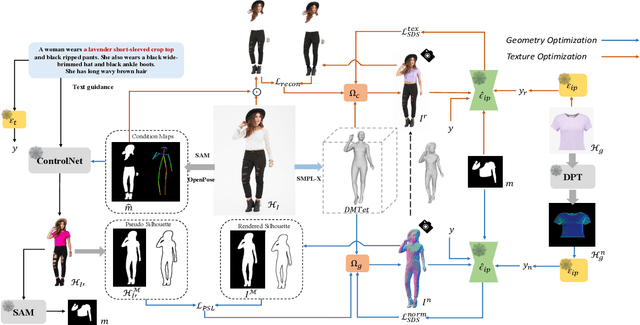
Given a pair of images depicting a person and a garment separately, image-based 3D virtual try-on methods aim to reconstruct a 3D human model that realistically portrays the person wearing the desired garment. In this paper, we present IPVTON, a novel image-based 3D virtual try-on framework. IPVTON employs score distillation sampling with image prompts to optimize a hybrid 3D human representation, integrating target garment features into diffusion priors through an image prompt adapter. To avoid interference with non-target areas, we leverage mask-guided image prompt embeddings to focus the image features on the try-on regions. Moreover, we impose geometric constraints on the 3D model with a pseudo silhouette generated by ControlNet, ensuring that the clothed 3D human model retains the shape of the source identity while accurately wearing the target garments. Extensive qualitative and quantitative experiments demonstrate that IPVTON outperforms previous methods in image-based 3D virtual try-on tasks, excelling in both geometry and texture.
DeCo: Decoupled Human-Centered Diffusion Video Editing with Motion Consistency
Aug 14, 2024
Diffusion models usher a new era of video editing, flexibly manipulating the video contents with text prompts. Despite the widespread application demand in editing human-centered videos, these models face significant challenges in handling complex objects like humans. In this paper, we introduce DeCo, a novel video editing framework specifically designed to treat humans and the background as separate editable targets, ensuring global spatial-temporal consistency by maintaining the coherence of each individual component. Specifically, we propose a decoupled dynamic human representation that utilizes a parametric human body prior to generate tailored humans while preserving the consistent motions as the original video. In addition, we consider the background as a layered atlas to apply text-guided image editing approaches on it. To further enhance the geometry and texture of humans during the optimization, we extend the calculation of score distillation sampling into normal space and image space. Moreover, we tackle inconsistent lighting between the edited targets by leveraging a lighting-aware video harmonizer, a problem previously overlooked in decompose-edit-combine approaches. Extensive qualitative and numerical experiments demonstrate that DeCo outperforms prior video editing methods in human-centered videos, especially in longer videos.
DI-Net : Decomposed Implicit Garment Transfer Network for Digital Clothed 3D Human
Nov 28, 2023

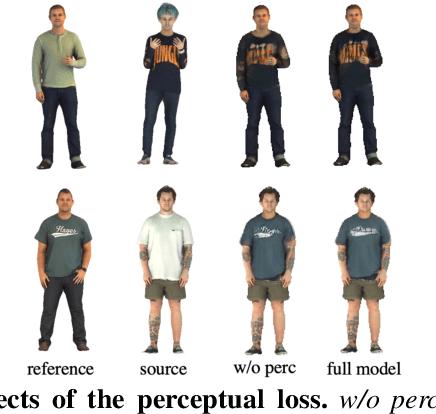

3D virtual try-on enjoys many potential applications and hence has attracted wide attention. However, it remains a challenging task that has not been adequately solved. Existing 2D virtual try-on methods cannot be directly extended to 3D since they lack the ability to perceive the depth of each pixel. Besides, 3D virtual try-on approaches are mostly built on the fixed topological structure and with heavy computation. To deal with these problems, we propose a Decomposed Implicit garment transfer network (DI-Net), which can effortlessly reconstruct a 3D human mesh with the newly try-on result and preserve the texture from an arbitrary perspective. Specifically, DI-Net consists of two modules: 1) A complementary warping module that warps the reference image to have the same pose as the source image through dense correspondence learning and sparse flow learning; 2) A geometry-aware decomposed transfer module that decomposes the garment transfer into image layout based transfer and texture based transfer, achieving surface and texture reconstruction by constructing pixel-aligned implicit functions. Experimental results show the effectiveness and superiority of our method in the 3D virtual try-on task, which can yield more high-quality results over other existing methods.
SARA: Controllable Makeup Transfer with Spatial Alignment and Region-Adaptive Normalization
Nov 28, 2023



Makeup transfer is a process of transferring the makeup style from a reference image to the source images, while preserving the source images' identities. This technique is highly desirable and finds many applications. However, existing methods lack fine-level control of the makeup style, making it challenging to achieve high-quality results when dealing with large spatial misalignments. To address this problem, we propose a novel Spatial Alignment and Region-Adaptive normalization method (SARA) in this paper. Our method generates detailed makeup transfer results that can handle large spatial misalignments and achieve part-specific and shade-controllable makeup transfer. Specifically, SARA comprises three modules: Firstly, a spatial alignment module that preserves the spatial context of makeup and provides a target semantic map for guiding the shape-independent style codes. Secondly, a region-adaptive normalization module that decouples shape and makeup style using per-region encoding and normalization, which facilitates the elimination of spatial misalignments. Lastly, a makeup fusion module blends identity features and makeup style by injecting learned scale and bias parameters. Experimental results show that our SARA method outperforms existing methods and achieves state-of-the-art performance on two public datasets.
MV-TON: Memory-based Video Virtual Try-on network
Aug 17, 2021
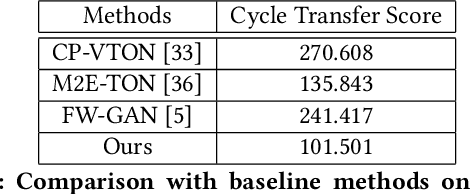
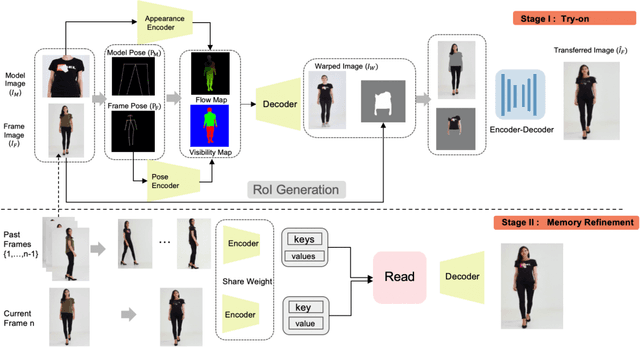
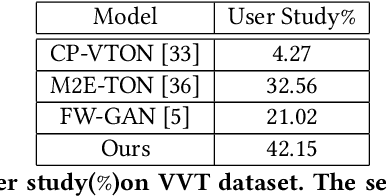
With the development of Generative Adversarial Network, image-based virtual try-on methods have made great progress. However, limited work has explored the task of video-based virtual try-on while it is important in real-world applications. Most existing video-based virtual try-on methods usually require clothing templates and they can only generate blurred and low-resolution results. To address these challenges, we propose a Memory-based Video virtual Try-On Network (MV-TON), which seamlessly transfers desired clothes to a target person without using any clothing templates and generates high-resolution realistic videos. Specifically, MV-TON consists of two modules: 1) a try-on module that transfers the desired clothes from model images to frame images by pose alignment and region-wise replacing of pixels; 2) a memory refinement module that learns to embed the existing generated frames into the latent space as external memory for the following frame generation. Experimental results show the effectiveness of our method in the video virtual try-on task and its superiority over other existing methods.