 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Semantic Collaborative Cropping for User Generated Content
Jan 16, 2024A large amount of User Generated Content (UGC) is uploaded to the Internet daily and displayed to people world-widely through the client side (e.g., mobile and PC). This requires the cropping algorithms to produce the aesthetic thumbnail within a specific aspect ratio on different devices. However, existing image cropping works mainly focus on landmark or landscape images, which fail to model the relations among the multi-objects with the complex background in UGC. Besides, previous methods merely consider the aesthetics of the cropped images while ignoring the content integrity, which is crucial for UGC cropping. In this paper, we propose a Spatial-Semantic Collaborative cropping network (S2CNet) for arbitrary user generated content accompanied by a new cropping benchmark. Specifically, we first mine the visual genes of the potential objects. Then, the suggested adaptive attention graph recasts this task as a procedure of information association over visual nodes. The underlying spatial and semantic relations are ultimately centralized to the crop candidate through differentiable message passing, which helps our network efficiently to preserve both the aesthetics and the content integrity. Extensive experiments on the proposed UGCrop5K and other public datasets demonstrate the superiority of our approach over state-of-the-art counterparts. Our project is available at https://github.com/suyukun666/S2CNet.
Dual-Augmented Transformer Network for Weakly Supervised Semantic Segmentation
Sep 30, 2023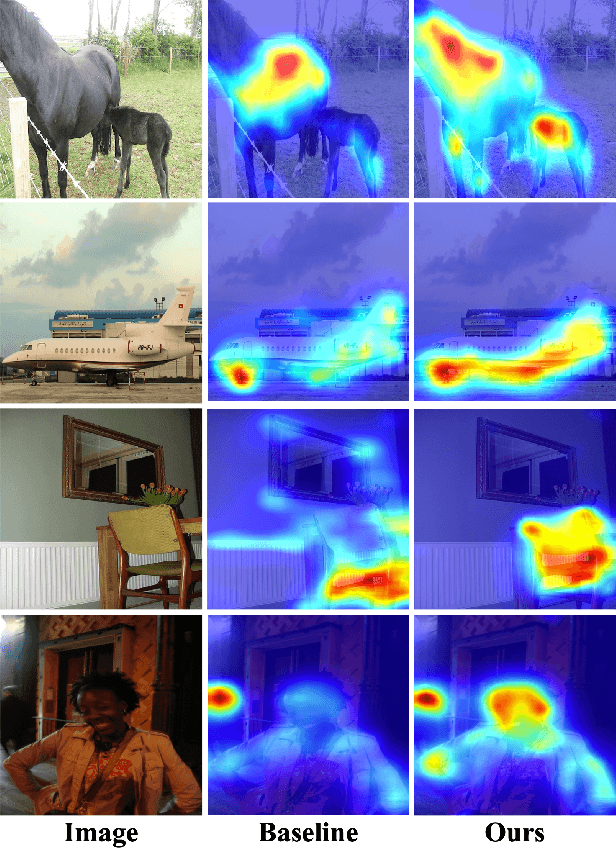
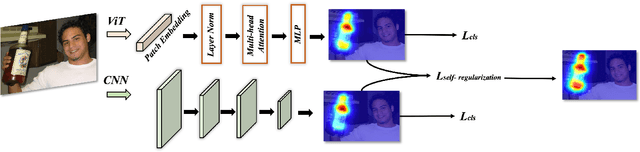

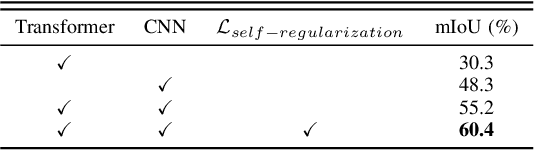
Weakly supervised semantic segmentation (WSSS), a fundamental computer vision task, which aims to segment out the object within only class-level labels. The traditional methods adopt the CNN-based network and utilize the class activation map (CAM) strategy to discover the object regions. However, such methods only focus on the most discriminative region of the object, resulting in incomplete segmentation. An alternative is to explore vision transformers (ViT) to encode the image to acquire the global semantic information. Yet, the lack of transductive bias to objects is a flaw of ViT. In this paper, we explore the dual-augmented transformer network with self-regularization constraints for WSSS. Specifically, we propose a dual network with both CNN-based and transformer networks for mutually complementary learning, where both networks augment the final output for enhancement. Massive systemic evaluations on the challenging PASCAL VOC 2012 benchmark demonstrate the effectiveness of our method, outperforming previous state-of-the-art methods.
COMNet: Co-Occurrent Matching for Weakly Supervised Semantic Segmentation
Sep 29, 2023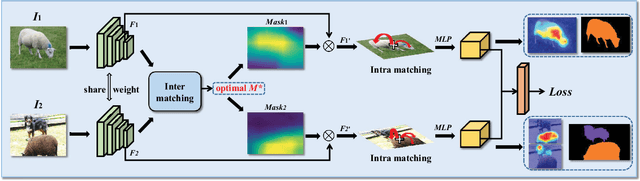
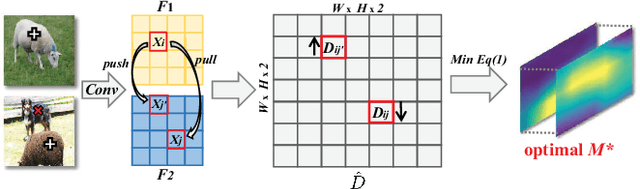
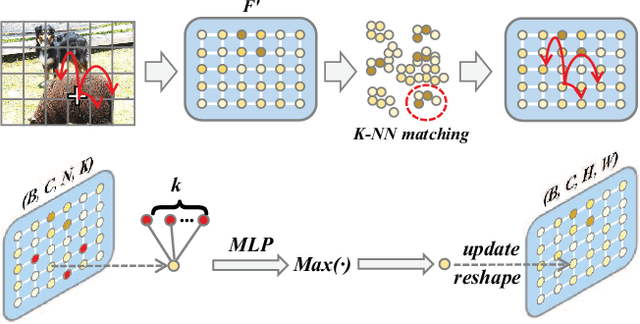
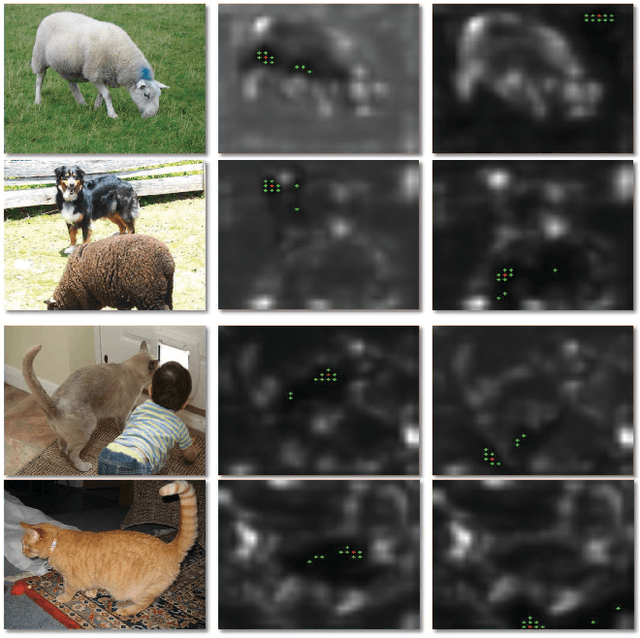
Image-level weakly supervised semantic segmentation is a challenging task that has been deeply studied in recent years. Most of the common solutions exploit class activation map (CAM) to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts. In this paper, we propose a novel Co-Occurrent Matching Network (COMNet), which can promote the quality of the CAMs and enforce the network to pay attention to the entire parts of objects. Specifically, we perform inter-matching on paired images that contain common classes to enhance the corresponded areas, and construct intra-matching on a single image to propagate the semantic features across the object regions. The experiments on the Pascal VOC 2012 and MS-COCO datasets show that our network can effectively boost the performance of the baseline model and achieve new state-of-the-art performance.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 11, 2022



Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.