 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Augmented Transformer Network for Weakly Supervised Semantic Segmentation
Paper and Code
Sep 30, 2023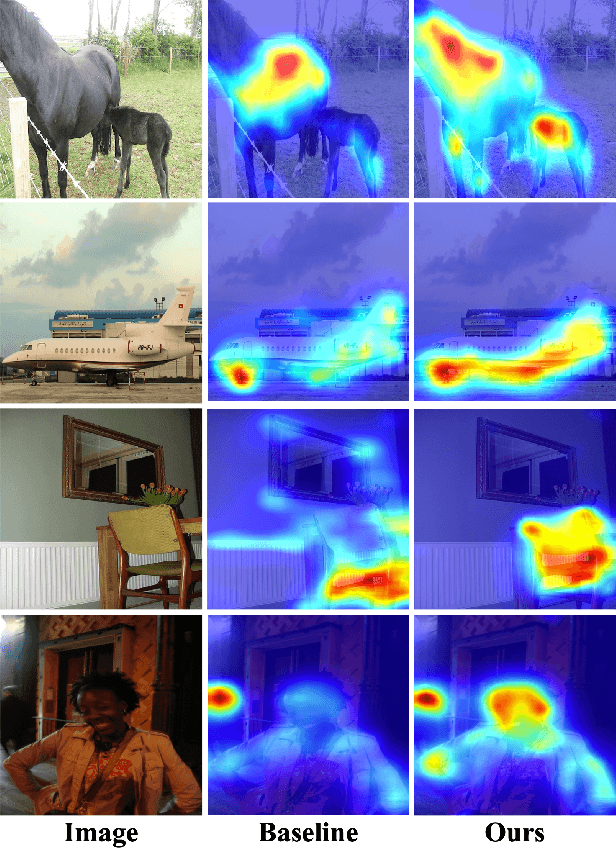
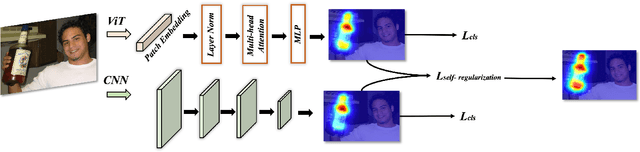

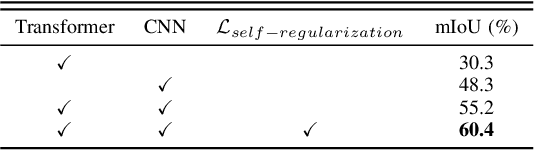
Weakly supervised semantic segmentation (WSSS), a fundamental computer vision task, which aims to segment out the object within only class-level labels. The traditional methods adopt the CNN-based network and utilize the class activation map (CAM) strategy to discover the object regions. However, such methods only focus on the most discriminative region of the object, resulting in incomplete segmentation. An alternative is to explore vision transformers (ViT) to encode the image to acquire the global semantic information. Yet, the lack of transductive bias to objects is a flaw of ViT. In this paper, we explore the dual-augmented transformer network with self-regularization constraints for WSSS. Specifically, we propose a dual network with both CNN-based and transformer networks for mutually complementary learning, where both networks augment the final output for enhancement. Massive systemic evaluations on the challenging PASCAL VOC 2012 benchmark demonstrate the effectiveness of our method, outperforming previous state-of-the-art methods.