 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingpath-VL Technical Report
Feb 12, 2026We present Singpath-VL, a vision-language large model, to fill the vacancy of AI assistant in cervical cytology. Recent advances in multi-modal large language models (MLLMs) have significantly propelled the field of computational pathology. However, their application in cytopathology, particularly cervical cytology, remains underexplored, primarily due to the scarcity of large-scale, high-quality annotated datasets. To bridge this gap, we first develop a novel three-stage pipeline to synthesize a million-scale image-description dataset. The pipeline leverages multiple general-purpose MLLMs as weak annotators, refines their outputs through consensus fusion and expert knowledge injection, and produces high-fidelity descriptions of cell morphology. Using this dataset, we then fine-tune the Qwen3-VL-4B model via a multi-stage strategy to create a specialized cytopathology MLLM. The resulting model, named Singpath-VL, demonstrates superior performance in fine-grained morphological perception and cell-level diagnostic classification. To advance the field, we will open-source a portion of the synthetic dataset and benchmark.
Bona fide Cross Testing Reveals Weak Spot in Audio Deepfake Detection Systems
Sep 11, 2025Audio deepfake detection (ADD) models are commonly evaluated using datasets that combine multiple synthesizers, with performance reported as a single Equal Error Rate (EER). However, this approach disproportionately weights synthesizers with more samples, underrepresenting others and reducing the overall reliability of EER. Additionally, most ADD datasets lack diversity in bona fide speech, often featuring a single environment and speech style (e.g., clean read speech), limiting their ability to simulate real-world conditions. To address these challenges, we propose bona fide cross-testing, a novel evaluation framework that incorporates diverse bona fide datasets and aggregates EERs for more balanced assessments. Our approach improves robustness and interpretability compared to traditional evaluation methods. We benchmark over 150 synthesizers across nine bona fide speech types and release a new dataset to facilitate further research at https://github.com/cyaaronk/audio_deepfake_eval.
MMP-2K: A Benchmark Multi-Labeled Macro Photography Image Quality Assessment Database
May 25, 2025Macro photography (MP) is a specialized field of photography that captures objects at an extremely close range, revealing tiny details. Although an accurate macro photography image quality assessment (MPIQA) metric can benefit macro photograph capturing, which is vital in some domains such as scientific research and medical applications, the lack of MPIQA data limits the development of MPIQA metrics. To address this limitation, we conducted a large-scale MPIQA study. Specifically, to ensure diversity both in content and quality, we sampled 2,000 MP images from 15,700 MP images, collected from three public image websites. For each MP image, 17 (out of 21 after outlier removal) quality ratings and a detailed quality report of distortion magnitudes, types, and positions are gathered by a lab study. The images, quality ratings, and quality reports form our novel multi-labeled MPIQA database, MMP-2k. Experimental results showed that the state-of-the-art generic IQA metrics underperform on MP images. The database and supplementary materials are available at https://github.com/Future-IQA/MMP-2k.
Multi-frequency Electrical Impedance Tomography Reconstruction with Multi-Branch Attention Image Prior
Sep 17, 2024


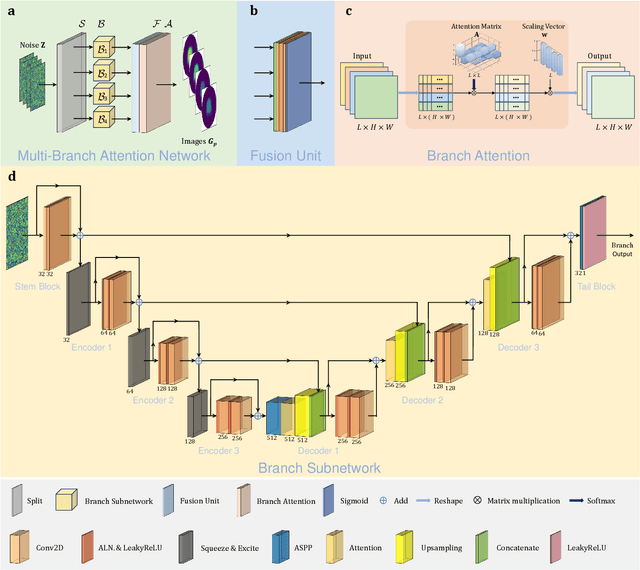
Multi-frequency Electrical Impedance Tomography (mfEIT) is a promising biomedical imaging technique that estimates tissue conductivities across different frequencies. Current state-of-the-art (SOTA) algorithms, which rely on supervised learning and Multiple Measurement Vectors (MMV), require extensive training data, making them time-consuming, costly, and less practical for widespread applications. Moreover, the dependency on training data in supervised MMV methods can introduce erroneous conductivity contrasts across frequencies, posing significant concerns in biomedical applications. To address these challenges, we propose a novel unsupervised learning approach based on Multi-Branch Attention Image Prior (MAIP) for mfEIT reconstruction. Our method employs a carefully designed Multi-Branch Attention Network (MBA-Net) to represent multiple frequency-dependent conductivity images and simultaneously reconstructs mfEIT images by iteratively updating its parameters. By leveraging the implicit regularization capability of the MBA-Net, our algorithm can capture significant inter- and intra-frequency correlations, enabling robust mfEIT reconstruction without the need for training data. Through simulation and real-world experiments, our approach demonstrates performance comparable to, or better than, SOTA algorithms while exhibiting superior generalization capability. These results suggest that the MAIP-based method can be used to improve the reliability and applicability of mfEIT in various settings.
Prototype-Driven Multi-Feature Generation for Visible-Infrared Person Re-identification
Sep 09, 2024



The primary challenges in visible-infrared person re-identification arise from the differences between visible (vis) and infrared (ir) images, including inter-modal and intra-modal variations. These challenges are further complicated by varying viewpoints and irregular movements. Existing methods often rely on horizontal partitioning to align part-level features, which can introduce inaccuracies and have limited effectiveness in reducing modality discrepancies. In this paper, we propose a novel Prototype-Driven Multi-feature generation framework (PDM) aimed at mitigating cross-modal discrepancies by constructing diversified features and mining latent semantically similar features for modal alignment. PDM comprises two key components: Multi-Feature Generation Module (MFGM) and Prototype Learning Module (PLM). The MFGM generates diversity features closely distributed from modality-shared features to represent pedestrians. Additionally, the PLM utilizes learnable prototypes to excavate latent semantic similarities among local features between visible and infrared modalities, thereby facilitating cross-modal instance-level alignment. We introduce the cosine heterogeneity loss to enhance prototype diversity for extracting rich local features. Extensive experiments conducted on the SYSU-MM01 and LLCM datasets demonstrate that our approach achieves state-of-the-art performance. Our codes are available at https://github.com/mmunhappy/ICASSP2025-PDM.
Imbalance-Agnostic Source-Free Domain Adaptation via Avatar Prototype Alignment
May 22, 2023



Source-free Unsupervised Domain Adaptation (SF-UDA) aims to adapt a well-trained source model to an unlabeled target domain without access to the source data. One key challenge is the lack of source data during domain adaptation. To handle this, we propose to mine the hidden knowledge of the source model and exploit it to generate source avatar prototypes. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. CPGA consists of two stages: Prototype generation and Prototype adaptation. Extensive experiments on three UDA benchmark datasets demonstrate the superiority of CPGA. However, existing SF.UDA studies implicitly assume balanced class distributions for both the source and target domains, which hinders their real applications. To address this issue, we study a more practical SF-UDA task, termed imbalance-agnostic SF-UDA, where the class distributions of both the unseen source domain and unlabeled target domain are unknown and could be arbitrarily skewed. This task is much more challenging than vanilla SF-UDA due to the co-occurrence of covariate shifts and unidentified class distribution shifts between the source and target domains. To address this task, we extend CPGA and propose a new Target-aware Contrastive Prototype Generation and Adaptation (T-CPGA) method. Specifically, for better prototype adaptation in the imbalance-agnostic scenario, T-CPGA applies a new pseudo label generation strategy to identify unknown target class distribution and generate accurate pseudo labels, by utilizing the collective intelligence of the source model and an additional contrastive language-image pre-trained model. Meanwhile, we further devise a target label-distribution-aware classifier to adapt the model to the unknown target class distribution. We empirically show that T-CPGA significantly outperforms CPGA and other SF-UDA methods in imbalance-agnostic SF-UDA.
Multi-Scale Multi-Target Domain Adaptation for Angle Closure Classification
Aug 25, 2022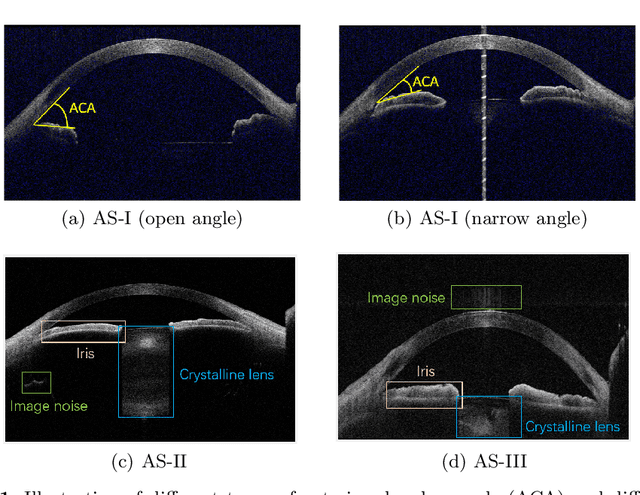
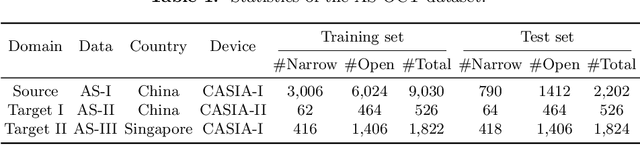
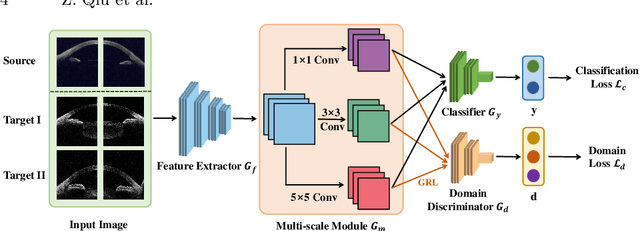
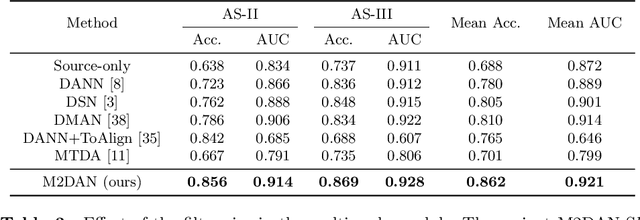
Deep learning (DL) has made significant progress in angle closure classification with anterior segment optical coherence tomography (AS-OCT) images. These AS-OCT images are often acquired by different imaging devices/conditions, which results in a vast change of underlying data distributions (called "data domains"). Moreover, due to practical labeling difficulties, some domains (e.g., devices) may not have any data labels. As a result, deep models trained on one specific domain (e.g., a specific device) are difficult to adapt to and thus may perform poorly on other domains (e.g., other devices). To address this issue, we present a multi-target domain adaptation paradigm to transfer a model trained on one labeled source domain to multiple unlabeled target domains. Specifically, we propose a novel Multi-scale Multi-target Domain Adversarial Network (M2DAN) for angle closure classification. M2DAN conducts multi-domain adversarial learning for extracting domain-invariant features and develops a multi-scale module for capturing local and global information of AS-OCT images. Based on these domain-invariant features at different scales, the deep model trained on the source domain is able to classify angle closure on multiple target domains even without any annotations in these domains. Extensive experiments on a real-world AS-OCT dataset demonstrate the effectiveness of the proposed method.
Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation
Jul 29, 2022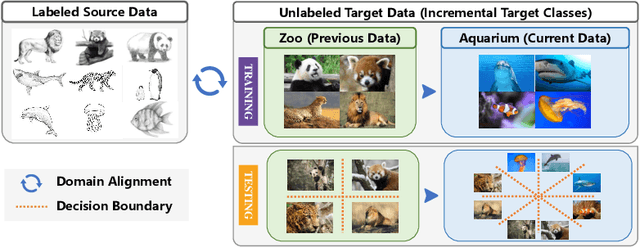

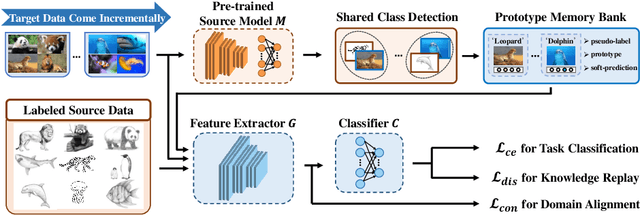

This paper studies a new, practical but challenging problem, called Class-Incremental Unsupervised Domain Adaptation (CI-UDA), where the labeled source domain contains all classes, but the classes in the unlabeled target domain increase sequentially. This problem is challenging due to two difficulties. First, source and target label sets are inconsistent at each time step, which makes it difficult to conduct accurate domain alignment. Second, previous target classes are unavailable in the current step, resulting in the forgetting of previous knowledge. To address this problem, we propose a novel Prototype-guided Continual Adaptation (ProCA) method, consisting of two solution strategies. 1) Label prototype identification: we identify target label prototypes by detecting shared classes with cumulative prediction probabilities of target samples. 2) Prototype-based alignment and replay: based on the identified label prototypes, we align both domains and enforce the model to retain previous knowledge. With these two strategies, ProCA is able to adapt the source model to a class-incremental unlabeled target domain effectively. Extensive experiments demonstrate the effectiveness and superiority of ProCA in resolving CI-UDA. The source code is available at https://github.com/Hongbin98/ProCA.git
Source-free Domain Adaptation via Avatar Prototype Generation and Adaptation
Jun 18, 2021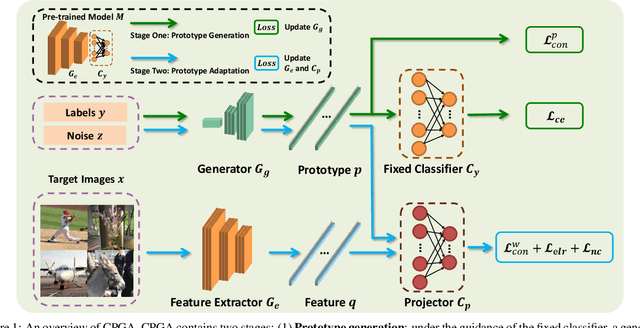
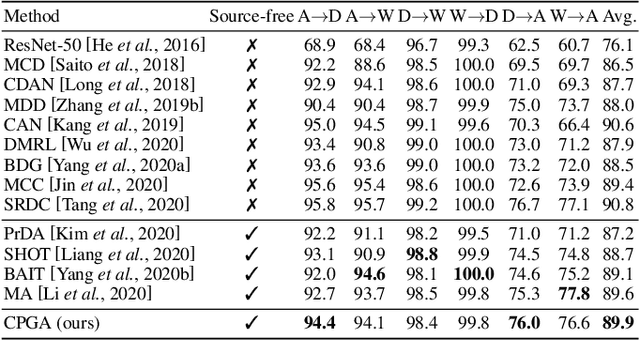
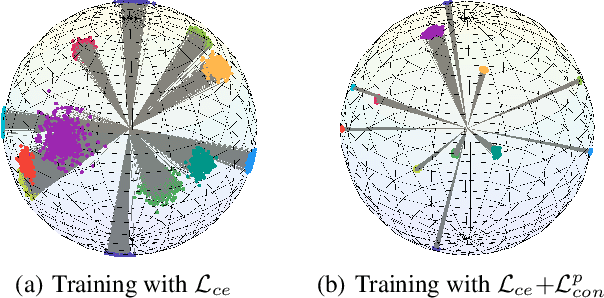
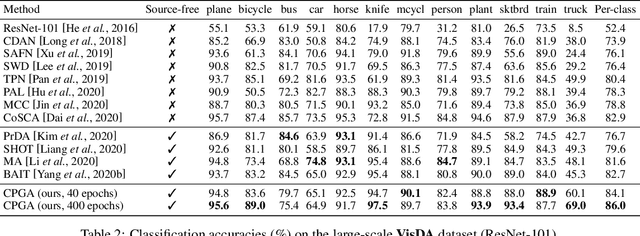
We study a practical domain adaptation task, called source-free unsupervised domain adaptation (UDA) problem, in which we cannot access source domain data due to data privacy issues but only a pre-trained source model and unlabeled target data are available. This task, however, is very difficult due to one key challenge: the lack of source data and target domain labels makes model adaptation very challenging. To address this, we propose to mine the hidden knowledge in the source model and exploit it to generate source avatar prototypes (i.e., representative features for each source class) as well as target pseudo labels for domain alignment. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. Specifically, CPGA consists of two stages: (1) prototype generation: by exploring the classification boundary information of the source model, we train a prototype generator to generate avatar prototypes via contrastive learning. (2) prototype adaptation: based on the generated source prototypes and target pseudo labels, we develop a new robust contrastive prototype adaptation strategy to align each pseudo-labeled target data to the corresponding source prototypes. Extensive experiments on three UDA benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
COVID-DA: Deep Domain Adaptation from Typical Pneumonia to COVID-19
Apr 30, 2020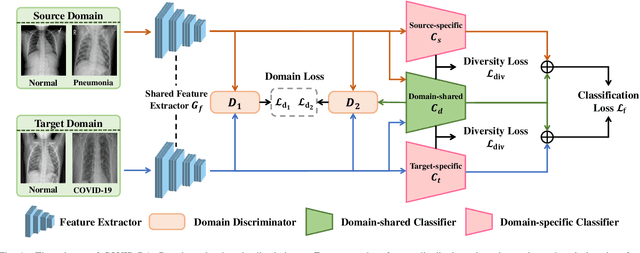
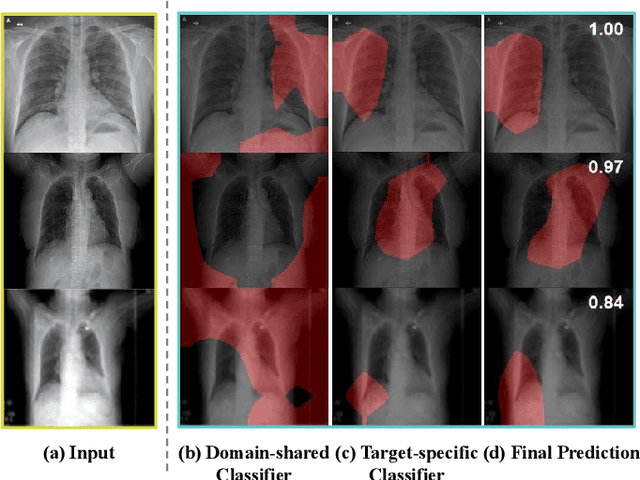
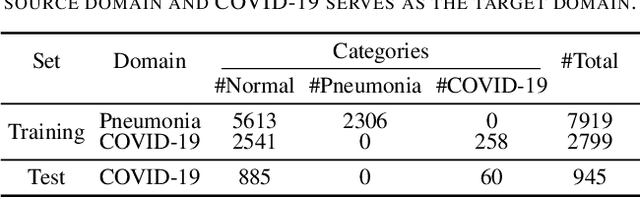
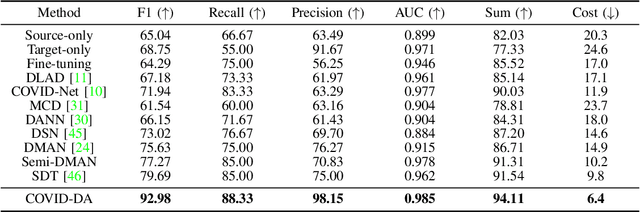
The outbreak of novel coronavirus disease 2019 (COVID-19) has already infected millions of people and is still rapidly spreading all over the globe. Most COVID-19 patients suffer from lung infection, so one important diagnostic method is to screen chest radiography images, e.g., X-Ray or CT images. However, such examinations are time-consuming and labor-intensive, leading to limited diagnostic efficiency. To solve this issue, AI-based technologies, such as deep learning, have been used recently as effective computer-aided means to improve diagnostic efficiency. However, one practical and critical difficulty is the limited availability of annotated COVID-19 data, due to the prohibitive annotation costs and urgent work of doctors to fight against the pandemic. This makes the learning of deep diagnosis models very challenging. To address this, motivated by that typical pneumonia has similar characteristics with COVID-19 and many pneumonia datasets are publicly available, we propose to conduct domain knowledge adaptation from typical pneumonia to COVID-19. There are two main challenges: 1) the discrepancy of data distributions between domains; 2) the task difference between the diagnosis of typical pneumonia and COVID-19. To address them, we propose a new deep domain adaptation method for COVID-19 diagnosis, namely COVID-DA. Specifically, we alleviate the domain discrepancy via feature adversarial adaptation and handle the task difference issue via a novel classifier separation scheme. In this way, COVID-DA is able to diagnose COVID-19 effectively with only a small number of COVID-19 annotations. Extensive experiments verify the effectiveness of COVID-DA and its great potential for real-world applications.