 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNav: A Benchmark for Human-Centered Collaborative Navigation
Jun 04, 2024Human-robot collaboration, in which the robot intelligently assists the human with the upcoming task, is an appealing objective. To achieve this goal, the agent needs to be equipped with a fundamental collaborative navigation ability, where the agent should reason human intention by observing human activities and then navigate to the human's intended destination in advance of the human. However, this vital ability has not been well studied in previous literature. To fill this gap, we propose a collaborative navigation (CoNav) benchmark. Our CoNav tackles the critical challenge of constructing a 3D navigation environment with realistic and diverse human activities. To achieve this, we design a novel LLM-based humanoid animation generation framework, which is conditioned on both text descriptions and environmental context. The generated humanoid trajectory obeys the environmental context and can be easily integrated into popular simulators. We empirically find that the existing navigation methods struggle in CoNav task since they neglect the perception of human intention. To solve this problem, we propose an intention-aware agent for reasoning both long-term and short-term human intention. The agent predicts navigation action based on the predicted intention and panoramic observation. The emergent agent behavior including observing humans, avoiding human collision, and navigation reveals the efficiency of the proposed datasets and agents.
Sharing, Teaching and Aligning: Knowledgeable Transfer Learning for Cross-Lingual Machine Reading Comprehension
Nov 12, 2023



In cross-lingual language understanding, machine translation is often utilized to enhance the transferability of models across languages, either by translating the training data from the source language to the target, or from the target to the source to aid inference. However, in cross-lingual machine reading comprehension (MRC), it is difficult to perform a deep level of assistance to enhance cross-lingual transfer because of the variation of answer span positions in different languages. In this paper, we propose X-STA, a new approach for cross-lingual MRC. Specifically, we leverage an attentive teacher to subtly transfer the answer spans of the source language to the answer output space of the target. A Gradient-Disentangled Knowledge Sharing technique is proposed as an improved cross-attention block. In addition, we force the model to learn semantic alignments from multiple granularities and calibrate the model outputs with teacher guidance to enhance cross-lingual transferability. Experiments on three multi-lingual MRC datasets show the effectiveness of our method, outperforming state-of-the-art approaches.
BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis
Nov 12, 2023Recently, diffusion-based deep generative models (e.g., Stable Diffusion) have shown impressive results in text-to-image synthesis. However, current text-to-image models often require multiple passes of prompt engineering by humans in order to produce satisfactory results for real-world applications. We propose BeautifulPrompt, a deep generative model to produce high-quality prompts from very simple raw descriptions, which enables diffusion-based models to generate more beautiful images. In our work, we first fine-tuned the BeautifulPrompt model over low-quality and high-quality collecting prompt pairs. Then, to ensure that our generated prompts can generate more beautiful images, we further propose a Reinforcement Learning with Visual AI Feedback technique to fine-tune our model to maximize the reward values of the generated prompts, where the reward values are calculated based on the PickScore and the Aesthetic Scores. Our results demonstrate that learning from visual AI feedback promises the potential to improve the quality of generated prompts and images significantly. We further showcase the integration of BeautifulPrompt to a cloud-native AI platform to provide better text-to-image generation service in the cloud.
Learning Large-scale Network Embedding from Representative Subgraph
Dec 02, 2021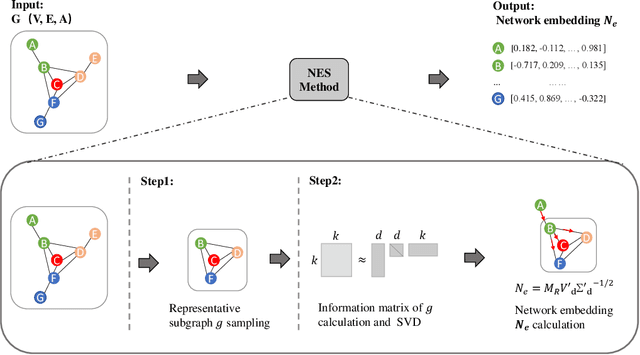
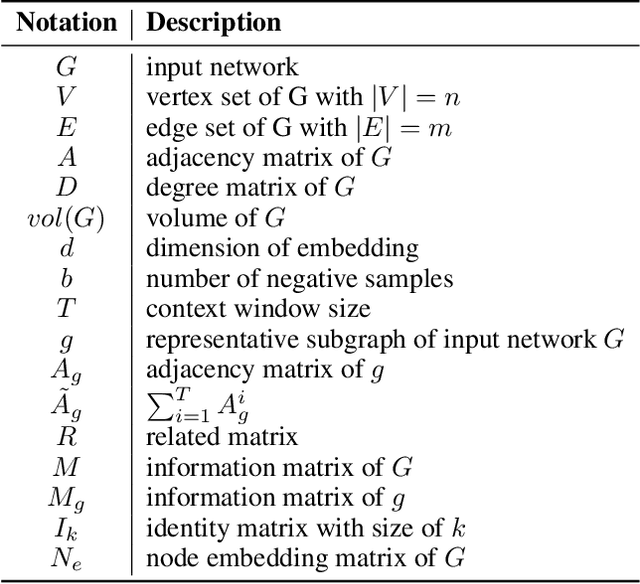
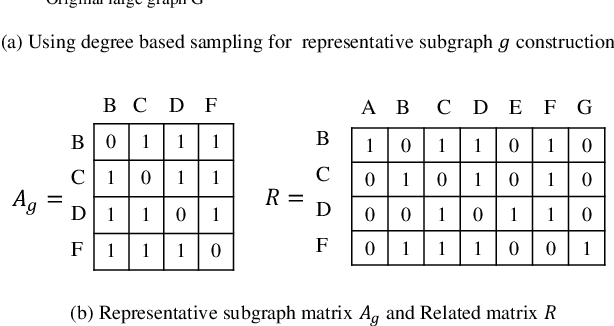
We study the problem of large-scale network embedding, which aims to learn low-dimensional latent representations for network mining applications. Recent research in the field of network embedding has led to significant progress such as DeepWalk, LINE, NetMF, NetSMF. However, the huge size of many real-world networks makes it computationally expensive to learn network embedding from the entire network. In this work, we present a novel network embedding method called "NES", which learns network embedding from a small representative subgraph. NES leverages theories from graph sampling to efficiently construct representative subgraph with smaller size which can be used to make inferences about the full network, enabling significantly improved efficiency in embedding learning. Then, NES computes the network embedding from this representative subgraph, efficiently. Compared with well-known methods, extensive experiments on networks of various scales and types demonstrate that NES achieves comparable performance and significant efficiency superiority.
Discrimination-aware Network Pruning for Deep Model Compression
Jan 04, 2020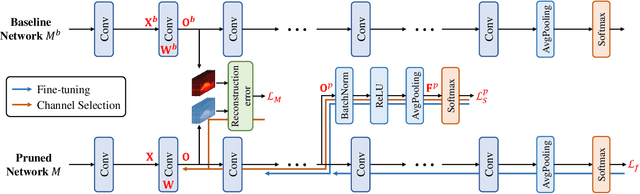

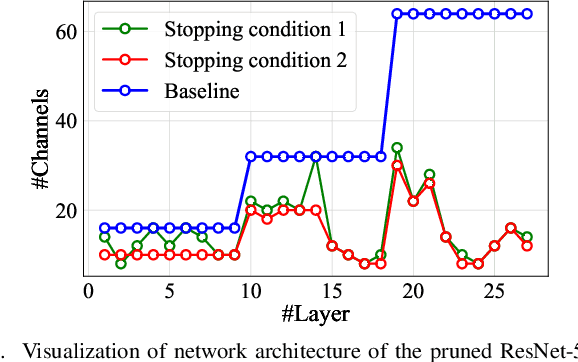

We study network pruning which aims to remove redundant channels/kernels and hence speed up the inference of deep networks. Existing pruning methods either train from scratch with sparsity constraints or minimize the reconstruction error between the feature maps of the pre-trained models and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, while the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. In this paper, we propose a simple-yet-effective method called discrimination-aware channel pruning (DCP) to choose the channels that actually contribute to the discriminative power. Note that a channel often consists of a set of kernels. Besides the redundancy in channels, some kernels in a channel may also be redundant and fail to contribute to the discriminative power of the network, resulting in kernel level redundancy. To solve this, we propose a discrimination-aware kernel pruning (DKP) method to further compress deep networks by removing redundant kernels. To prevent DCP/DKP from selecting redundant channels/kernels, we propose a new adaptive stopping condition, which helps to automatically determine the number of selected channels/kernels and often results in more compact models with better performance. Extensive experiments on both image classification and face recognition demonstrate the effectiveness of our methods. For example, on ILSVRC-12, the resultant ResNet-50 model with 30% reduction of channels even outperforms the baseline model by 0.36% in terms of Top-1 accuracy. The pruned MobileNetV1 and MobileNetV2 achieve 1.93x and 1.42x inference acceleration on a mobile device, respectively, with negligible performance degradation. The source code and the pre-trained models are available at https://github.com/SCUT-AILab/DCP.
Discrimination-aware Channel Pruning for Deep Neural Networks
Oct 30, 2018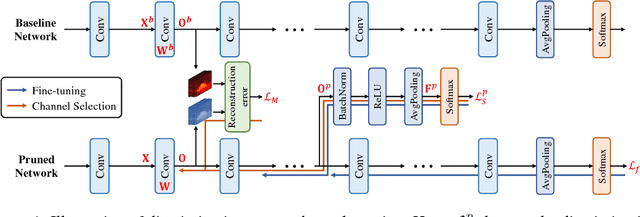
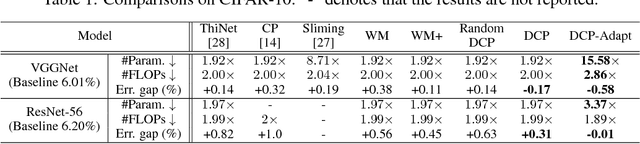
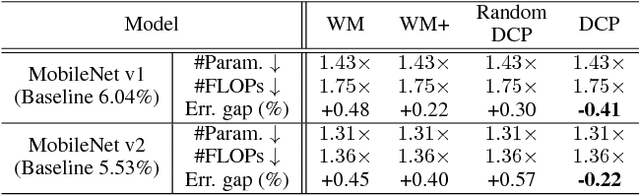

Channel pruning is one of the predominant approaches for deep model compression. Existing pruning methods either train from scratch with sparsity constraints on channels, or minimize the reconstruction error between the pre-trained feature maps and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, whilst the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. To overcome these drawbacks, we investigate a simple-yet-effective method, called discrimination-aware channel pruning, to choose those channels that really contribute to discriminative power. To this end, we introduce additional losses into the network to increase the discriminative power of intermediate layers and then select the most discriminative channels for each layer by considering the additional loss and the reconstruction error. Last, we propose a greedy algorithm to conduct channel selection and parameter optimization in an iterative way. Extensive experiments demonstrate the effectiveness of our method. For example, on ILSVRC-12, our pruned ResNet-50 with 30% reduction of channels even outperforms the original model by 0.39% in top-1 accuracy.