 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust 3D Semantic Occupancy Prediction with Calibration-free Spatial Transformation
Nov 19, 2024



3D semantic occupancy prediction, which seeks to provide accurate and comprehensive representations of environment scenes, is important to autonomous driving systems. For autonomous cars equipped with multi-camera and LiDAR, it is critical to aggregate multi-sensor information into a unified 3D space for accurate and robust predictions. Recent methods are mainly built on the 2D-to-3D transformation that relies on sensor calibration to project the 2D image information into the 3D space. These methods, however, suffer from two major limitations: First, they rely on accurate sensor calibration and are sensitive to the calibration noise, which limits their application in real complex environments. Second, the spatial transformation layers are computationally expensive and limit their running on an autonomous vehicle. In this work, we attempt to exploit a Robust and Efficient 3D semantic Occupancy (REO) prediction scheme. To this end, we propose a calibration-free spatial transformation based on vanilla attention to implicitly model the spatial correspondence. In this way, we robustly project the 2D features to a predefined BEV plane without using sensor calibration as input. Then, we introduce 2D and 3D auxiliary training tasks to enhance the discrimination power of 2D backbones on spatial, semantic, and texture features. Last, we propose a query-based prediction scheme to efficiently generate large-scale fine-grained occupancy predictions. By fusing point clouds that provide complementary spatial information, our REO surpasses the existing methods by a large margin on three benchmarks, including OpenOccupancy, Occ3D-nuScenes, and SemanticKITTI Scene Completion. For instance, our REO achieves 19.8$\times$ speedup compared to Co-Occ, with 1.1 improvements in geometry IoU on OpenOccupancy. Our code will be available at https://github.com/ICEORY/REO.
Contrastive Vision-Language Alignment Makes Efficient Instruction Learner
Nov 29, 2023We study the task of extending the large language model (LLM) into a vision-language instruction-following model. This task is crucial but challenging since the LLM is trained on text modality only, making it hard to effectively digest the visual modality. To address this, existing methods typically train a visual adapter to align the representation between a pre-trained vision transformer (ViT) and the LLM by a generative image captioning loss. However, we find that the generative objective can only produce weak alignment for vision and language, making the aligned vision-language model very hungry for the instruction fine-tuning data. In this paper, we propose CG-VLM that applies both Contrastive and Generative alignment objectives to effectively align the representation of ViT and LLM. Different from image level and sentence level alignment in common contrastive learning settings, CG-VLM aligns the image-patch level features and text-token level embeddings, which, however, is very hard to achieve as no explicit grounding patch-token relation provided in standard image captioning datasets. To address this issue, we propose to maximize the averaged similarity between pooled image-patch features and text-token embeddings. Extensive experiments demonstrate that the proposed CG-VLM produces strong vision-language alignment and is an efficient instruction learner. For example, using only 10% instruction tuning data, we reach 95% performance of state-of-the-art method LLaVA [29] on the zero-shot ScienceQA-Image benchmark.
CPCM: Contextual Point Cloud Modeling for Weakly-supervised Point Cloud Semantic Segmentation
Jul 19, 2023



We study the task of weakly-supervised point cloud semantic segmentation with sparse annotations (e.g., less than 0.1% points are labeled), aiming to reduce the expensive cost of dense annotations. Unfortunately, with extremely sparse annotated points, it is very difficult to extract both contextual and object information for scene understanding such as semantic segmentation. Motivated by masked modeling (e.g., MAE) in image and video representation learning, we seek to endow the power of masked modeling to learn contextual information from sparsely-annotated points. However, directly applying MAE to 3D point clouds with sparse annotations may fail to work. First, it is nontrivial to effectively mask out the informative visual context from 3D point clouds. Second, how to fully exploit the sparse annotations for context modeling remains an open question. In this paper, we propose a simple yet effective Contextual Point Cloud Modeling (CPCM) method that consists of two parts: a region-wise masking (RegionMask) strategy and a contextual masked training (CMT) method. Specifically, RegionMask masks the point cloud continuously in geometric space to construct a meaningful masked prediction task for subsequent context learning. CMT disentangles the learning of supervised segmentation and unsupervised masked context prediction for effectively learning the very limited labeled points and mass unlabeled points, respectively. Extensive experiments on the widely-tested ScanNet V2 and S3DIS benchmarks demonstrate the superiority of CPCM over the state-of-the-art.
DAS: Densely-Anchored Sampling for Deep Metric Learning
Jul 30, 2022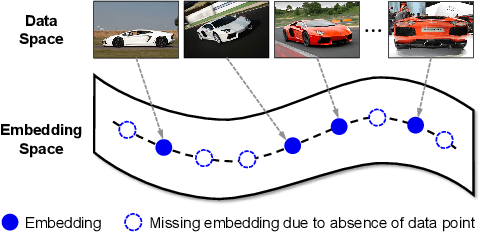

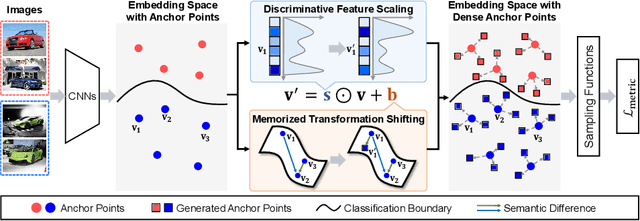
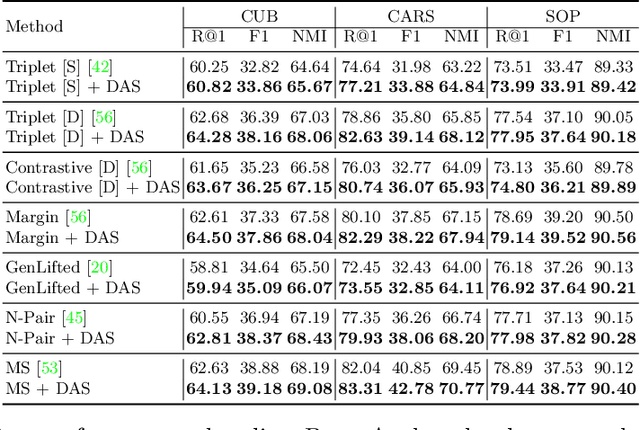
Deep Metric Learning (DML) serves to learn an embedding function to project semantically similar data into nearby embedding space and plays a vital role in many applications, such as image retrieval and face recognition. However, the performance of DML methods often highly depends on sampling methods to choose effective data from the embedding space in the training. In practice, the embeddings in the embedding space are obtained by some deep models, where the embedding space is often with barren area due to the absence of training points, resulting in so called "missing embedding" issue. This issue may impair the sample quality, which leads to degenerated DML performance. In this work, we investigate how to alleviate the "missing embedding" issue to improve the sampling quality and achieve effective DML. To this end, we propose a Densely-Anchored Sampling (DAS) scheme that considers the embedding with corresponding data point as "anchor" and exploits the anchor's nearby embedding space to densely produce embeddings without data points. Specifically, we propose to exploit the embedding space around single anchor with Discriminative Feature Scaling (DFS) and multiple anchors with Memorized Transformation Shifting (MTS). In this way, by combing the embeddings with and without data points, we are able to provide more embeddings to facilitate the sampling process thus boosting the performance of DML. Our method is effortlessly integrated into existing DML frameworks and improves them without bells and whistles. Extensive experiments on three benchmark datasets demonstrate the superiority of our method.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021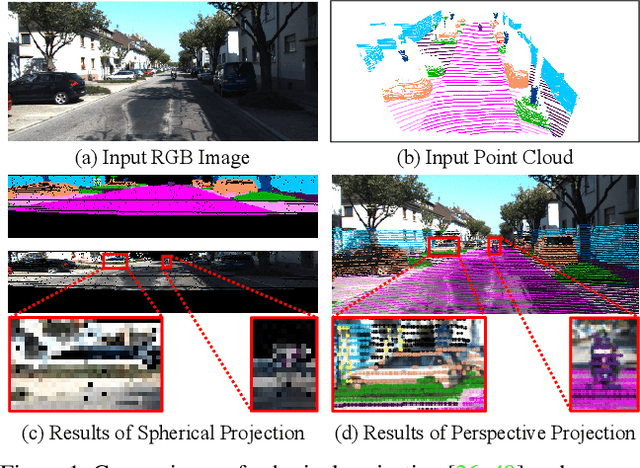
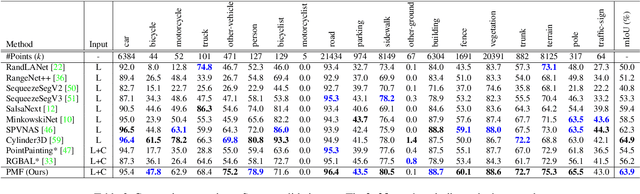
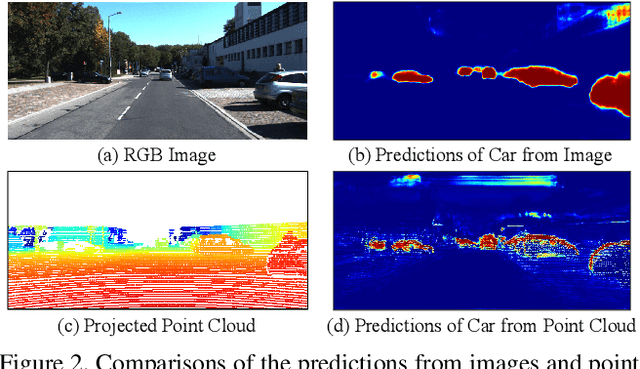
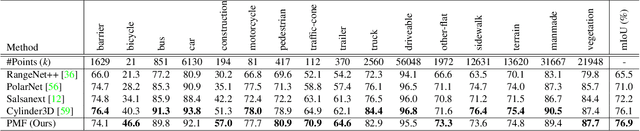
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.
Discrimination-aware Network Pruning for Deep Model Compression
Jan 04, 2020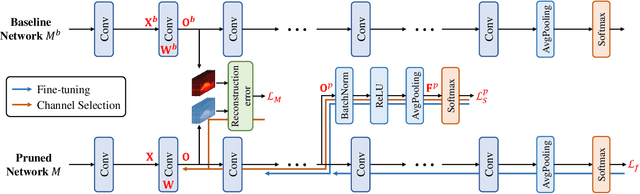

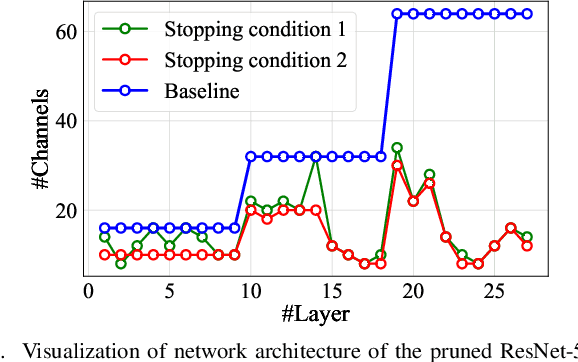

We study network pruning which aims to remove redundant channels/kernels and hence speed up the inference of deep networks. Existing pruning methods either train from scratch with sparsity constraints or minimize the reconstruction error between the feature maps of the pre-trained models and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, while the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. In this paper, we propose a simple-yet-effective method called discrimination-aware channel pruning (DCP) to choose the channels that actually contribute to the discriminative power. Note that a channel often consists of a set of kernels. Besides the redundancy in channels, some kernels in a channel may also be redundant and fail to contribute to the discriminative power of the network, resulting in kernel level redundancy. To solve this, we propose a discrimination-aware kernel pruning (DKP) method to further compress deep networks by removing redundant kernels. To prevent DCP/DKP from selecting redundant channels/kernels, we propose a new adaptive stopping condition, which helps to automatically determine the number of selected channels/kernels and often results in more compact models with better performance. Extensive experiments on both image classification and face recognition demonstrate the effectiveness of our methods. For example, on ILSVRC-12, the resultant ResNet-50 model with 30% reduction of channels even outperforms the baseline model by 0.36% in terms of Top-1 accuracy. The pruned MobileNetV1 and MobileNetV2 achieve 1.93x and 1.42x inference acceleration on a mobile device, respectively, with negligible performance degradation. The source code and the pre-trained models are available at https://github.com/SCUT-AILab/DCP.
Discrimination-aware Channel Pruning for Deep Neural Networks
Oct 30, 2018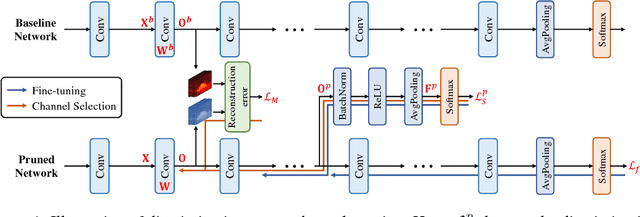
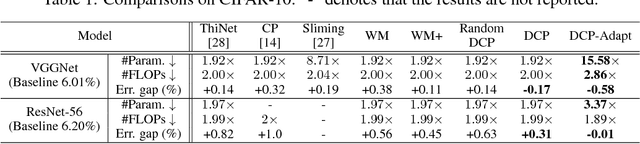
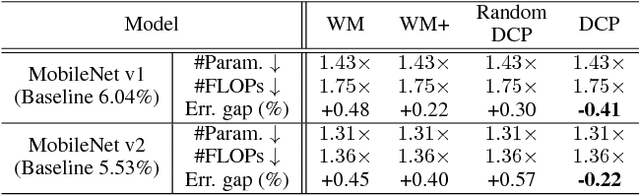

Channel pruning is one of the predominant approaches for deep model compression. Existing pruning methods either train from scratch with sparsity constraints on channels, or minimize the reconstruction error between the pre-trained feature maps and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, whilst the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. To overcome these drawbacks, we investigate a simple-yet-effective method, called discrimination-aware channel pruning, to choose those channels that really contribute to discriminative power. To this end, we introduce additional losses into the network to increase the discriminative power of intermediate layers and then select the most discriminative channels for each layer by considering the additional loss and the reconstruction error. Last, we propose a greedy algorithm to conduct channel selection and parameter optimization in an iterative way. Extensive experiments demonstrate the effectiveness of our method. For example, on ILSVRC-12, our pruned ResNet-50 with 30% reduction of channels even outperforms the original model by 0.39% in top-1 accuracy.