 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAS: Densely-Anchored Sampling for Deep Metric Learning
Paper and Code
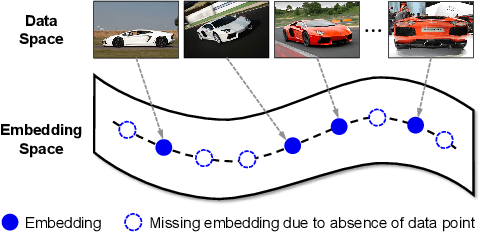

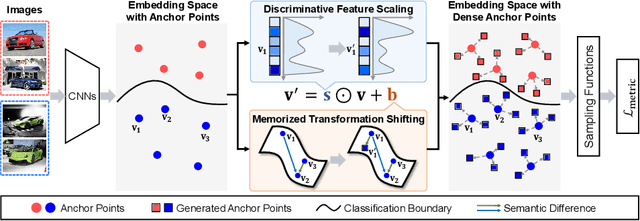
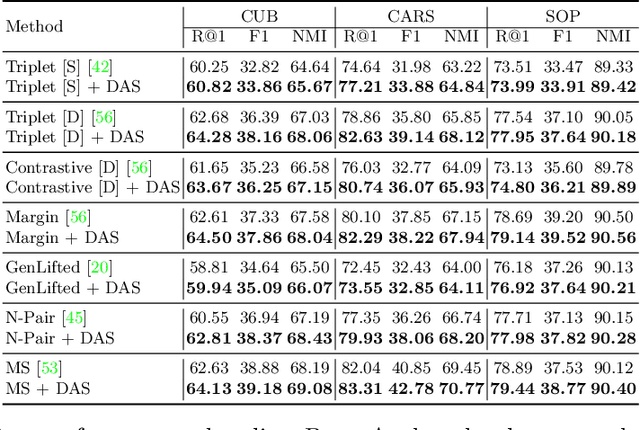
Deep Metric Learning (DML) serves to learn an embedding function to project semantically similar data into nearby embedding space and plays a vital role in many applications, such as image retrieval and face recognition. However, the performance of DML methods often highly depends on sampling methods to choose effective data from the embedding space in the training. In practice, the embeddings in the embedding space are obtained by some deep models, where the embedding space is often with barren area due to the absence of training points, resulting in so called "missing embedding" issue. This issue may impair the sample quality, which leads to degenerated DML performance. In this work, we investigate how to alleviate the "missing embedding" issue to improve the sampling quality and achieve effective DML. To this end, we propose a Densely-Anchored Sampling (DAS) scheme that considers the embedding with corresponding data point as "anchor" and exploits the anchor's nearby embedding space to densely produce embeddings without data points. Specifically, we propose to exploit the embedding space around single anchor with Discriminative Feature Scaling (DFS) and multiple anchors with Memorized Transformation Shifting (MTS). In this way, by combing the embeddings with and without data points, we are able to provide more embeddings to facilitate the sampling process thus boosting the performance of DML. Our method is effortlessly integrated into existing DML frameworks and improves them without bells and whistles. Extensive experiments on three benchmark datasets demonstrate the superiority of our method.