 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
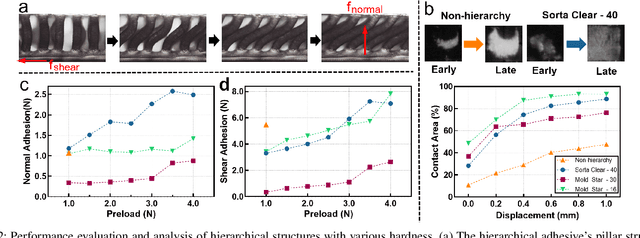
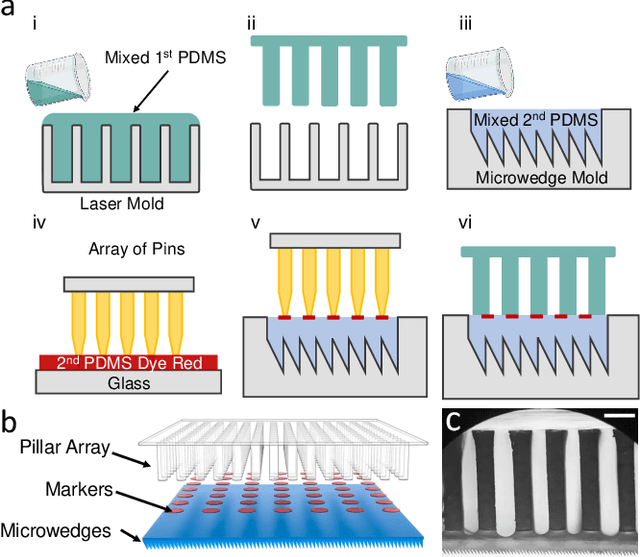

Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021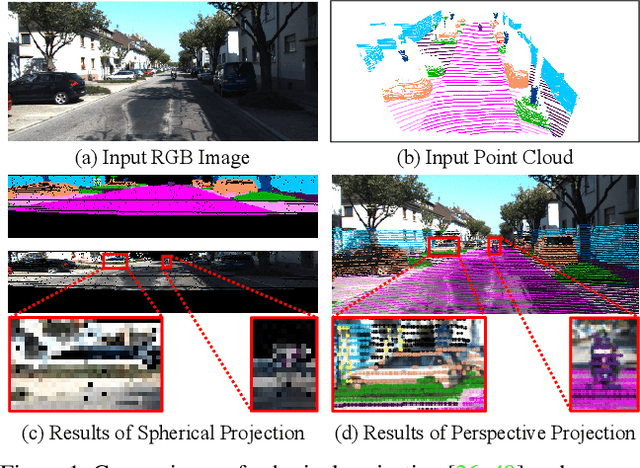
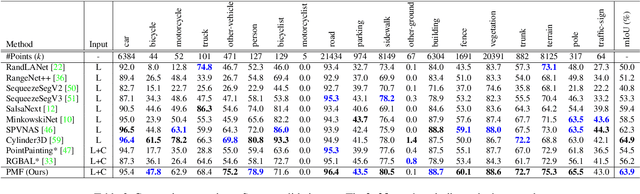
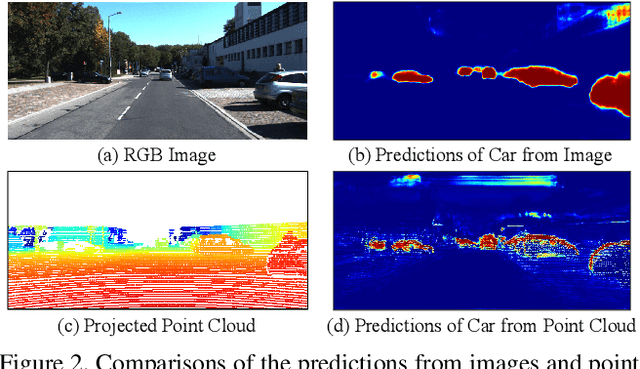
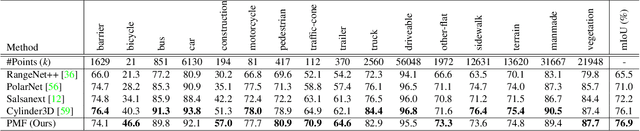
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.