 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task LLMs for Bug Classification: Efficient Inference with Auxiliary Decoding Heads
Jun 08, 2026The rapid adoption of LLM-powered code generation has dramatically accelerated software development, yet effective verification methods remain severely underdeveloped. Existing bug localization techniques are either prohibitively expensive, requiring minutes of agentic reasoning and thousands of generated tokens per file, and/or operate at coarse function-level granularity unsuitable for precise debugging. While works that focus on line-level granularity and are more light-weight are often limited in their performance or context size. We introduce a novel line-level bug localization approach that addresses these limitations through three key contributions: (1) a token alignment algorithm that overcomes fundamental tokenization challenges in previous work, (2) a lightweight multi-task LLM for bug localization (MLC) enabling efficient line-level bug classification, and (3) an optimized training recipe for multi-line prediction. Our method achieves state-of-the-art performance among similar setups on line-level bug localization with full-file context. At the same time we reach comparable performance to agentic approaches on Defects4J and PypiBugs benchmarks while reducing inference latency by orders of magnitudes, requiring only a single generated token per file. We further demonstrate strong generalization by introducing and evaluating on a small out-of-domain evaluation datasets in Python. We will open source our code, models, and datasets upon acceptance.
ThinkBooster: A Unified Framework for Seamless Test-Time Scaling of LLM Reasoning
Jun 05, 2026Test-time compute (TTC) scaling has emerged as a powerful paradigm for improving large language model (LLM) reasoning by allocating additional compute during inference, e.g., via multi-sample generation and verifier-based reranking. Existing TTC scaling strategies and reasoning scorers remain fragmented, evaluated under inconsistent protocols, and are rarely analyzed through the lens of quality-cost trade-offs. We introduce ThinkBooster, a unified framework for seamless test-time compute scaling of LLM reasoning, which consists of (i) a modular Python library implementing state-of-the-art TTC scaling strategy and scorer families, (ii) a benchmark that jointly evaluates performance and computational efficiency, and (iii) a deployable OpenAI-compatible proxy service that enables drop-in integration of adaptive reasoning into real-world applications. We further provide a demo visual debugger for inspecting the reasoning trajectories, intermediate selection decisions, and alternative reasoning paths. Empirical results on mathematical and coding tasks reveal the performance-compute trade-offs of TTC scaling strategies and scoring methods and demonstrate that ThinkBooster provides practical gains in real-world tasks. The code is available online under an MIT license.
Fine-tuning with RAG for Improving LLM Learning of New Skills
Oct 01, 2025Large language model (LLM) agents deployed for multi-step tasks frequently fail in predictable ways: attempting actions with unmet preconditions, issuing redundant commands, or mishandling environment constraints. While retrieval-augmented generation (RAG) can improve performance by providing runtime guidance, it requires maintaining external knowledge databases and adds computational overhead at every deployment. We propose a simple pipeline that converts inference-time retrieval into learned competence through distillation. Our approach: (1) extracts compact, reusable hints from agent failures, (2) uses these hints to generate improved teacher trajectories via one-shot retrieval at episode start, and (3) trains student models on these trajectories with hint strings removed, forcing internalization rather than memorization. Across two interactive benchmarks, ALFWorld (household tasks) and WebShop (online shopping), distilled students consistently outperform baseline agents, achieving up to 91% success on ALFWorld (vs. 79% for baselines) and improving WebShop scores to 72 (vs. 61 for baselines), while using 10-60% fewer tokens than retrieval-augmented teachers depending on the environment. The approach generalizes across model scales (7B/14B parameters) and agent architectures (ReAct/StateAct), demonstrating that retrieval benefits can be effectively internalized through targeted fine-tuning without permanent runtime dependencies.
IsoChronoMeter: A simple and effective isochronic translation evaluation metric
Oct 14, 2024Machine translation (MT) has come a long way and is readily employed in production systems to serve millions of users daily. With the recent advances in generative AI, a new form of translation is becoming possible - video dubbing. This work motivates the importance of isochronic translation, especially in the context of automatic dubbing, and introduces `IsoChronoMeter' (ICM). ICM is a simple yet effective metric to measure isochrony of translations in a scalable and resource-efficient way without the need for gold data, based on state-of-the-art text-to-speech (TTS) duration predictors. We motivate IsoChronoMeter and demonstrate its effectiveness. Using ICM we demonstrate the shortcomings of state-of-the-art translation systems and show the need for new methods. We release the code at this URL: \url{https://github.com/braskai/isochronometer}.
Efficient Exploration in Deep Reinforcement Learning: A Novel Bayesian Actor-Critic Algorithm
Aug 19, 2024Reinforcement learning (RL) and Deep Reinforcement Learning (DRL), in particular, have the potential to disrupt and are already changing the way we interact with the world. One of the key indicators of their applicability is their ability to scale and work in real-world scenarios, that is in large-scale problems. This scale can be achieved via a combination of factors, the algorithm's ability to make use of large amounts of data and computational resources and the efficient exploration of the environment for viable solutions (i.e. policies). In this work, we investigate and motivate some theoretical foundations for deep reinforcement learning. We start with exact dynamic programming and work our way up to stochastic approximations and stochastic approximations for a model-free scenario, which forms the theoretical basis of modern reinforcement learning. We present an overview of this highly varied and rapidly changing field from the perspective of Approximate Dynamic Programming. We then focus our study on the short-comings with respect to exploration of the cornerstone approaches (i.e. DQN, DDQN, A2C) in deep reinforcement learning. On the theory side, our main contribution is the proposal of a novel Bayesian actor-critic algorithm. On the empirical side, we evaluate Bayesian exploration as well as actor-critic algorithms on standard benchmarks as well as state-of-the-art evaluation suites and show the benefits of both of these approaches over current state-of-the-art deep RL methods. We release all the implementations and provide a full python library that is easy to install and hopefully will serve the reinforcement learning community in a meaningful way, and provide a strong foundation for future work.
Learning From Free-Text Human Feedback -- Collect New Datasets Or Extend Existing Ones?
Oct 24, 2023Learning from free-text human feedback is essential for dialog systems, but annotated data is scarce and usually covers only a small fraction of error types known in conversational AI. Instead of collecting and annotating new datasets from scratch, recent advances in synthetic dialog generation could be used to augment existing dialog datasets with the necessary annotations. However, to assess the feasibility of such an effort, it is important to know the types and frequency of free-text human feedback included in these datasets. In this work, we investigate this question for a variety of commonly used dialog datasets, including MultiWoZ, SGD, BABI, PersonaChat, Wizards-of-Wikipedia, and the human-bot split of the Self-Feeding Chatbot. Using our observations, we derive new taxonomies for the annotation of free-text human feedback in dialogs and investigate the impact of including such data in response generation for three SOTA language generation models, including GPT-2, LLAMA, and Flan-T5. Our findings provide new insights into the composition of the datasets examined, including error types, user response types, and the relations between them.
Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers
May 24, 2020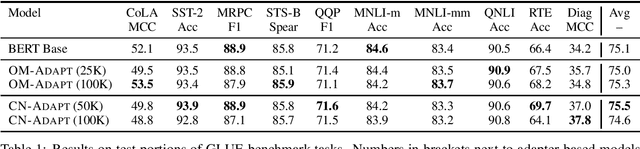
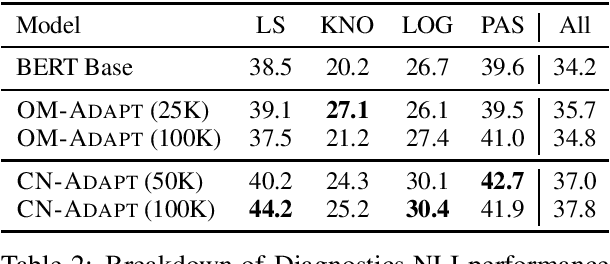
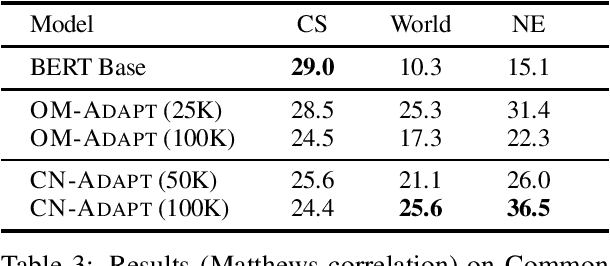
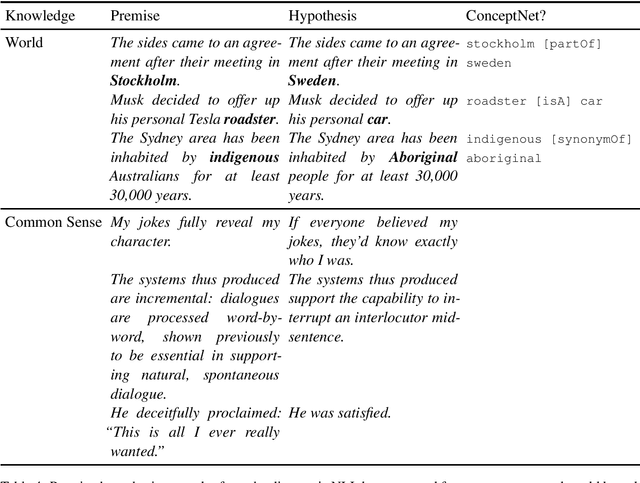
Following the major success of neural language models (LMs) such as BERT or GPT-2 on a variety of language understanding tasks, recent work focused on injecting (structured) knowledge from external resources into these models. While on the one hand, joint pretraining (i.e., training from scratch, adding objectives based on external knowledge to the primary LM objective) may be prohibitively computationally expensive, post-hoc fine-tuning on external knowledge, on the other hand, may lead to the catastrophic forgetting of distributional knowledge. In this work, we investigate models for complementing the distributional knowledge of BERT with conceptual knowledge from ConceptNet and its corresponding Open Mind Common Sense (OMCS) corpus, respectively, using adapter training. While overall results on the GLUE benchmark paint an inconclusive picture, a deeper analysis reveals that our adapter-based models substantially outperform BERT (up to 15-20 performance points) on inference tasks that require the type of conceptual knowledge explicitly present in ConceptNet and OMCS.
LIDA: Lightweight Interactive Dialogue Annotator
Nov 05, 2019
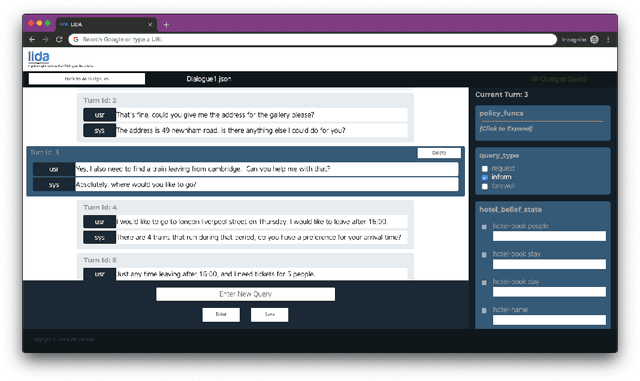
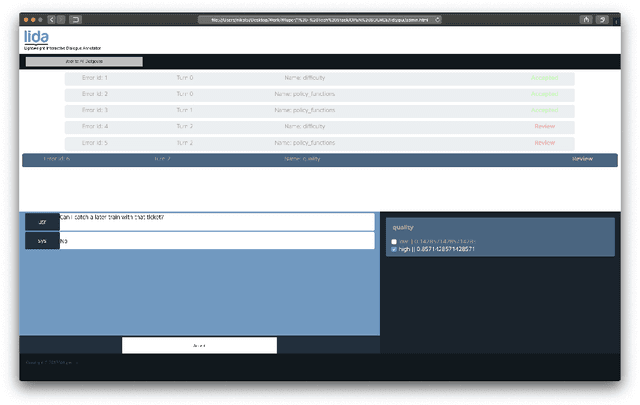
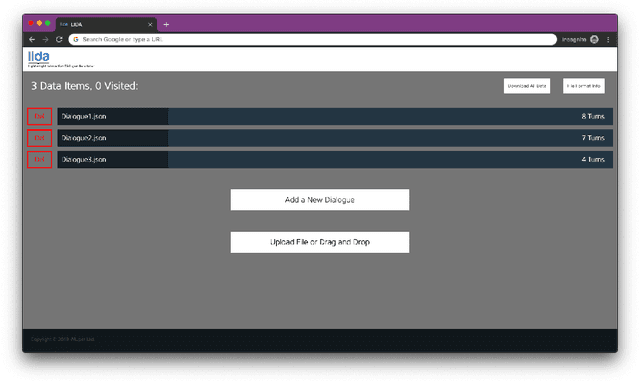
Dialogue systems have the potential to change how people interact with machines but are highly dependent on the quality of the data used to train them. It is therefore important to develop good dialogue annotation tools which can improve the speed and quality of dialogue data annotation. With this in mind, we introduce LIDA, an annotation tool designed specifically for conversation data. As far as we know, LIDA is the first dialogue annotation system that handles the entire dialogue annotation pipeline from raw text, as may be the output of transcription services, to structured conversation data. Furthermore it supports the integration of arbitrary machine learning models as annotation recommenders and also has a dedicated interface to resolve inter-annotator disagreements such as after crowdsourcing annotations for a dataset. LIDA is fully open source, documented and publicly available [ https://github.com/Wluper/lida ]
* 9 pages, 7 figures, 1 table, EMNLP 2019
Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks
Dec 07, 2018
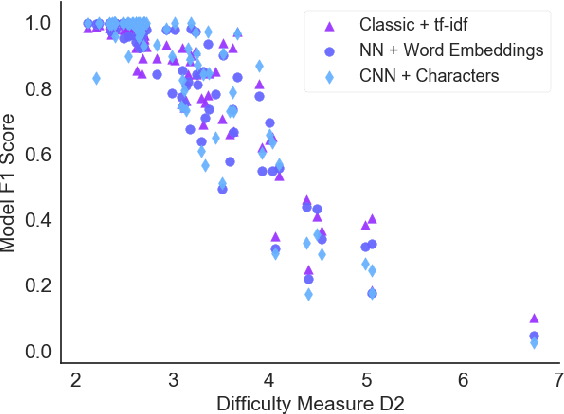

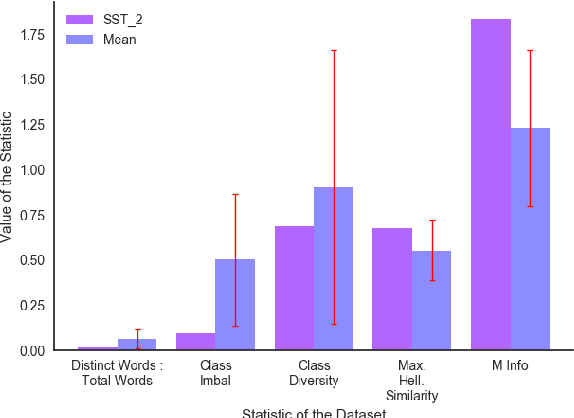
Classification tasks are usually analysed and improved through new model architectures or hyperparameter optimisation but the underlying properties of datasets are discovered on an ad-hoc basis as errors occur. However, understanding the properties of the data is crucial in perfecting models. In this paper we analyse exactly which characteristics of a dataset best determine how difficult that dataset is for the task of text classification. We then propose an intuitive measure of difficulty for text classification datasets which is simple and fast to calculate. We show that this measure generalises to unseen data by comparing it to state-of-the-art datasets and results. This measure can be used to analyse the precise source of errors in a dataset and allows fast estimation of how difficult a dataset is to learn. We searched for this measure by training 12 classical and neural network based models on 78 real-world datasets, then use a genetic algorithm to discover the best measure of difficulty. Our difficulty-calculating code ( https://github.com/Wluper/edm ) and datasets ( http://data.wluper.com ) are publicly available.
* 27 pages, 6 tables, 3 figures (submitted for publication in June 2018), CoNLL 2018