 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDA: Lightweight Interactive Dialogue Annotator
Paper and Code

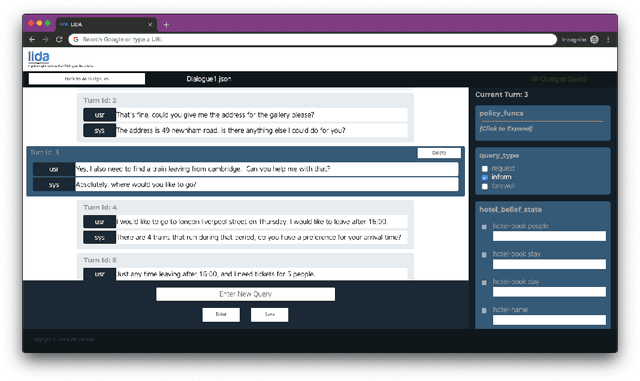
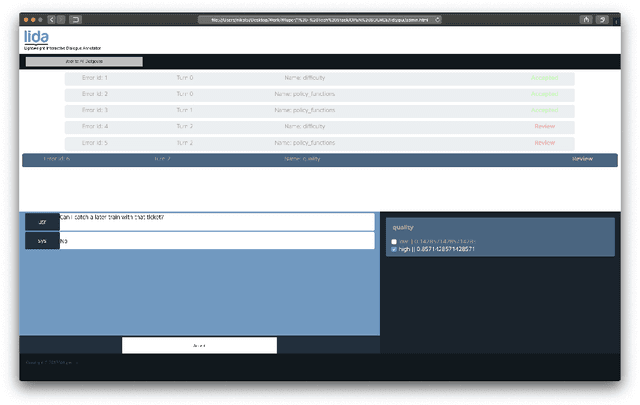
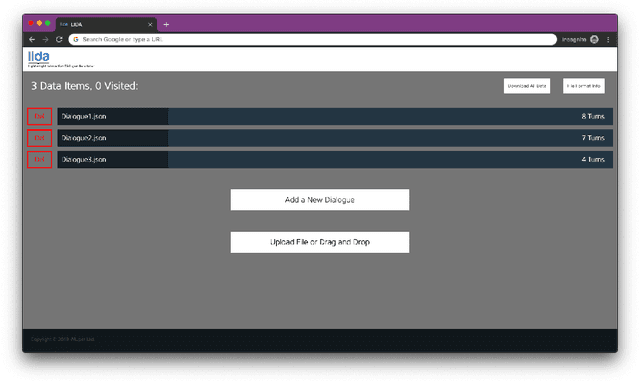
Dialogue systems have the potential to change how people interact with machines but are highly dependent on the quality of the data used to train them. It is therefore important to develop good dialogue annotation tools which can improve the speed and quality of dialogue data annotation. With this in mind, we introduce LIDA, an annotation tool designed specifically for conversation data. As far as we know, LIDA is the first dialogue annotation system that handles the entire dialogue annotation pipeline from raw text, as may be the output of transcription services, to structured conversation data. Furthermore it supports the integration of arbitrary machine learning models as annotation recommenders and also has a dedicated interface to resolve inter-annotator disagreements such as after crowdsourcing annotations for a dataset. LIDA is fully open source, documented and publicly available [ https://github.com/Wluper/lida ]