 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
TCFormer: A 5M-Parameter Transformer with Density-Guided Aggregation for Weakly-Supervised Crowd Counting
Dec 21, 2025Crowd counting typically relies on labor-intensive point-level annotations and computationally intensive backbones, restricting its scalability and deployment in resource-constrained environments. To address these challenges, this paper proposes the TCFormer, a tiny, ultra-lightweight, weakly-supervised transformer-based crowd counting framework with only 5 million parameters that achieves competitive performance. Firstly, a powerful yet efficient vision transformer is adopted as the feature extractor, the global context-aware capabilities of which provides semantic meaningful crowd features with a minimal memory footprint. Secondly, to compensate for the lack of spatial supervision, we design a feature aggregation mechanism termed the Learnable Density-Weighted Averaging module. This module dynamically re-weights local tokens according to predicted density scores, enabling the network to adaptively modulate regional features based on their specific density characteristics without the need for additional annotations. Furthermore, this paper introduces a density-level classification loss, which discretizes crowd density into distinct grades, thereby regularizing the training process and enhancing the model's classification power across varying levels of crowd density. Therefore, although TCformer is trained under a weakly-supervised paradigm utilizing only image-level global counts, the joint optimization of count and density-level losses enables the framework to achieve high estimation accuracy. Extensive experiments on four benchmarks including ShanghaiTech A/B, UCF-QNRF, and NWPU datasets demonstrate that our approach strikes a superior trade-off between parameter efficiency and counting accuracy and can be a good solution for crowd counting tasks in edge devices.
VIMS: A Visual-Inertial-Magnetic-Sonar SLAM System in Underwater Environments
Jun 18, 2025
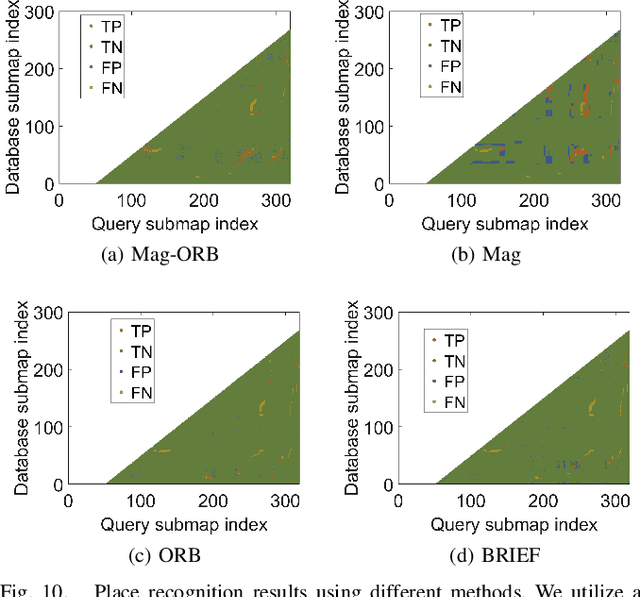
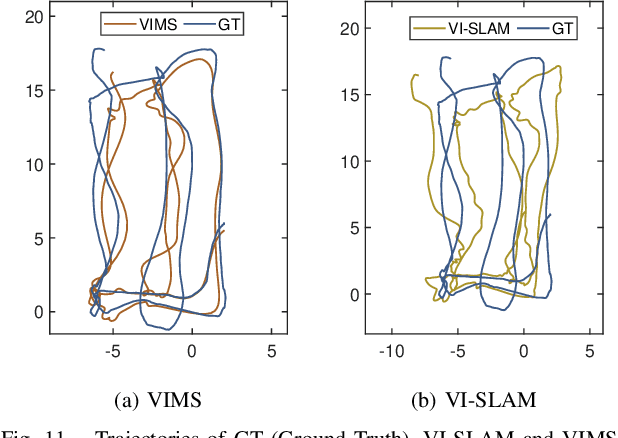
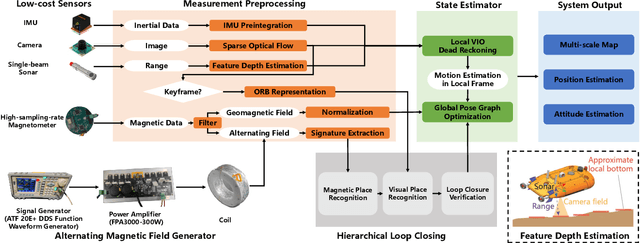
In this study, we present a novel simultaneous localization and mapping (SLAM) system, VIMS, designed for underwater navigation. Conventional visual-inertial state estimators encounter significant practical challenges in perceptually degraded underwater environments, particularly in scale estimation and loop closing. To address these issues, we first propose leveraging a low-cost single-beam sonar to improve scale estimation. Then, VIMS integrates a high-sampling-rate magnetometer for place recognition by utilizing magnetic signatures generated by an economical magnetic field coil. Building on this, a hierarchical scheme is developed for visual-magnetic place recognition, enabling robust loop closure. Furthermore, VIMS achieves a balance between local feature tracking and descriptor-based loop closing, avoiding additional computational burden on the front end. Experimental results highlight the efficacy of the proposed VIMS, demonstrating significant improvements in both the robustness and accuracy of state estimation within underwater environments.
"It Might be Technically Impressive, But It's Practically Useless to Us": Practices, Challenges, and Opportunities for Cross-Functional Collaboration around AI within the News Industry
Sep 18, 2024Recently, an increasing number of news organizations have integrated artificial intelligence (AI) into their workflows, leading to a further influx of AI technologists and data workers into the news industry. This has initiated cross-functional collaborations between these professionals and journalists. While prior research has explored the impact of AI-related roles entering the news industry, there is a lack of studies on how cross-functional collaboration unfolds between AI professionals and journalists. Through interviews with 17 journalists, 6 AI technologists, and 3 AI workers with cross-functional experience from leading news organizations, we investigate the current practices, challenges, and opportunities for cross-functional collaboration around AI in today's news industry. We first study how journalists and AI professionals perceive existing cross-collaboration strategies. We further explore the challenges of cross-functional collaboration and provide recommendations for enhancing future cross-functional collaboration around AI in the news industry.
PM2: A New Prompting Multi-modal Model Paradigm for Few-shot Medical Image Classification
Apr 13, 2024Few-shot learning has been successfully applied to medical image classification as only very few medical examples are available for training. Due to the challenging problem of limited number of annotated medical images, image representations should not be solely derived from a single image modality which is insufficient for characterizing concept classes. In this paper, we propose a new prompting multi-modal model paradigm on medical image classification based on multi-modal foundation models, called PM2. Besides image modality,PM2 introduces another supplementary text input, known as prompt, to further describe corresponding image or concept classes and facilitate few-shot learning across diverse modalities. To better explore the potential of prompt engineering, we empirically investigate five distinct prompt schemes under the new paradigm. Furthermore, linear probing in multi-modal models acts as a linear classification head taking as input only class token, which ignores completely merits of rich statistics inherent in high-level visual tokens. Thus, we alternatively perform a linear classification on feature distribution of visual tokens and class token simultaneously. To effectively mine such rich statistics, a global covariance pooling with efficient matrix power normalization is used to aggregate visual tokens. Then we study and combine two classification heads. One is shared for class token of image from vision encoder and prompt representation encoded by text encoder. The other is to classification on feature distribution of visual tokens from vision encoder. Extensive experiments on three medical datasets show that our PM2 significantly outperforms counterparts regardless of prompt schemes and achieves state-of-the-art performance.
Sensor Misalignment-tolerant AUV Navigation with Passive DoA and Doppler Measurements
Feb 11, 2024



We present a sensor misalignment-tolerant AUV navigation method that leverages measurements from an acoustic array and dead reckoned information. Recent studies have demonstrated the potential use of passive acoustic Direction of Arrival (DoA) measurements for AUV navigation without requiring ranging measurements. However, the sensor misalignment between the acoustic array and the attitude sensor was not accounted for. Such misalignment may deteriorate the navigation accuracy. This paper proposes a novel approach that allows simultaneous AUV navigation, beacon localization, and sensor alignment. An Unscented Kalman Filter (UKF) that enables the necessary calculations to be completed at an affordable computational load is developed. A Nonlinear Least Squares (NLS)-based technique is employed to find an initial solution for beacon localization and sensor alignment as early as possible using a short-term window of measurements. Experimental results demonstrate the performance of the proposed method.
Temporal-attentive Covariance Pooling Networks for Video Recognition
Nov 06, 2021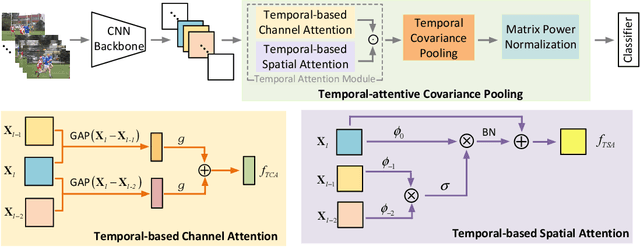

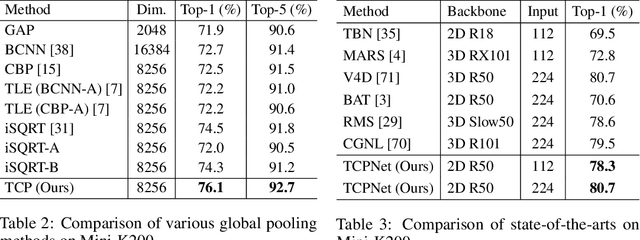
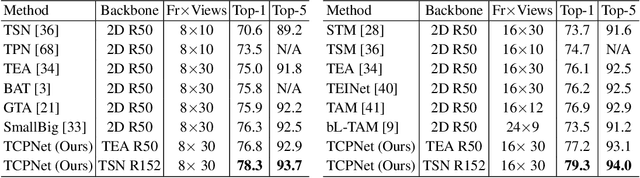
For video recognition task, a global representation summarizing the whole contents of the video snippets plays an important role for the final performance. However, existing video architectures usually generate it by using a simple, global average pooling (GAP) method, which has limited ability to capture complex dynamics of videos. For image recognition task, there exist evidences showing that covariance pooling has stronger representation ability than GAP. Unfortunately, such plain covariance pooling used in image recognition is an orderless representative, which cannot model spatio-temporal structure inherent in videos. Therefore, this paper proposes a Temporal-attentive Covariance Pooling(TCP), inserted at the end of deep architectures, to produce powerful video representations. Specifically, our TCP first develops a temporal attention module to adaptively calibrate spatio-temporal features for the succeeding covariance pooling, approximatively producing attentive covariance representations. Then, a temporal covariance pooling performs temporal pooling of the attentive covariance representations to characterize both intra-frame correlations and inter-frame cross-correlations of the calibrated features. As such, the proposed TCP can capture complex temporal dynamics. Finally, a fast matrix power normalization is introduced to exploit geometry of covariance representations. Note that our TCP is model-agnostic and can be flexibly integrated into any video architectures, resulting in TCPNet for effective video recognition. The extensive experiments on six benchmarks (e.g., Kinetics, Something-Something V1 and Charades) using various video architectures show our TCPNet is clearly superior to its counterparts, while having strong generalization ability. The source code is publicly available.
LIDA: Lightweight Interactive Dialogue Annotator
Nov 05, 2019
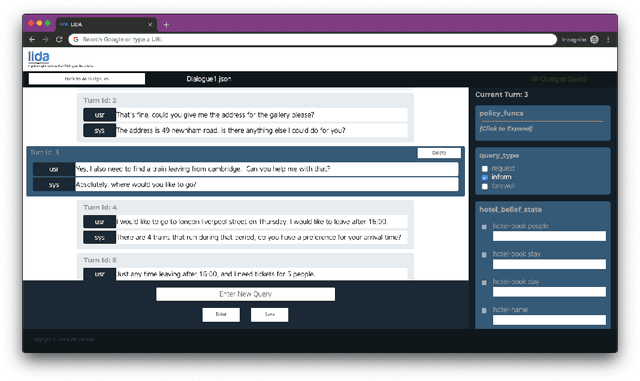
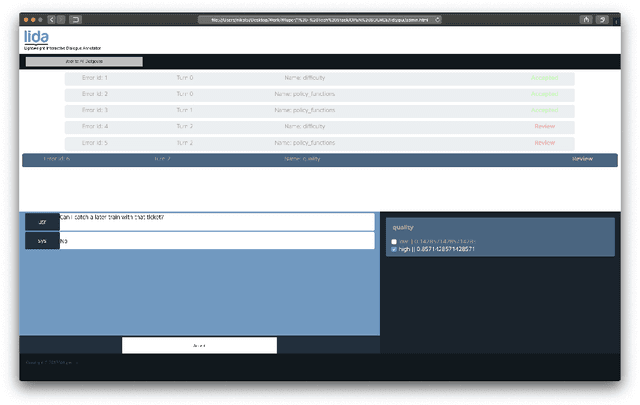
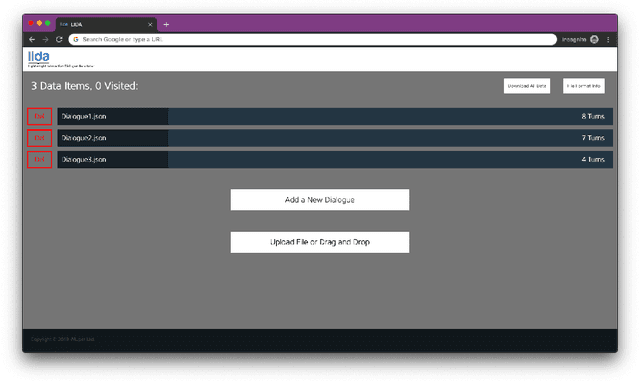
Dialogue systems have the potential to change how people interact with machines but are highly dependent on the quality of the data used to train them. It is therefore important to develop good dialogue annotation tools which can improve the speed and quality of dialogue data annotation. With this in mind, we introduce LIDA, an annotation tool designed specifically for conversation data. As far as we know, LIDA is the first dialogue annotation system that handles the entire dialogue annotation pipeline from raw text, as may be the output of transcription services, to structured conversation data. Furthermore it supports the integration of arbitrary machine learning models as annotation recommenders and also has a dedicated interface to resolve inter-annotator disagreements such as after crowdsourcing annotations for a dataset. LIDA is fully open source, documented and publicly available [ https://github.com/Wluper/lida ]
* 9 pages, 7 figures, 1 table, EMNLP 2019
Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks
Dec 07, 2018
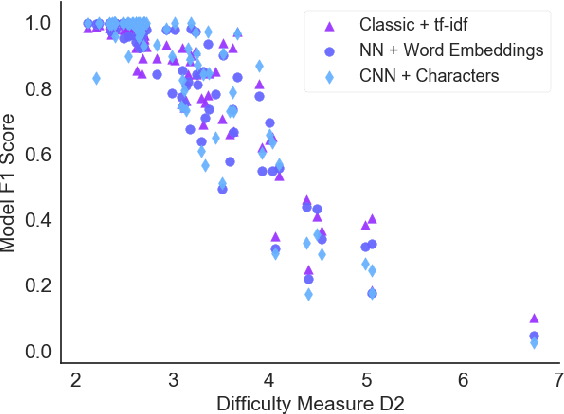

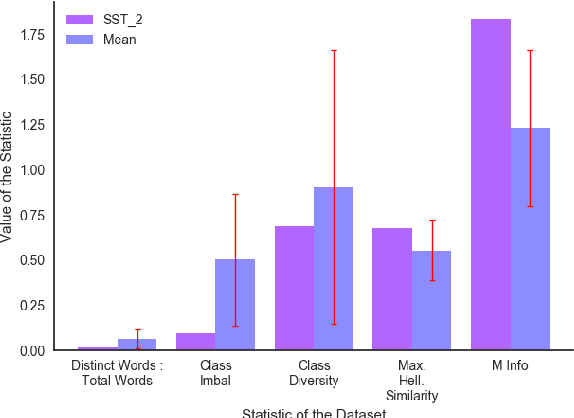
Classification tasks are usually analysed and improved through new model architectures or hyperparameter optimisation but the underlying properties of datasets are discovered on an ad-hoc basis as errors occur. However, understanding the properties of the data is crucial in perfecting models. In this paper we analyse exactly which characteristics of a dataset best determine how difficult that dataset is for the task of text classification. We then propose an intuitive measure of difficulty for text classification datasets which is simple and fast to calculate. We show that this measure generalises to unseen data by comparing it to state-of-the-art datasets and results. This measure can be used to analyse the precise source of errors in a dataset and allows fast estimation of how difficult a dataset is to learn. We searched for this measure by training 12 classical and neural network based models on 78 real-world datasets, then use a genetic algorithm to discover the best measure of difficulty. Our difficulty-calculating code ( https://github.com/Wluper/edm ) and datasets ( http://data.wluper.com ) are publicly available.
* 27 pages, 6 tables, 3 figures (submitted for publication in June 2018), CoNLL 2018