 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Curricula to Implicitly Train Non-Expert Annotators
Paper and Code
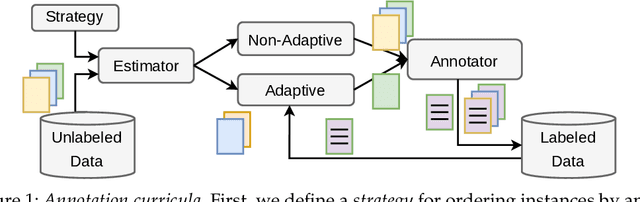

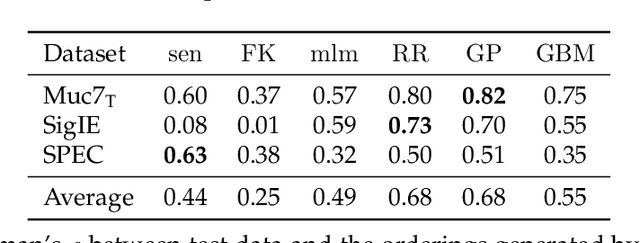
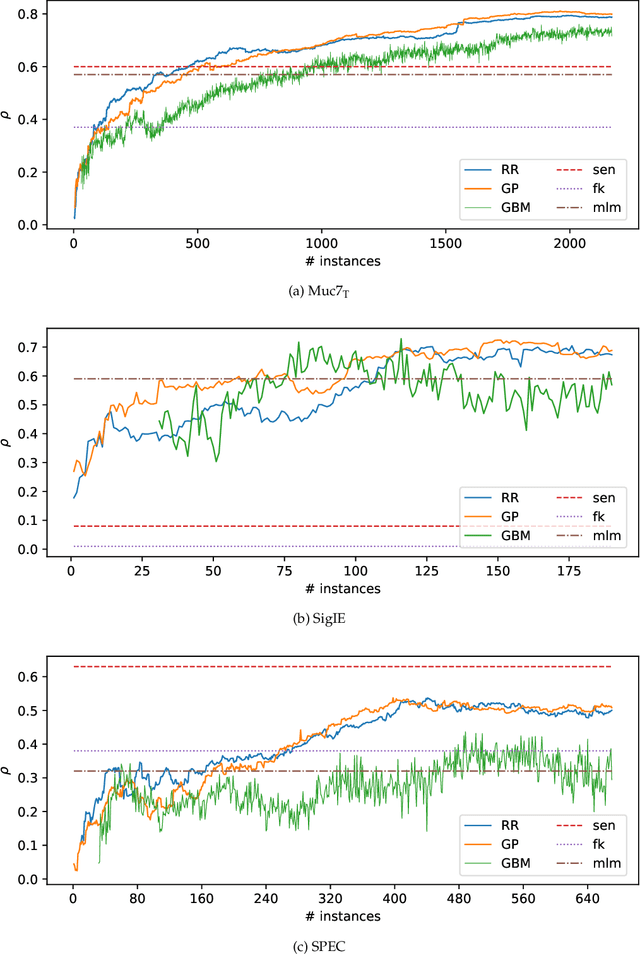
Annotation studies often require annotators to familiarize themselves with the task, its annotation scheme, and the data domain. This can be overwhelming in the beginning, mentally taxing, and induce errors into the resulting annotations; especially in citizen science or crowd sourcing scenarios where domain expertise is not required and only annotation guidelines are provided. To alleviate these issues, we propose annotation curricula, a novel approach to implicitly train annotators. Our goal is to gradually introduce annotators into the task by ordering instances that are annotated according to a learning curriculum. To do so, we first formalize annotation curricula for sentence- and paragraph-level annotation tasks, define an ordering strategy, and identify well-performing heuristics and interactively trained models on three existing English datasets. We then conduct a user study with 40 voluntary participants who are asked to identify the most fitting misconception for English tweets about the Covid-19 pandemic. Our results show that using a simple heuristic to order instances can already significantly reduce the total annotation time while preserving a high annotation quality. Annotation curricula thus can provide a novel way to improve data collection. To facilitate future research, we further share our code and data consisting of 2,400 annotations.