 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferAct: Inferring Safe Actions for LLM-Based Agents Through Preemptive Evaluation and Human Feedback
Jul 16, 2024



A crucial requirement for deploying LLM-based agents in real-life applications is robustness against risky or irreversible mistakes. However, existing research lacks a focus on the preemptive evaluation of reasoning trajectories performed by LLM agents, leading to a gap in ensuring safe and reliable operations. To explore better solutions, this paper introduces InferAct, a novel approach that leverages the Theory-of-Mind capability of LLMs to proactively detect potential errors before critical actions are executed (e.g., "buy-now" in automatic online trading or web shopping). InferAct is also capable of integrating human feedback to prevent irreversible risks and enhance the actor agent's decision-making process. Experiments on three widely used tasks demonstrate the effectiveness of InferAct. The proposed solution presents a novel approach and concrete contributions toward developing LLM agents that can be safely deployed in different environments involving critical decision-making.
DARA: Decomposition-Alignment-Reasoning Autonomous Language Agent for Question Answering over Knowledge Graphs
Jun 11, 2024



Answering Questions over Knowledge Graphs (KGQA) is key to well-functioning autonomous language agents in various real-life applications. To improve the neural-symbolic reasoning capabilities of language agents powered by Large Language Models (LLMs) in KGQA, we propose the DecompositionAlignment-Reasoning Agent (DARA) framework. DARA effectively parses questions into formal queries through a dual mechanism: high-level iterative task decomposition and low-level task grounding. Importantly, DARA can be efficiently trained with a small number of high-quality reasoning trajectories. Our experimental results demonstrate that DARA fine-tuned on LLMs (e.g. Llama-2-7B, Mistral) outperforms both in-context learning-based agents with GPT-4 and alternative fine-tuned agents, across different benchmarks in zero-shot evaluation, making such models more accessible for real-life applications. We also show that DARA attains performance comparable to state-of-the-art enumerating-and-ranking-based methods for KGQA.
UKP-SQuARE: An Interactive Tool for Teaching Question Answering
Jun 02, 2023



The exponential growth of question answering (QA) has made it an indispensable topic in any Natural Language Processing (NLP) course. Additionally, the breadth of QA derived from this exponential growth makes it an ideal scenario for teaching related NLP topics such as information retrieval, explainability, and adversarial attacks among others. In this paper, we introduce UKP-SQuARE as a platform for QA education. This platform provides an interactive environment where students can run, compare, and analyze various QA models from different perspectives, such as general behavior, explainability, and robustness. Therefore, students can get a first-hand experience in different QA techniques during the class. Thanks to this, we propose a learner-centered approach for QA education in which students proactively learn theoretical concepts and acquire problem-solving skills through interactive exploration, experimentation, and practical assignments, rather than solely relying on traditional lectures. To evaluate the effectiveness of UKP-SQuARE in teaching scenarios, we adopted it in a postgraduate NLP course and surveyed the students after the course. Their positive feedback shows the platform's effectiveness in their course and invites a wider adoption.
UKP-SQuARE v3: A Platform for Multi-Agent QA Research
Mar 31, 2023



The continuous development of Question Answering (QA) datasets has drawn the research community's attention toward multi-domain models. A popular approach is to use multi-dataset models, which are models trained on multiple datasets to learn their regularities and prevent overfitting to a single dataset. However, with the proliferation of QA models in online repositories such as GitHub or Hugging Face, an alternative is becoming viable. Recent works have demonstrated that combining expert agents can yield large performance gains over multi-dataset models. To ease research in multi-agent models, we extend UKP-SQuARE, an online platform for QA research, to support three families of multi-agent systems: i) agent selection, ii) early-fusion of agents, and iii) late-fusion of agents. We conduct experiments to evaluate their inference speed and discuss the performance vs. speed trade-off compared to multi-dataset models. UKP-SQuARE is open-source and publicly available at http://square.ukp-lab.de.
Transformers with Learnable Activation Functions
Sep 01, 2022
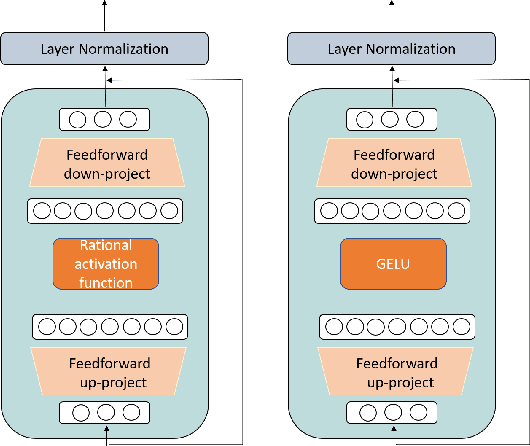

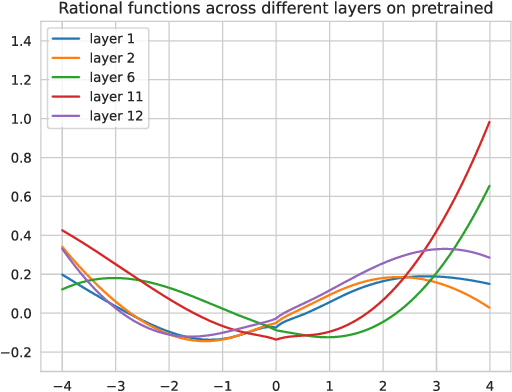
Activation functions can have a significant impact on reducing the topological complexity of input data and therefore improve the performance of the model. Selecting a suitable activation function is an essential step in neural model design. However, the choice of activation function is seldom discussed or explored in Transformer-based language models. Their activation functions are chosen beforehand and then remain fixed from pre-training to fine-tuning. As a result, the inductive biases they imposed on models cannot be adjusted during this long life cycle. Moreover, subsequently developed models (e.g., RoBERTa, BART, and GPT-3) often follow up prior work (e.g., BERT) to use the same activation function without justification. In this paper, we investigate the effectiveness of using Rational Activation Function (RAF), a learnable activation function, in the Transformer architecture. In contrast to conventional, predefined activation functions, RAFs can adaptively learn optimal activation functions during training according to input data. Our experiments show the RAF-based Transformer (RAFT) achieves a lower validation perplexity than a vanilla BERT with the GELU function. We further evaluate RAFT on downstream tasks in low- and full-data settings. Our results show that RAFT outperforms the counterpart model across the majority of tasks and settings. For instance, RAFT outperforms vanilla BERT on the GLUE benchmark by 5.71 points on average in low-data scenario (where 100 training examples are available) and by 2.05 points on SQuAD in full-data setting. Analysis of the shapes of learned RAFs further unveils that they substantially vary between different layers of the pre-trained model and mostly look very different from conventional activation functions. RAFT opens a new research direction for analyzing and interpreting pre-trained models according to the learned activation functions.