 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation
Aug 16, 2022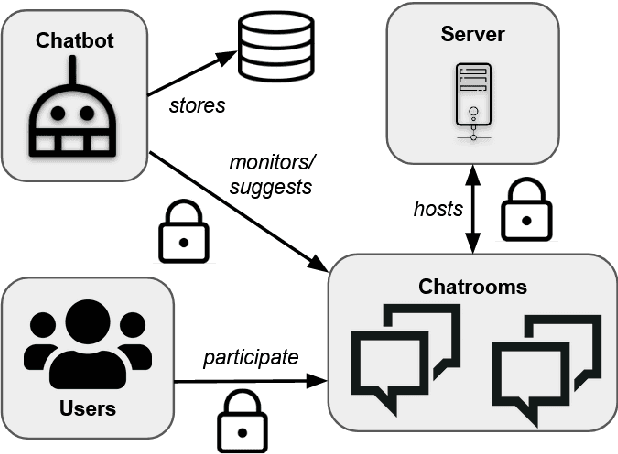
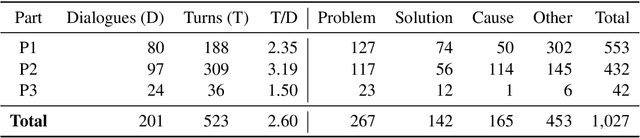
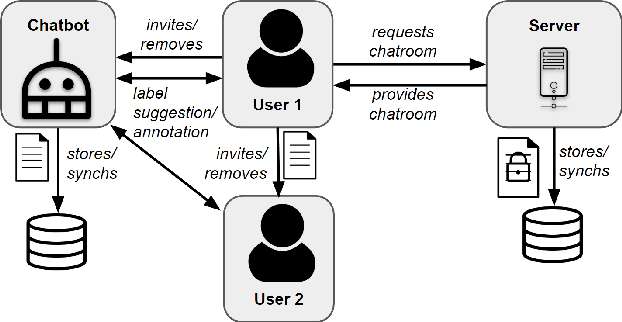
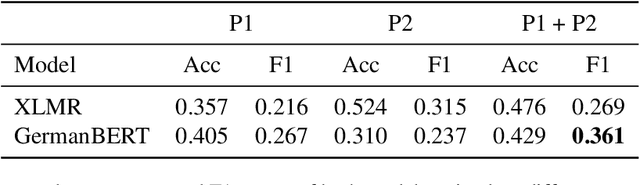
Collecting and annotating task-oriented dialog data is difficult, especially for highly specific domains that require expert knowledge. At the same time, informal communication channels such as instant messengers are increasingly being used at work. This has led to a lot of work-relevant information that is disseminated through those channels and needs to be post-processed manually by the employees. To alleviate this problem, we present TexPrax, a messaging system to collect and annotate problems, causes, and solutions that occur in work-related chats. TexPrax uses a chatbot to directly engage the employees to provide lightweight annotations on their conversation and ease their documentation work. To comply with data privacy and security regulations, we use an end-to-end message encryption and give our users full control over their data which has various advantages over conventional annotation tools. We evaluate TexPrax in a user-study with German factory employees who ask their colleagues for solutions on problems that arise during their daily work. Overall, we collect 201 task-oriented German dialogues containing 1,027 sentences with sentence-level expert annotations. Our data analysis also reveals that real-world conversations frequently contain instances with code-switching, varying abbreviations for the same entity, and dialects which NLP systems should be able to handle.
On The Reliability Of Machine Learning Applications In Manufacturing Environments
Dec 19, 2021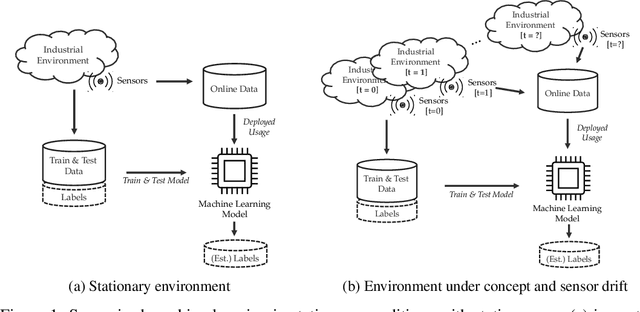
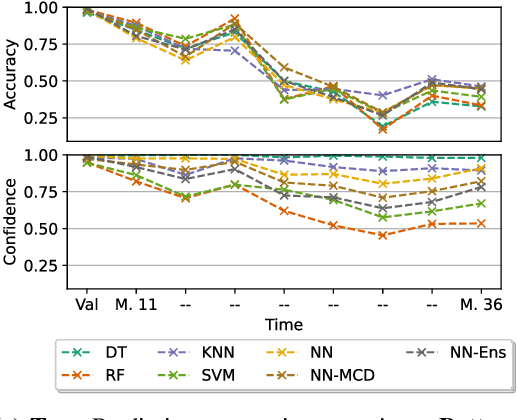
The increasing deployment of advanced digital technologies such as Internet of Things (IoT) devices and Cyber-Physical Systems (CPS) in industrial environments is enabling the productive use of machine learning (ML) algorithms in the manufacturing domain. As ML applications transcend from research to productive use in real-world industrial environments, the question of reliability arises. Since the majority of ML models are trained and evaluated on static datasets, continuous online monitoring of their performance is required to build reliable systems. Furthermore, concept and sensor drift can lead to degrading accuracy of the algorithm over time, thus compromising safety, acceptance and economics if undetected and not properly addressed. In this work, we exemplarily highlight the severity of the issue on a publicly available industrial dataset which was recorded over the course of 36 months and explain possible sources of drift. We assess the robustness of ML algorithms commonly used in manufacturing and show, that the accuracy strongly declines with increasing drift for all tested algorithms. We further investigate how uncertainty estimation may be leveraged for online performance estimation as well as drift detection as a first step towards continually learning applications. The results indicate, that ensemble algorithms like random forests show the least decay of confidence calibration under drift.