 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Conformal Learning for Heterogeneous Sensor Fusion
Feb 19, 2024Being able to assess the confidence of individual predictions in machine learning models is crucial for decision making scenarios. Specially, in critical applications such as medical diagnosis, security, and unmanned vehicles, to name a few. In the last years, complex predictive models have had great success in solving hard tasks and new methods are being proposed every day. While the majority of new developments in machine learning models focus on improving the overall performance, less effort is put on assessing the trustworthiness of individual predictions, and even to a lesser extent, in the context of sensor fusion. To this end, we build and test multi-view and single-view conformal models for heterogeneous sensor fusion. Our models provide theoretical marginal confidence guarantees since they are based on the conformal prediction framework. We also propose a multi-view semi-conformal model based on sets intersection. Through comprehensive experimentation, we show that multi-view models perform better than single-view models not only in terms of accuracy-based performance metrics (as it has already been shown in several previous works) but also in conformal measures that provide uncertainty estimation. Our results also showed that multi-view models generate prediction sets with less uncertainty compared to single-view models.
Conformal Prediction in Multi-User Settings: An Evaluation
Dec 08, 2023Typically, machine learning models are trained and evaluated without making any distinction between users (e.g, using traditional hold-out and cross-validation). However, this produces inaccurate performance metrics estimates in multi-user settings. That is, situations where the data were collected by multiple users with different characteristics (e.g., age, gender, height, etc.) which is very common in user computer interaction and medical applications. For these types of scenarios model evaluation strategies that provide better performance estimates have been proposed such as mixed, user-independent, user-dependent, and user-adaptive models. Although those strategies are better suited for multi-user systems, they are typically assessed with respect to performance metrics that capture the overall behavior of the models and do not provide any performance guarantees for individual predictions nor they provide any feedback about the predictions' uncertainty. In order to overcome those limitations, in this work we evaluated the conformal prediction framework in several multi-user settings. Conformal prediction is a model agnostic method that provides confidence guarantees on the predictions, thus, increasing the trustworthiness and robustness of the models. We conducted extensive experiments using different evaluation strategies and found significant differences in terms of conformal performance measures. We also proposed several visualizations based on matrices, graphs, and charts that capture different aspects of the resulting prediction sets.
On The Reliability Of Machine Learning Applications In Manufacturing Environments
Dec 19, 2021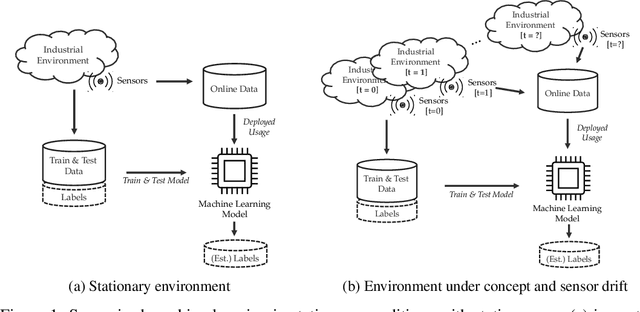
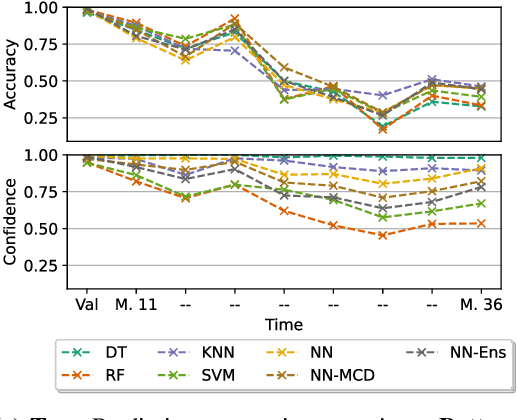
The increasing deployment of advanced digital technologies such as Internet of Things (IoT) devices and Cyber-Physical Systems (CPS) in industrial environments is enabling the productive use of machine learning (ML) algorithms in the manufacturing domain. As ML applications transcend from research to productive use in real-world industrial environments, the question of reliability arises. Since the majority of ML models are trained and evaluated on static datasets, continuous online monitoring of their performance is required to build reliable systems. Furthermore, concept and sensor drift can lead to degrading accuracy of the algorithm over time, thus compromising safety, acceptance and economics if undetected and not properly addressed. In this work, we exemplarily highlight the severity of the issue on a publicly available industrial dataset which was recorded over the course of 36 months and explain possible sources of drift. We assess the robustness of ML algorithms commonly used in manufacturing and show, that the accuracy strongly declines with increasing drift for all tested algorithms. We further investigate how uncertainty estimation may be leveraged for online performance estimation as well as drift detection as a first step towards continually learning applications. The results indicate, that ensemble algorithms like random forests show the least decay of confidence calibration under drift.
A Feature Importance Analysis for Soft-Sensing-Based Predictions in a Chemical Sulphonation Process
Sep 25, 2020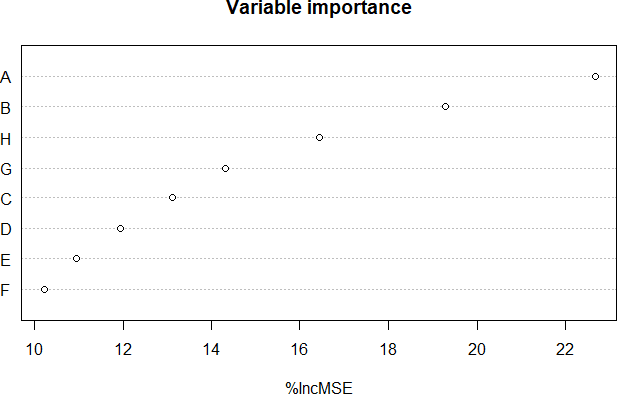

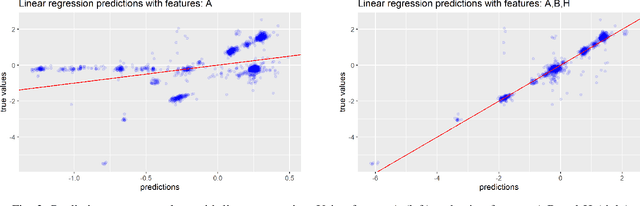
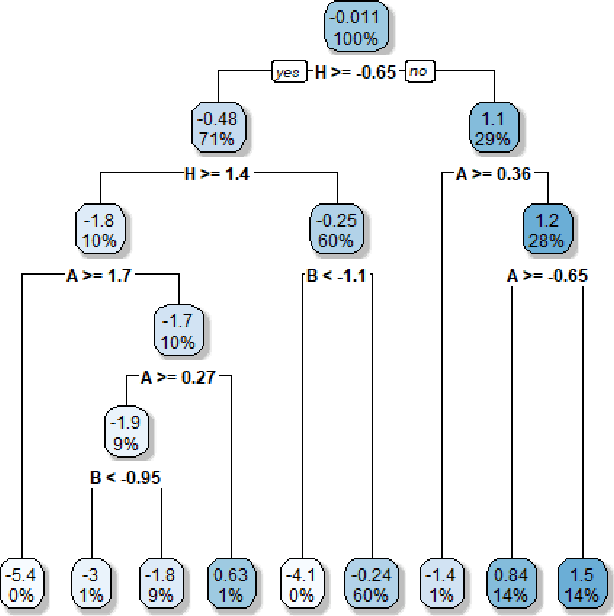
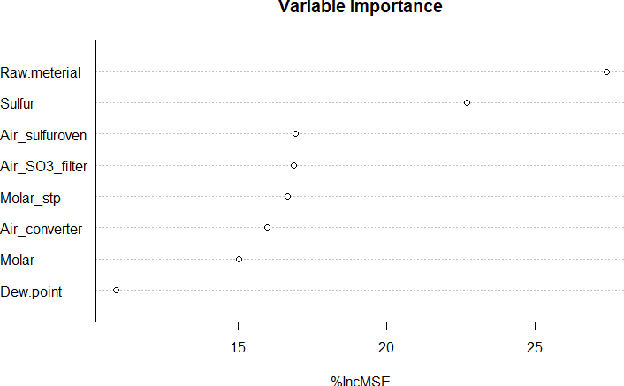
In this paper we present the results of a feature importance analysis of a chemical sulphonation process. The task consists of predicting the neutralization number (NT), which is a metric that characterizes the product quality of active detergents. The prediction is based on a dataset of environmental measurements, sampled from an industrial chemical process. We used a soft-sensing approach, that is, predicting a variable of interest based on other process variables, instead of directly sensing the variable of interest. Reasons for doing so range from expensive sensory hardware to harsh environments, e.g., inside a chemical reactor. The aim of this study was to explore and detect which variables are the most relevant for predicting product quality, and to what degree of precision. We trained regression models based on linear regression, regression tree and random forest. A random forest model was used to rank the predictor variables by importance. Then, we trained the models in a forward-selection style by adding one feature at a time, starting with the most important one. Our results show that it is sufficient to use the top 3 important variables, out of the 8 variables, to achieve satisfactory prediction results. On the other hand, Random Forest obtained the best result when trained with all variables.
Towards the Automation of a Chemical Sulphonation Process with Machine Learning
Sep 25, 2020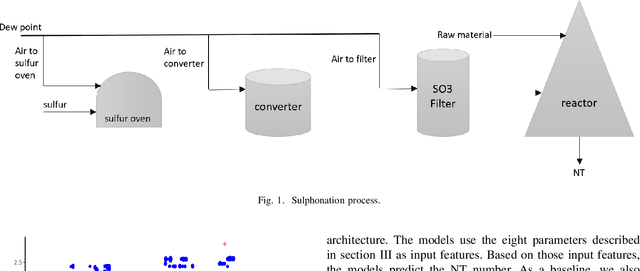
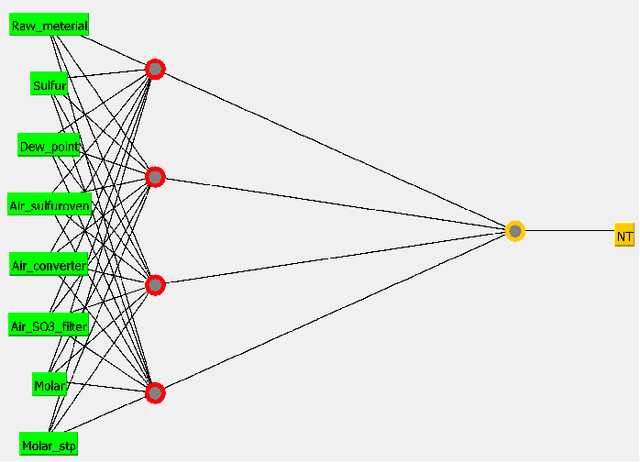

Nowadays, the continuous improvement and automation of industrial processes has become a key factor in many fields, and in the chemical industry, it is no exception. This translates into a more efficient use of resources, reduced production time, output of higher quality and reduced waste. Given the complexity of today's industrial processes, it becomes infeasible to monitor and optimize them without the use of information technologies and analytics. In recent years, machine learning methods have been used to automate processes and provide decision support. All of this, based on analyzing large amounts of data generated in a continuous manner. In this paper, we present the results of applying machine learning methods during a chemical sulphonation process with the objective of automating the product quality analysis which currently is performed manually. We used data from process parameters to train different models including Random Forest, Neural Network and linear regression in order to predict product quality values. Our experiments showed that it is possible to predict those product quality values with good accuracy, thus, having the potential to reduce time. Specifically, the best results were obtained with Random Forest with a mean absolute error of 0.089 and a correlation of 0.978.
* Published in: 2019 7th International Conference on Control, Mechatronics and Automation (ICCMA)