 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feature Importance Analysis for Soft-Sensing-Based Predictions in a Chemical Sulphonation Process
Sep 25, 2020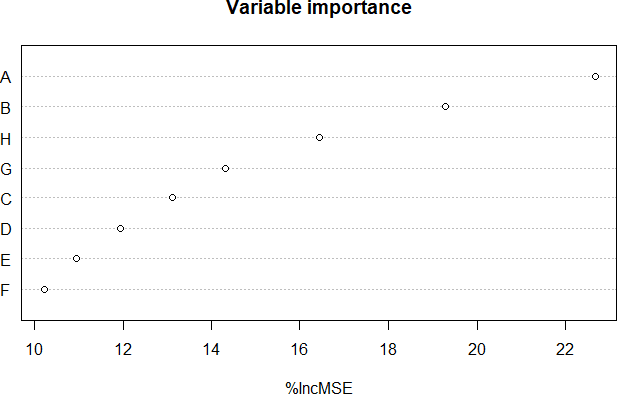

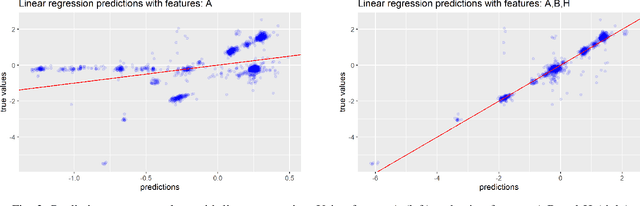
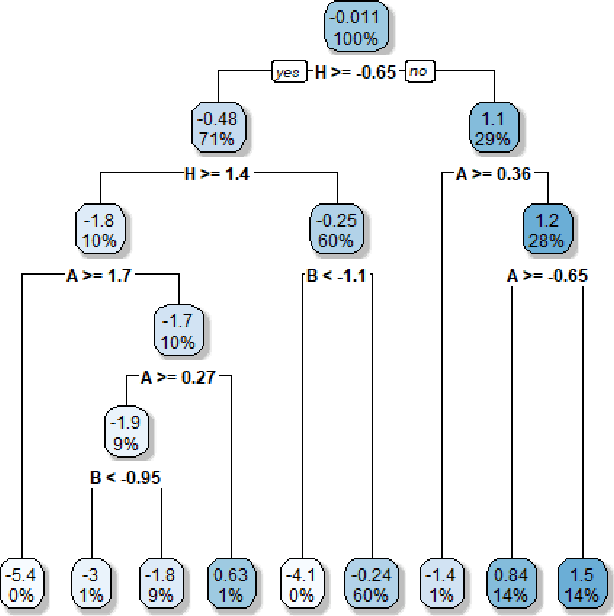
In this paper we present the results of a feature importance analysis of a chemical sulphonation process. The task consists of predicting the neutralization number (NT), which is a metric that characterizes the product quality of active detergents. The prediction is based on a dataset of environmental measurements, sampled from an industrial chemical process. We used a soft-sensing approach, that is, predicting a variable of interest based on other process variables, instead of directly sensing the variable of interest. Reasons for doing so range from expensive sensory hardware to harsh environments, e.g., inside a chemical reactor. The aim of this study was to explore and detect which variables are the most relevant for predicting product quality, and to what degree of precision. We trained regression models based on linear regression, regression tree and random forest. A random forest model was used to rank the predictor variables by importance. Then, we trained the models in a forward-selection style by adding one feature at a time, starting with the most important one. Our results show that it is sufficient to use the top 3 important variables, out of the 8 variables, to achieve satisfactory prediction results. On the other hand, Random Forest obtained the best result when trained with all variables.
Towards the Automation of a Chemical Sulphonation Process with Machine Learning
Sep 25, 2020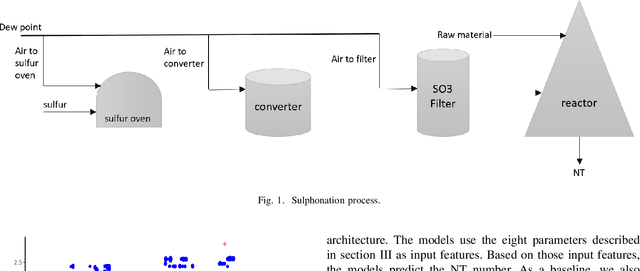
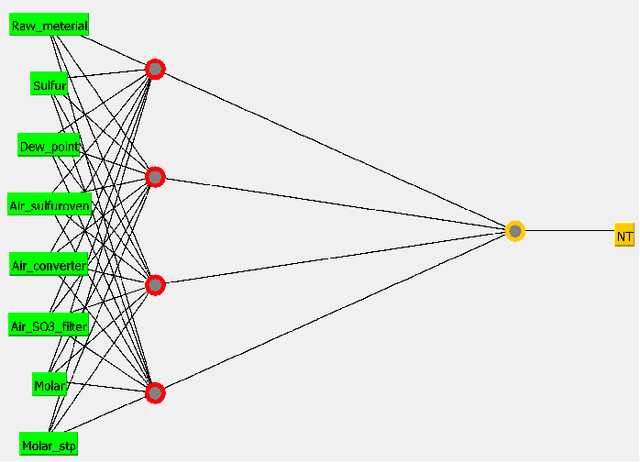

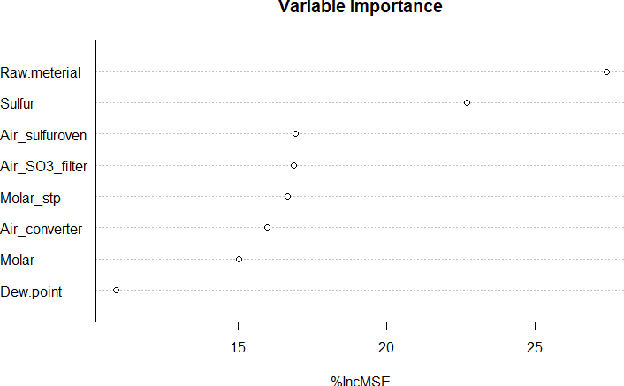
Nowadays, the continuous improvement and automation of industrial processes has become a key factor in many fields, and in the chemical industry, it is no exception. This translates into a more efficient use of resources, reduced production time, output of higher quality and reduced waste. Given the complexity of today's industrial processes, it becomes infeasible to monitor and optimize them without the use of information technologies and analytics. In recent years, machine learning methods have been used to automate processes and provide decision support. All of this, based on analyzing large amounts of data generated in a continuous manner. In this paper, we present the results of applying machine learning methods during a chemical sulphonation process with the objective of automating the product quality analysis which currently is performed manually. We used data from process parameters to train different models including Random Forest, Neural Network and linear regression in order to predict product quality values. Our experiments showed that it is possible to predict those product quality values with good accuracy, thus, having the potential to reduce time. Specifically, the best results were obtained with Random Forest with a mean absolute error of 0.089 and a correlation of 0.978.
* Published in: 2019 7th International Conference on Control, Mechatronics and Automation (ICCMA)