 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable LLM Inference for Edge AI: Evaluating Quantized LLMs for Energy Efficiency, Output Accuracy, and Inference Latency
Apr 04, 2025



Deploying Large Language Models (LLMs) on edge devices presents significant challenges due to computational constraints, memory limitations, inference speed, and energy consumption. Model quantization has emerged as a key technique to enable efficient LLM inference by reducing model size and computational overhead. In this study, we conduct a comprehensive analysis of 28 quantized LLMs from the Ollama library, which applies by default Post-Training Quantization (PTQ) and weight-only quantization techniques, deployed on an edge device (Raspberry Pi 4 with 4GB RAM). We evaluate energy efficiency, inference performance, and output accuracy across multiple quantization levels and task types. Models are benchmarked on five standardized datasets (CommonsenseQA, BIG-Bench Hard, TruthfulQA, GSM8K, and HumanEval), and we employ a high-resolution, hardware-based energy measurement tool to capture real-world power consumption. Our findings reveal the trade-offs between energy efficiency, inference speed, and accuracy in different quantization settings, highlighting configurations that optimize LLM deployment for resource-constrained environments. By integrating hardware-level energy profiling with LLM benchmarking, this study provides actionable insights for sustainable AI, bridging a critical gap in existing research on energy-aware LLM deployment.
Industry-academia research collaboration and knowledge co-creation: Patterns and anti-patterns
Apr 29, 2022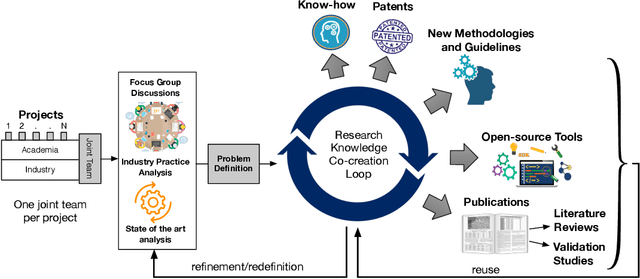

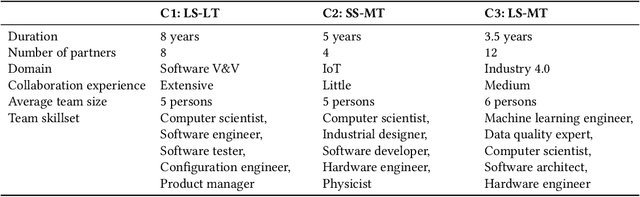
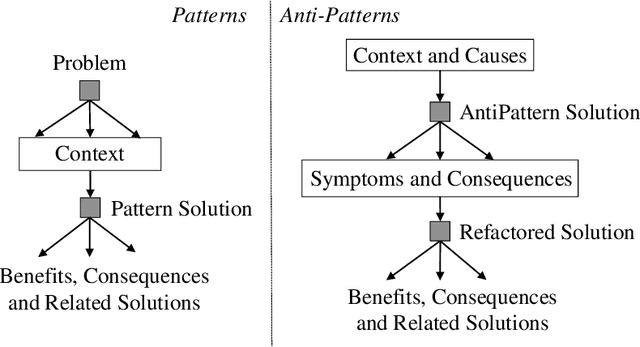
Increasing the impact of software engineering research in the software industry and the society at large has long been a concern of high priority for the software engineering community. The problem of two cultures, research conducted in a vacuum (disconnected from the real world), or misaligned time horizons are just some of the many complex challenges standing in the way of successful industry-academia collaborations. This paper reports on the experience of research collaboration and knowledge co-creation between industry and academia in software engineering as a way to bridge the research-practice collaboration gap. Our experience spans 14 years of collaboration between researchers in software engineering and the European and Norwegian software and IT industry. Using the participant observation and interview methods we have collected and afterwards analyzed an extensive record of qualitative data. Drawing upon the findings made and the experience gained, we provide a set of 14 patterns and 14 anti-patterns for industry-academia collaborations, aimed to support other researchers and practitioners in establishing and running research collaboration projects in software engineering.
On The Reliability Of Machine Learning Applications In Manufacturing Environments
Dec 19, 2021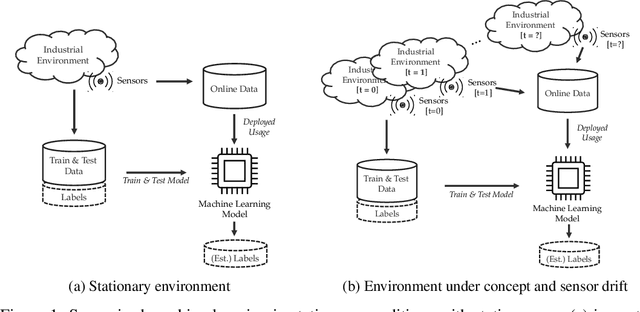
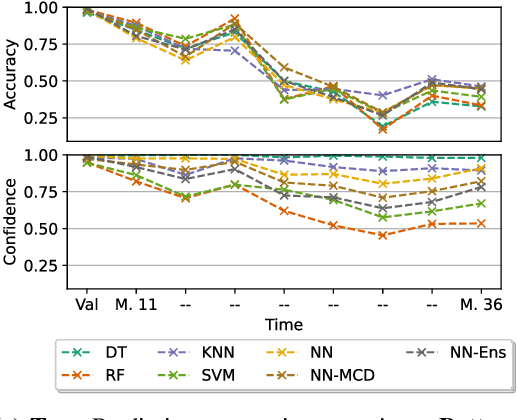
The increasing deployment of advanced digital technologies such as Internet of Things (IoT) devices and Cyber-Physical Systems (CPS) in industrial environments is enabling the productive use of machine learning (ML) algorithms in the manufacturing domain. As ML applications transcend from research to productive use in real-world industrial environments, the question of reliability arises. Since the majority of ML models are trained and evaluated on static datasets, continuous online monitoring of their performance is required to build reliable systems. Furthermore, concept and sensor drift can lead to degrading accuracy of the algorithm over time, thus compromising safety, acceptance and economics if undetected and not properly addressed. In this work, we exemplarily highlight the severity of the issue on a publicly available industrial dataset which was recorded over the course of 36 months and explain possible sources of drift. We assess the robustness of ML algorithms commonly used in manufacturing and show, that the accuracy strongly declines with increasing drift for all tested algorithms. We further investigate how uncertainty estimation may be leveraged for online performance estimation as well as drift detection as a first step towards continually learning applications. The results indicate, that ensemble algorithms like random forests show the least decay of confidence calibration under drift.
Opening the Software Engineering Toolbox for the Assessment of Trustworthy AI
Jul 14, 2020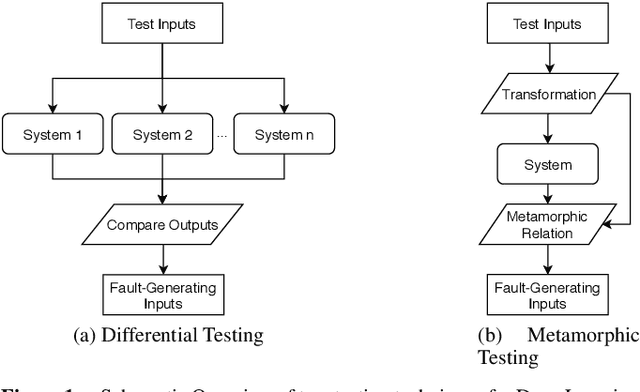
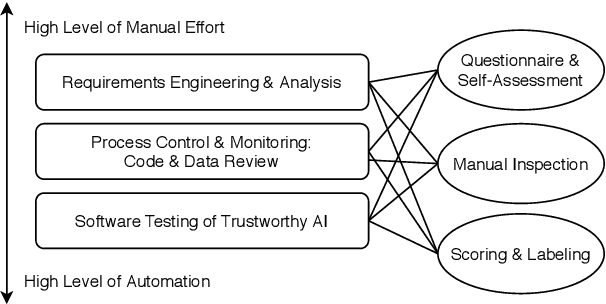
Trustworthiness is a central requirement for the acceptance and success of human-centered artificial intelligence (AI). To deem an AI system as trustworthy, it is crucial to assess its behaviour and characteristics against a gold standard of Trustworthy AI, consisting of guidelines, requirements, or only expectations. While AI systems are highly complex, their implementations are still based on software. The software engineering community has a long-established toolbox for the assessment of software systems, especially in the context of software testing. In this paper, we argue for the application of software engineering and testing practices for the assessment of trustworthy AI. We make the connection between the seven key requirements as defined by the European Commission's AI high-level expert group and established procedures from software engineering and raise questions for future work.