 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMAV: Reward Modeling of Autonomous Vehicles for Finding Likely Failure Events
Aug 28, 2023Autonomous vehicles are advanced driving systems that are well known for being vulnerable to various adversarial attacks, compromising the vehicle's safety, and posing danger to other road users. Rather than actively training complex adversaries by interacting with the environment, there is a need to first intelligently find and reduce the search space to only those states where autonomous vehicles are found less confident. In this paper, we propose a blackbox testing framework ReMAV using offline trajectories first to analyze the existing behavior of autonomous vehicles and determine appropriate thresholds for finding the probability of failure events. Our reward modeling technique helps in creating a behavior representation that allows us to highlight regions of likely uncertain behavior even when the baseline autonomous vehicle is performing well. This approach allows for more efficient testing without the need for computational and inefficient active adversarial learning techniques. We perform our experiments in a high-fidelity urban driving environment using three different driving scenarios containing single and multi-agent interactions. Our experiment shows 35%, 23%, 48%, and 50% increase in occurrences of vehicle collision, road objects collision, pedestrian collision, and offroad steering events respectively by the autonomous vehicle under test, demonstrating a significant increase in failure events. We also perform a comparative analysis with prior testing frameworks and show that they underperform in terms of training-testing efficiency, finding total infractions, and simulation steps to identify the first failure compared to our approach. The results show that the proposed framework can be used to understand existing weaknesses of the autonomous vehicles under test in order to only attack those regions, starting with the simplistic perturbation models.
Evaluating the Robustness of Deep Reinforcement Learning for Autonomous and Adversarial Policies in a Multi-agent Urban Driving Environment
Dec 22, 2021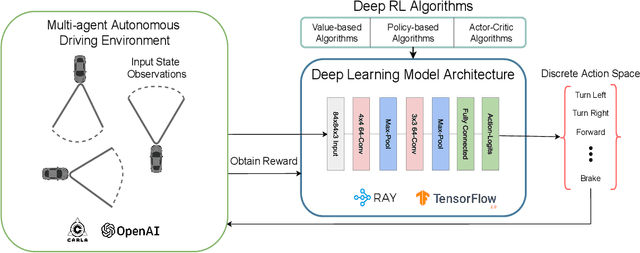
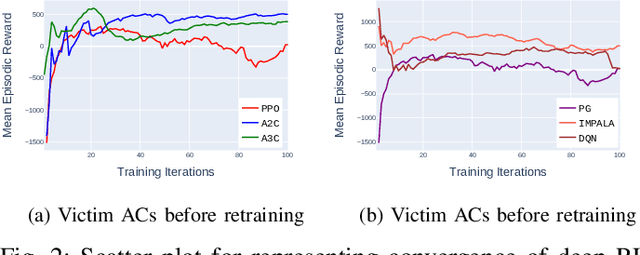
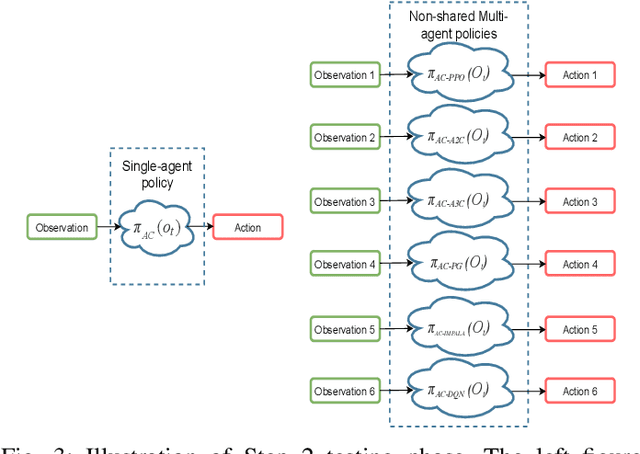
Deep reinforcement learning is actively used for training autonomous driving agents in a vision-based urban simulated environment. Due to the large availability of various reinforcement learning algorithms, we are still unsure of which one works better while training autonomous cars in single-agent as well as multi-agent driving environments. A comparison of deep reinforcement learning in vision-based autonomous driving will open up the possibilities for training better autonomous car policies. Also, autonomous cars trained on deep reinforcement learning-based algorithms are known for being vulnerable to adversarial attacks, and we have less information on which algorithms would act as a good adversarial agent. In this work, we provide a systematic evaluation and comparative analysis of 6 deep reinforcement learning algorithms for autonomous and adversarial driving in four-way intersection scenario. Specifically, we first train autonomous cars using state-of-the-art deep reinforcement learning algorithms. Second, we test driving capabilities of the trained autonomous policies in single-agent as well as multi-agent scenarios. Lastly, we use the same deep reinforcement learning algorithms to train adversarial driving agents, in order to test the driving performance of autonomous cars and look for possible collision and offroad driving scenarios. We perform experiments by using vision-only high fidelity urban driving simulated environments.
Adversarial Deep Reinforcement Learning for Trustworthy Autonomous Driving Policies
Dec 22, 2021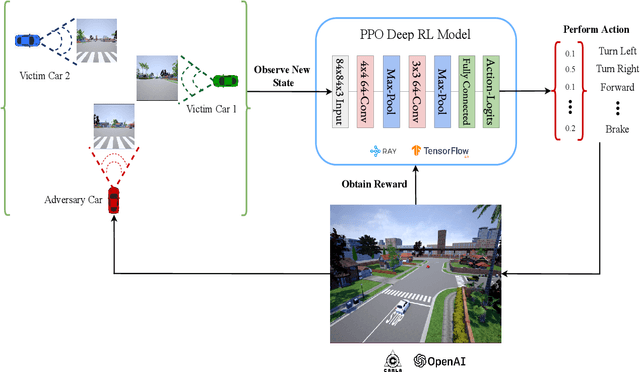
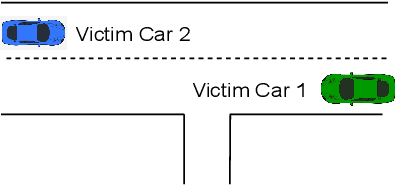
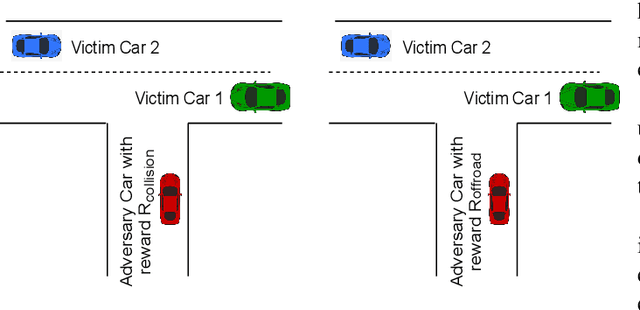
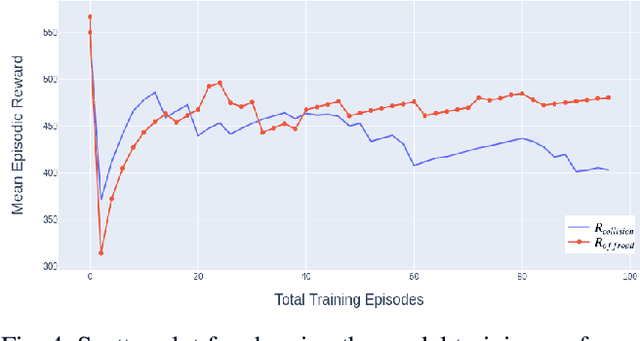
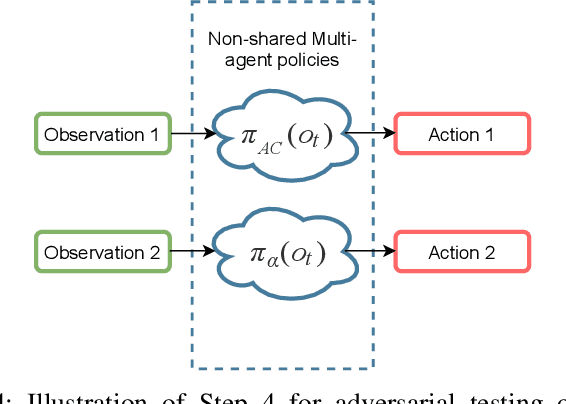
Deep reinforcement learning is widely used to train autonomous cars in a simulated environment. Still, autonomous cars are well known for being vulnerable when exposed to adversarial attacks. This raises the question of whether we can train the adversary as a driving agent for finding failure scenarios in autonomous cars, and then retrain autonomous cars with new adversarial inputs to improve their robustness. In this work, we first train and compare adversarial car policy on two custom reward functions to test the driving control decision of autonomous cars in a multi-agent setting. Second, we verify that adversarial examples can be used not only for finding unwanted autonomous driving behavior, but also for helping autonomous driving cars in improving their deep reinforcement learning policies. By using a high fidelity urban driving simulation environment and vision-based driving agents, we demonstrate that the autonomous cars retrained using the adversary player noticeably increase the performance of their driving policies in terms of reducing collision and offroad steering errors.
DeepOrder: Deep Learning for Test Case Prioritization in Continuous Integration Testing
Oct 14, 2021Continuous integration testing is an important step in the modern software engineering life cycle. Test prioritization is a method that can improve the efficiency of continuous integration testing by selecting test cases that can detect faults in the early stage of each cycle. As continuous integration testing produces voluminous test execution data, test history is a commonly used artifact in test prioritization. However, existing test prioritization techniques for continuous integration either cannot handle large test history or are optimized for using a limited number of historical test cycles. We show that such a limitation can decrease fault detection effectiveness of prioritized test suites. This work introduces DeepOrder, a deep learning-based model that works on the basis of regression machine learning. DeepOrder ranks test cases based on the historical record of test executions from any number of previous test cycles. DeepOrder learns failed test cases based on multiple factors including the duration and execution status of test cases. We experimentally show that deep neural networks, as a simple regression model, can be efficiently used for test case prioritization in continuous integration testing. DeepOrder is evaluated with respect to time-effectiveness and fault detection effectiveness in comparison with an industry practice and the state of the art approaches. The results show that DeepOrder outperforms the industry practice and state-of-the-art test prioritization approaches in terms of these two metrics.
Opening the Software Engineering Toolbox for the Assessment of Trustworthy AI
Jul 14, 2020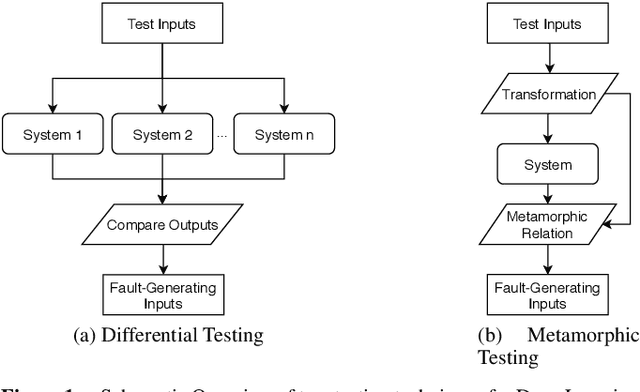
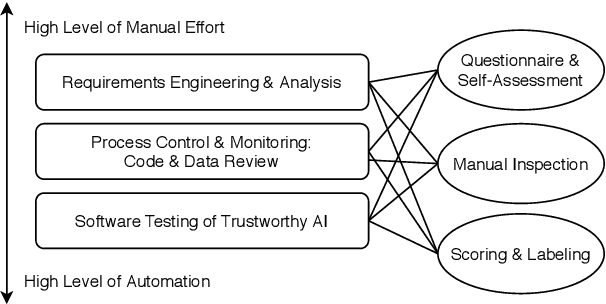
Trustworthiness is a central requirement for the acceptance and success of human-centered artificial intelligence (AI). To deem an AI system as trustworthy, it is crucial to assess its behaviour and characteristics against a gold standard of Trustworthy AI, consisting of guidelines, requirements, or only expectations. While AI systems are highly complex, their implementations are still based on software. The software engineering community has a long-established toolbox for the assessment of software systems, especially in the context of software testing. In this paper, we argue for the application of software engineering and testing practices for the assessment of trustworthy AI. We make the connection between the seven key requirements as defined by the European Commission's AI high-level expert group and established procedures from software engineering and raise questions for future work.