 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetamorphic Testing with the Rashomon Set: Explanation Faithfulness in Machine Learning
Jun 04, 2026Multiple machine learning models can achieve near-equivalent predictive performance on the same task, yet provide divergent feature-based explanations. This is called the Rashomon effect of (explainable) machine learning, and it raises the question of which explanations, if any, are trustworthy. We propose a framework based on metamorphic testing that assesses explanation faithfulness without requiring ground-truth labels by exploring attributed feature importance from post-hoc explanation methods. Five metamorphic relations formalize expected consistency properties between model behavior and feature attributions. We apply this general framework to two tabular regression datasets and two post-hoc explainers (SHAP and LIME) to demonstrate the approach. The framework offers a practical, model-agnostic tool for selecting accurate models with reliable and trustworthy explanations.
Semi-supervised CAPP Transformer Learning via Pseudo-labeling
Feb 01, 2026High-level Computer-Aided Process Planning (CAPP) generates manufacturing process plans from part specifications. It suffers from limited dataset availability in industry, reducing model generalization. We propose a semi-supervised learning approach to improve transformer-based CAPP transformer models without manual labeling. An oracle, trained on available transformer behaviour data, filters correct predictions from unseen parts, which are then used for one-shot retraining. Experiments on small-scale datasets with simulated ground truth across the full data distribution show consistent accuracy gains over baselines, demonstrating the method's effectiveness in data-scarce manufacturing environments.
Context-Aware Autoencoders for Anomaly Detection in Maritime Surveillance
Jan 27, 2026The detection of anomalies is crucial to ensuring the safety and security of maritime vessel traffic surveillance. Although autoencoders are popular for anomaly detection, their effectiveness in identifying collective and contextual anomalies is limited, especially in the maritime domain, where anomalies depend on vessel-specific contexts derived from self-reported AIS messages. To address these limitations, we propose a novel solution: the context-aware autoencoder. By integrating context-specific thresholds, our method improves detection accuracy and reduces computational cost. We compare four context-aware autoencoder variants and a conventional autoencoder using a case study focused on fishing status anomalies in maritime surveillance. Results demonstrate the significant impact of context on reconstruction loss and anomaly detection. The context-aware autoencoder outperforms others in detecting anomalies in time series data. By incorporating context-specific thresholds and recognizing the importance of context in anomaly detection, our approach offers a promising solution to improve accuracy in maritime vessel traffic surveillance systems.
Translating the Rashomon Effect to Sequential Decision-Making Tasks
Dec 19, 2025The Rashomon effect describes the phenomenon where multiple models trained on the same data produce identical predictions while differing in which features they rely on internally. This effect has been studied extensively in classification tasks, but not in sequential decision-making, where an agent learns a policy to achieve an objective by taking actions in an environment. In this paper, we translate the Rashomon effect to sequential decision-making. We define it as multiple policies that exhibit identical behavior, visiting the same states and selecting the same actions, while differing in their internal structure, such as feature attributions. Verifying identical behavior in sequential decision-making differs from classification. In classification, predictions can be directly compared to ground-truth labels. In sequential decision-making with stochastic transitions, the same policy may succeed or fail on any single trajectory due to randomness. We address this using formal verification methods that construct and compare the complete probabilistic behavior of each policy in the environment. Our experiments demonstrate that the Rashomon effect exists in sequential decision-making. We further show that ensembles constructed from the Rashomon set exhibit greater robustness to distribution shifts than individual policies. Additionally, permissive policies derived from the Rashomon set reduce computational requirements for verification while maintaining optimal performance.
Explainable Scene Understanding with Qualitative Representations and Graph Neural Networks
Apr 17, 2025This paper investigates the integration of graph neural networks (GNNs) with Qualitative Explainable Graphs (QXGs) for scene understanding in automated driving. Scene understanding is the basis for any further reactive or proactive decision-making. Scene understanding and related reasoning is inherently an explanation task: why is another traffic participant doing something, what or who caused their actions? While previous work demonstrated QXGs' effectiveness using shallow machine learning models, these approaches were limited to analysing single relation chains between object pairs, disregarding the broader scene context. We propose a novel GNN architecture that processes entire graph structures to identify relevant objects in traffic scenes. We evaluate our method on the nuScenes dataset enriched with DriveLM's human-annotated relevance labels. Experimental results show that our GNN-based approach achieves superior performance compared to baseline methods. The model effectively handles the inherent class imbalance in relevant object identification tasks while considering the complete spatial-temporal relationships between all objects in the scene. Our work demonstrates the potential of combining qualitative representations with deep learning approaches for explainable scene understanding in autonomous driving systems.
Co-Activation Graph Analysis of Safety-Verified and Explainable Deep Reinforcement Learning Policies
Jan 06, 2025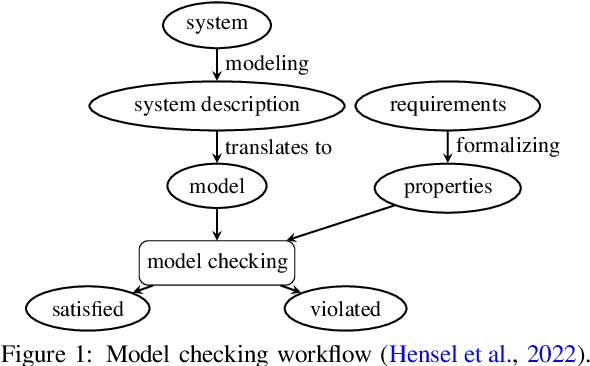
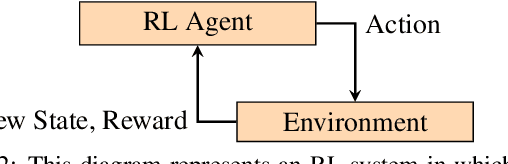
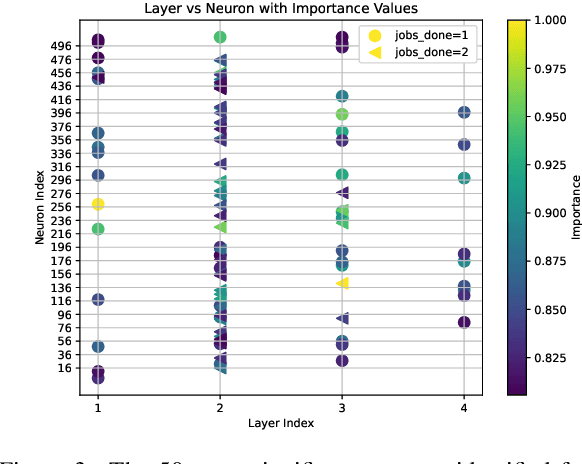
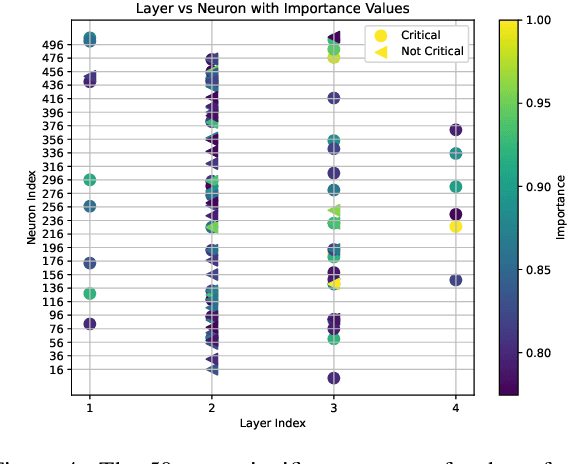
Deep reinforcement learning (RL) policies can demonstrate unsafe behaviors and are challenging to interpret. To address these challenges, we combine RL policy model checking--a technique for determining whether RL policies exhibit unsafe behaviors--with co-activation graph analysis--a method that maps neural network inner workings by analyzing neuron activation patterns--to gain insight into the safe RL policy's sequential decision-making. This combination lets us interpret the RL policy's inner workings for safe decision-making. We demonstrate its applicability in various experiments.
Enhancing RL Safety with Counterfactual LLM Reasoning
Sep 16, 2024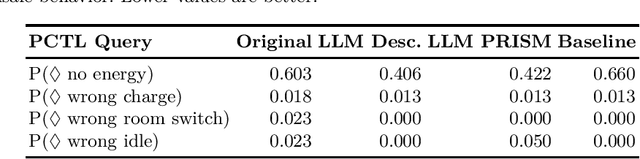
Reinforcement learning (RL) policies may exhibit unsafe behavior and are hard to explain. We use counterfactual large language model reasoning to enhance RL policy safety post-training. We show that our approach improves and helps to explain the RL policy safety.
Efficient Milling Quality Prediction with Explainable Machine Learning
Sep 16, 2024
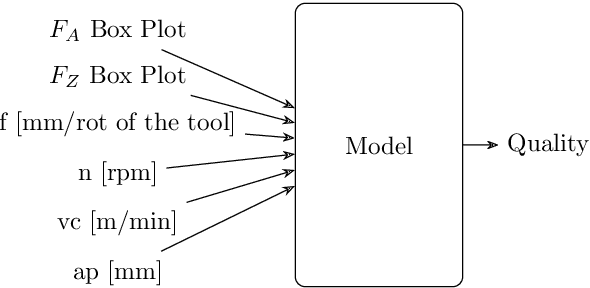
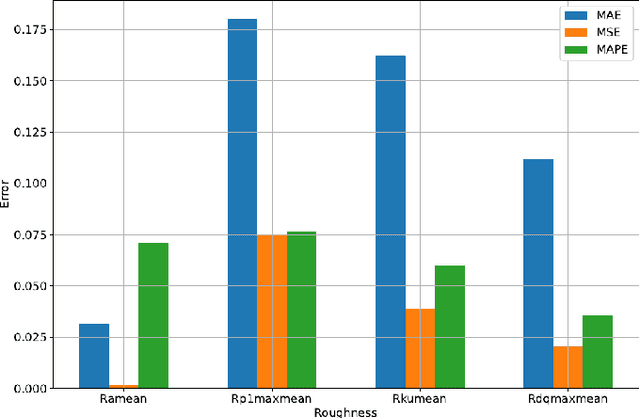
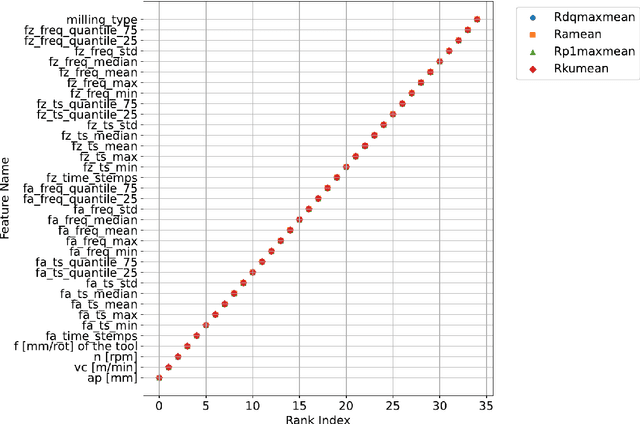
This paper presents an explainable machine learning (ML) approach for predicting surface roughness in milling. Utilizing a dataset from milling aluminum alloy 2017A, the study employs random forest regression models and feature importance techniques. The key contributions include developing ML models that accurately predict various roughness values and identifying redundant sensors, particularly those for measuring normal cutting force. Our experiments show that removing certain sensors can reduce costs without sacrificing predictive accuracy, highlighting the potential of explainable machine learning to improve cost-effectiveness in machining.
Safety-Oriented Pruning and Interpretation of Reinforcement Learning Policies
Sep 16, 2024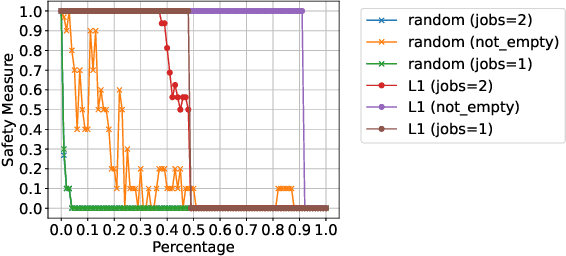

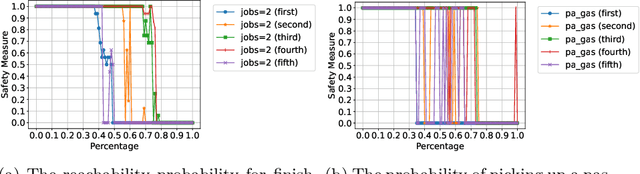
Pruning neural networks (NNs) can streamline them but risks removing vital parameters from safe reinforcement learning (RL) policies. We introduce an interpretable RL method called VERINTER, which combines NN pruning with model checking to ensure interpretable RL safety. VERINTER exactly quantifies the effects of pruning and the impact of neural connections on complex safety properties by analyzing changes in safety measurements. This method maintains safety in pruned RL policies and enhances understanding of their safety dynamics, which has proven effective in multiple RL settings.
Evaluating Human Trajectory Prediction with Metamorphic Testing
Jul 26, 2024



The prediction of human trajectories is important for planning in autonomous systems that act in the real world, e.g. automated driving or mobile robots. Human trajectory prediction is a noisy process, and no prediction does precisely match any future trajectory. It is therefore approached as a stochastic problem, where the goal is to minimise the error between the true and the predicted trajectory. In this work, we explore the application of metamorphic testing for human trajectory prediction. Metamorphic testing is designed to handle unclear or missing test oracles. It is well-designed for human trajectory prediction, where there is no clear criterion of correct or incorrect human behaviour. Metamorphic relations rely on transformations over source test cases and exploit invariants. A setting well-designed for human trajectory prediction where there are many symmetries of expected human behaviour under variations of the input, e.g. mirroring and rescaling of the input data. We discuss how metamorphic testing can be applied to stochastic human trajectory prediction and introduce the Wasserstein Violation Criterion to statistically assess whether a follow-up test case violates a label-preserving metamorphic relation.