 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-guided Neural Network-based Shaft Power Prediction for Vessels
Dec 23, 2025



Optimizing maritime operations, particularly fuel consumption for vessels, is crucial, considering its significant share in global trade. As fuel consumption is closely related to the shaft power of a vessel, predicting shaft power accurately is a crucial problem that requires careful consideration to minimize costs and emissions. Traditional approaches, which incorporate empirical formulas, often struggle to model dynamic conditions, such as sea conditions or fouling on vessels. In this paper, we present a hybrid, physics-guided neural network-based approach that utilizes empirical formulas within the network to combine the advantages of both neural networks and traditional techniques. We evaluate the presented method using data obtained from four similar-sized cargo vessels and compare the results with those of a baseline neural network and a traditional approach that employs empirical formulas. The experimental results demonstrate that the physics-guided neural network approach achieves lower mean absolute error, root mean square error, and mean absolute percentage error for all tested vessels compared to both the empirical formula-based method and the base neural network.
Explainable Compliance Detection with Multi-Hop Natural Language Inference on Assurance Case Structure
Jun 10, 2025Ensuring complex systems meet regulations typically requires checking the validity of assurance cases through a claim-argument-evidence framework. Some challenges in this process include the complicated nature of legal and technical texts, the need for model explanations, and limited access to assurance case data. We propose a compliance detection approach based on Natural Language Inference (NLI): EXplainable CompLiance detection with Argumentative Inference of Multi-hop reasoning (EXCLAIM). We formulate the claim-argument-evidence structure of an assurance case as a multi-hop inference for explainable and traceable compliance detection. We address the limited number of assurance cases by generating them using large language models (LLMs). We introduce metrics that measure the coverage and structural consistency. We demonstrate the effectiveness of the generated assurance case from GDPR requirements in a multi-hop inference task as a case study. Our results highlight the potential of NLI-based approaches in automating the regulatory compliance process.
Detecting Intentional AIS Shutdown in Open Sea Maritime Surveillance Using Self-Supervised Deep Learning
Oct 24, 2023In maritime traffic surveillance, detecting illegal activities, such as illegal fishing or transshipment of illicit products is a crucial task of the coastal administration. In the open sea, one has to rely on Automatic Identification System (AIS) message transmitted by on-board transponders, which are captured by surveillance satellites. However, insincere vessels often intentionally shut down their AIS transponders to hide illegal activities. In the open sea, it is very challenging to differentiate intentional AIS shutdowns from missing reception due to protocol limitations, bad weather conditions or restricting satellite positions. This paper presents a novel approach for the detection of abnormal AIS missing reception based on self-supervised deep learning techniques and transformer models. Using historical data, the trained model predicts if a message should be received in the upcoming minute or not. Afterwards, the model reports on detected anomalies by comparing the prediction with what actually happens. Our method can process AIS messages in real-time, in particular, more than 500 Millions AIS messages per month, corresponding to the trajectories of more than 60 000 ships. The method is evaluated on 1-year of real-world data coming from four Norwegian surveillance satellites. Using related research results, we validated our method by rediscovering already detected intentional AIS shutdowns.
ReMAV: Reward Modeling of Autonomous Vehicles for Finding Likely Failure Events
Aug 28, 2023Autonomous vehicles are advanced driving systems that are well known for being vulnerable to various adversarial attacks, compromising the vehicle's safety, and posing danger to other road users. Rather than actively training complex adversaries by interacting with the environment, there is a need to first intelligently find and reduce the search space to only those states where autonomous vehicles are found less confident. In this paper, we propose a blackbox testing framework ReMAV using offline trajectories first to analyze the existing behavior of autonomous vehicles and determine appropriate thresholds for finding the probability of failure events. Our reward modeling technique helps in creating a behavior representation that allows us to highlight regions of likely uncertain behavior even when the baseline autonomous vehicle is performing well. This approach allows for more efficient testing without the need for computational and inefficient active adversarial learning techniques. We perform our experiments in a high-fidelity urban driving environment using three different driving scenarios containing single and multi-agent interactions. Our experiment shows 35%, 23%, 48%, and 50% increase in occurrences of vehicle collision, road objects collision, pedestrian collision, and offroad steering events respectively by the autonomous vehicle under test, demonstrating a significant increase in failure events. We also perform a comparative analysis with prior testing frameworks and show that they underperform in terms of training-testing efficiency, finding total infractions, and simulation steps to identify the first failure compared to our approach. The results show that the proposed framework can be used to understand existing weaknesses of the autonomous vehicles under test in order to only attack those regions, starting with the simplistic perturbation models.
Measuring the Effect of Causal Disentanglement on the Adversarial Robustness of Neural Network Models
Aug 21, 2023Causal Neural Network models have shown high levels of robustness to adversarial attacks as well as an increased capacity for generalisation tasks such as few-shot learning and rare-context classification compared to traditional Neural Networks. This robustness is argued to stem from the disentanglement of causal and confounder input signals. However, no quantitative study has yet measured the level of disentanglement achieved by these types of causal models or assessed how this relates to their adversarial robustness. Existing causal disentanglement metrics are not applicable to deterministic models trained on real-world datasets. We, therefore, utilise metrics of content/style disentanglement from the field of Computer Vision to measure different aspects of the causal disentanglement for four state-of-the-art causal Neural Network models. By re-implementing these models with a common ResNet18 architecture we are able to fairly measure their adversarial robustness on three standard image classification benchmarking datasets under seven common white-box attacks. We find a strong association (r=0.820, p=0.001) between the degree to which models decorrelate causal and confounder signals and their adversarial robustness. Additionally, we find a moderate negative association between the pixel-level information content of the confounder signal and adversarial robustness (r=-0.597, p=0.040).
Software Testing for Machine Learning
Apr 30, 2022Machine learning has become prevalent across a wide variety of applications. Unfortunately, machine learning has also shown to be susceptible to deception, leading to errors, and even fatal failures. This circumstance calls into question the widespread use of machine learning, especially in safety-critical applications, unless we are able to assure its correctness and trustworthiness properties. Software verification and testing are established technique for assuring such properties, for example by detecting errors. However, software testing challenges for machine learning are vast and profuse - yet critical to address. This summary talk discusses the current state-of-the-art of software testing for machine learning. More specifically, it discusses six key challenge areas for software testing of machine learning systems, examines current approaches to these challenges and highlights their limitations. The paper provides a research agenda with elaborated directions for making progress toward advancing the state-of-the-art on testing of machine learning.
Industry-academia research collaboration and knowledge co-creation: Patterns and anti-patterns
Apr 29, 2022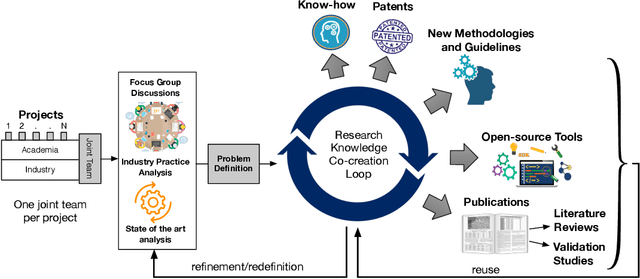

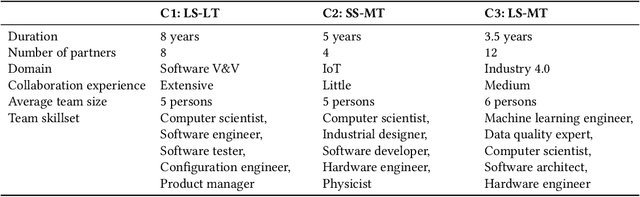
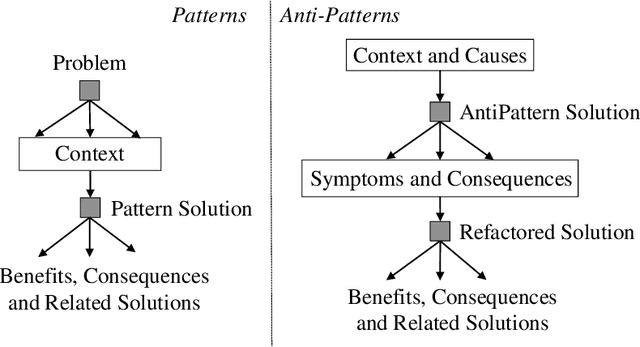
Increasing the impact of software engineering research in the software industry and the society at large has long been a concern of high priority for the software engineering community. The problem of two cultures, research conducted in a vacuum (disconnected from the real world), or misaligned time horizons are just some of the many complex challenges standing in the way of successful industry-academia collaborations. This paper reports on the experience of research collaboration and knowledge co-creation between industry and academia in software engineering as a way to bridge the research-practice collaboration gap. Our experience spans 14 years of collaboration between researchers in software engineering and the European and Norwegian software and IT industry. Using the participant observation and interview methods we have collected and afterwards analyzed an extensive record of qualitative data. Drawing upon the findings made and the experience gained, we provide a set of 14 patterns and 14 anti-patterns for industry-academia collaborations, aimed to support other researchers and practitioners in establishing and running research collaboration projects in software engineering.
Discovering Gateway Ports in Maritime Using Temporal Graph Neural Network Port Classification
Apr 25, 2022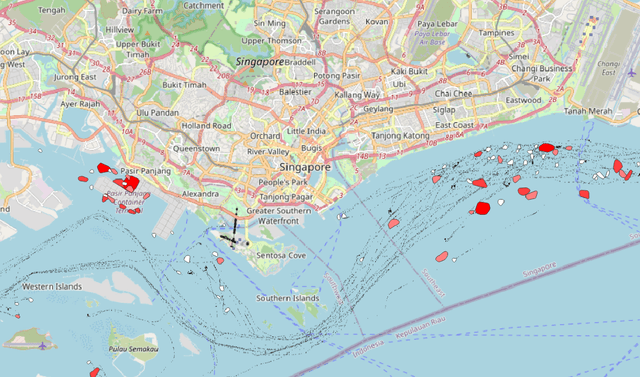

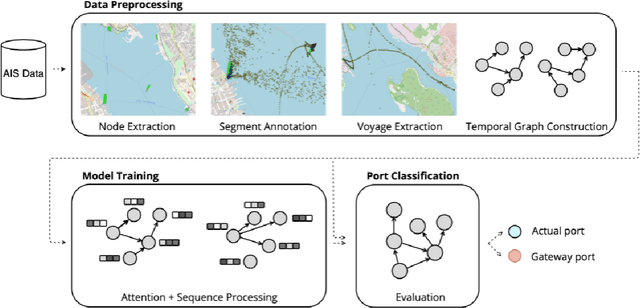
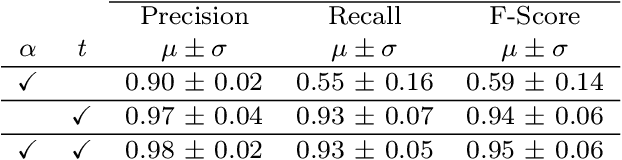
Vessel navigation is influenced by various factors, such as dynamic environmental factors that change over time or static features such as vessel type or depth of the ocean. These dynamic and static navigational factors impose limitations on vessels, such as long waiting times in regions outside the actual ports, and we call these waiting regions gateway ports. Identifying gateway ports and their associated features such as congestion and available utilities can enhance vessel navigation by planning on fuel optimization or saving time in cargo operation. In this paper, we propose a novel temporal graph neural network (TGNN) based port classification method to enable vessels to discover gateway ports efficiently, thus optimizing their operations. The proposed method processes vessel trajectory data to build dynamic graphs capturing spatio-temporal dependencies between a set of static and dynamic navigational features in the data, and it is evaluated in terms of port classification accuracy on a real-world data set collected from ten vessels operating in Halifax, NS, Canada. The experimental results indicate that our TGNN-based port classification method provides an f-score of 95% in classifying ports.
Industry-Academia Research Collaboration in Software Engineering: The Certus Model
Apr 23, 2022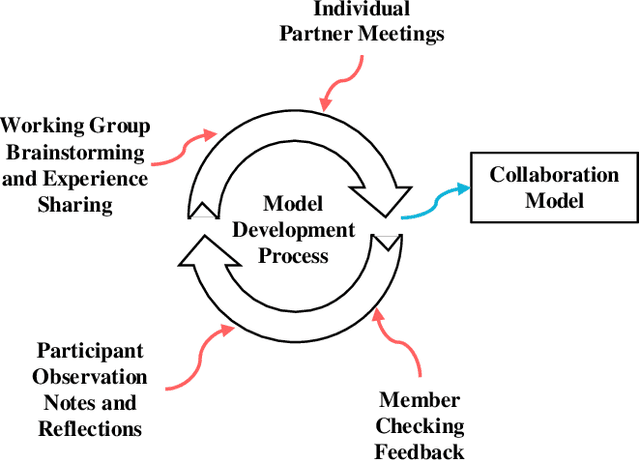

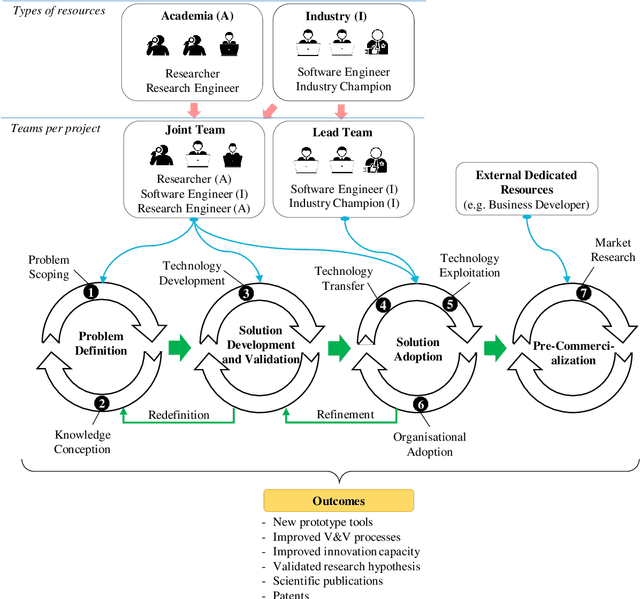

Context: Research collaborations between software engineering industry and academia can provide significant benefits to both sides, including improved innovation capacity for industry, and real-world environment for motivating and validating research ideas. However, building scalable and effective research collaborations in software engineering is known to be challenging. While such challenges can be varied and many, in this paper we focus on the challenges of achieving participative knowledge creation supported by active dialog between industry and academia and continuous commitment to joint problem solving. Objective: This paper aims to understand what are the elements of a successful industry-academia collaboration that enable the culture of participative knowledge creation. Method: We conducted participant observation collecting qualitative data spanning 8 years of collaborative research between a software engineering research group on software V&V and the Norwegian IT sector. The collected data was analyzed and synthesized into a practical collaboration model, named the Certus Model. Results: The model is structured in seven phases, describing activities from setting up research projects to the exploitation of research results. As such, the Certus model advances other collaborations models from literature by delineating different phases covering the complete life cycle of participative research knowledge creation. Conclusion: The Certus model describes the elements of a research collaboration process between researchers and practitioners in software engineering, grounded on the principles of research knowledge co-creation and continuous commitment to joint problem solving. The model can be applied and tested in other contexts where it may be adapted to the local context through experimentation.
Comparative Study of Machine Learning Test Case Prioritization for Continuous Integration Testing
Apr 22, 2022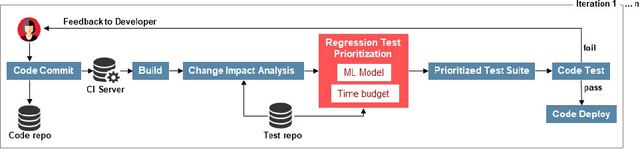



There is a growing body of research indicating the potential of machine learning to tackle complex software testing challenges. One such challenge pertains to continuous integration testing, which is highly time-constrained, and generates a large amount of data coming from iterative code commits and test runs. In such a setting, we can use plentiful test data for training machine learning predictors to identify test cases able to speed up the detection of regression bugs introduced during code integration. However, different machine learning models can have different fault prediction performance depending on the context and the parameters of continuous integration testing, for example variable time budget available for continuous integration cycles, or the size of test execution history used for learning to prioritize failing test cases. Existing studies on test case prioritization rarely study both of these factors, which are essential for the continuous integration practice. In this study we perform a comprehensive comparison of the fault prediction performance of machine learning approaches that have shown the best performance on test case prioritization tasks in the literature. We evaluate the accuracy of the classifiers in predicting fault-detecting tests for different values of the continuous integration time budget and with different length of test history used for training the classifiers. In evaluation, we use real-world industrial datasets from a continuous integration practice. The results show that different machine learning models have different performance for different size of test history used for model training and for different time budget available for test case execution. Our results imply that machine learning approaches for test prioritization in continuous integration testing should be carefully configured to achieve optimal performance.