 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Model Checking of Stochastic Reinforcement Learning Policies
Paper and Code
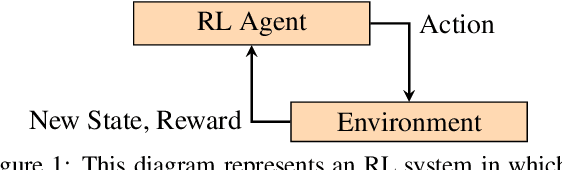
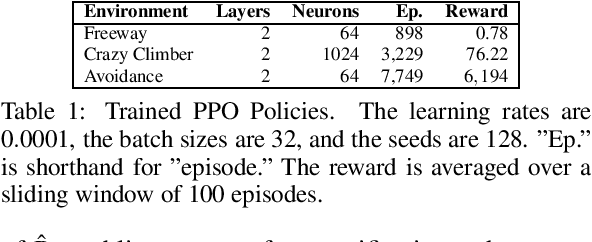
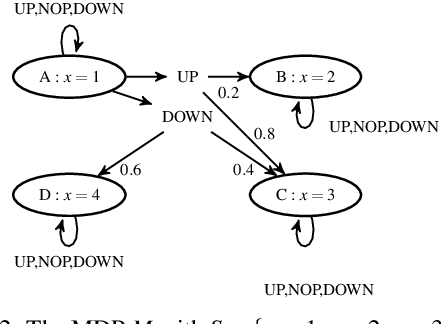

We introduce a method to verify stochastic reinforcement learning (RL) policies. This approach is compatible with any RL algorithm as long as the algorithm and its corresponding environment collectively adhere to the Markov property. In this setting, the future state of the environment should depend solely on its current state and the action executed, independent of any previous states or actions. Our method integrates a verification technique, referred to as model checking, with RL, leveraging a Markov decision process, a trained RL policy, and a probabilistic computation tree logic (PCTL) formula to build a formal model that can be subsequently verified via the model checker Storm. We demonstrate our method's applicability across multiple benchmarks, comparing it to baseline methods called deterministic safety estimates and naive monolithic model checking. Our results show that our method is suited to verify stochastic RL policies.