 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Scene Understanding with Qualitative Representations and Graph Neural Networks
Apr 17, 2025This paper investigates the integration of graph neural networks (GNNs) with Qualitative Explainable Graphs (QXGs) for scene understanding in automated driving. Scene understanding is the basis for any further reactive or proactive decision-making. Scene understanding and related reasoning is inherently an explanation task: why is another traffic participant doing something, what or who caused their actions? While previous work demonstrated QXGs' effectiveness using shallow machine learning models, these approaches were limited to analysing single relation chains between object pairs, disregarding the broader scene context. We propose a novel GNN architecture that processes entire graph structures to identify relevant objects in traffic scenes. We evaluate our method on the nuScenes dataset enriched with DriveLM's human-annotated relevance labels. Experimental results show that our GNN-based approach achieves superior performance compared to baseline methods. The model effectively handles the inherent class imbalance in relevant object identification tasks while considering the complete spatial-temporal relationships between all objects in the scene. Our work demonstrates the potential of combining qualitative representations with deep learning approaches for explainable scene understanding in autonomous driving systems.
Evaluating Human Trajectory Prediction with Metamorphic Testing
Jul 26, 2024



The prediction of human trajectories is important for planning in autonomous systems that act in the real world, e.g. automated driving or mobile robots. Human trajectory prediction is a noisy process, and no prediction does precisely match any future trajectory. It is therefore approached as a stochastic problem, where the goal is to minimise the error between the true and the predicted trajectory. In this work, we explore the application of metamorphic testing for human trajectory prediction. Metamorphic testing is designed to handle unclear or missing test oracles. It is well-designed for human trajectory prediction, where there is no clear criterion of correct or incorrect human behaviour. Metamorphic relations rely on transformations over source test cases and exploit invariants. A setting well-designed for human trajectory prediction where there are many symmetries of expected human behaviour under variations of the input, e.g. mirroring and rescaling of the input data. We discuss how metamorphic testing can be applied to stochastic human trajectory prediction and introduce the Wasserstein Violation Criterion to statistically assess whether a follow-up test case violates a label-preserving metamorphic relation.
Towards Trustworthy Automated Driving through Qualitative Scene Understanding and Explanations
Mar 25, 2024



Understanding driving scenes and communicating automated vehicle decisions are key requirements for trustworthy automated driving. In this article, we introduce the Qualitative Explainable Graph (QXG), which is a unified symbolic and qualitative representation for scene understanding in urban mobility. The QXG enables interpreting an automated vehicle's environment using sensor data and machine learning models. It utilizes spatio-temporal graphs and qualitative constraints to extract scene semantics from raw sensor inputs, such as LiDAR and camera data, offering an interpretable scene model. A QXG can be incrementally constructed in real-time, making it a versatile tool for in-vehicle explanations across various sensor types. Our research showcases the potential of QXG, particularly in the context of automated driving, where it can rationalize decisions by linking the graph with observed actions. These explanations can serve diverse purposes, from informing passengers and alerting vulnerable road users to enabling post-hoc analysis of prior behaviors.
Acquiring Qualitative Explainable Graphs for Automated Driving Scene Interpretation
Aug 24, 2023

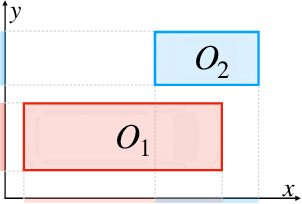

The future of automated driving (AD) is rooted in the development of robust, fair and explainable artificial intelligence methods. Upon request, automated vehicles must be able to explain their decisions to the driver and the car passengers, to the pedestrians and other vulnerable road users and potentially to external auditors in case of accidents. However, nowadays, most explainable methods still rely on quantitative analysis of the AD scene representations captured by multiple sensors. This paper proposes a novel representation of AD scenes, called Qualitative eXplainable Graph (QXG), dedicated to qualitative spatiotemporal reasoning of long-term scenes. The construction of this graph exploits the recent Qualitative Constraint Acquisition paradigm. Our experimental results on NuScenes, an open real-world multi-modal dataset, show that the qualitative eXplainable graph of an AD scene composed of 40 frames can be computed in real-time and light in space storage which makes it a potentially interesting tool for improved and more trustworthy perception and control processes in AD.
Boosting the Learning for Ranking Patterns
Mar 05, 2022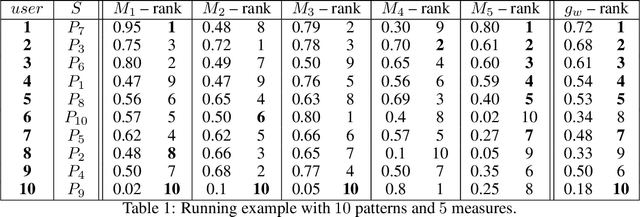
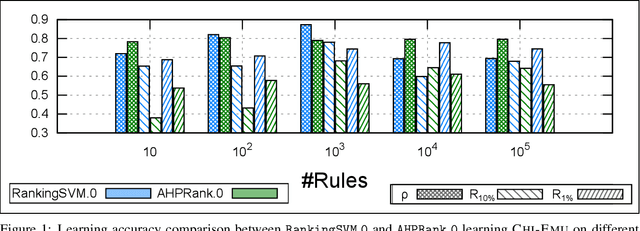

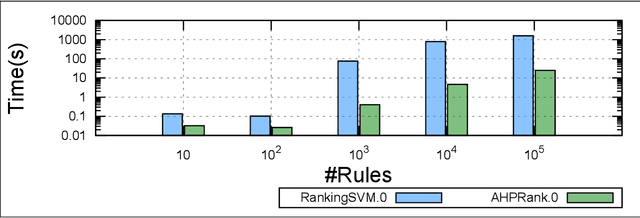
Discovering relevant patterns for a particular user remains a challenging tasks in data mining. Several approaches have been proposed to learn user-specific pattern ranking functions. These approaches generalize well, but at the expense of the running time. On the other hand, several measures are often used to evaluate the interestingness of patterns, with the hope to reveal a ranking that is as close as possible to the user-specific ranking. In this paper, we formulate the problem of learning pattern ranking functions as a multicriteria decision making problem. Our approach aggregates different interestingness measures into a single weighted linear ranking function, using an interactive learning procedure that operates in either passive or active modes. A fast learning step is used for eliciting the weights of all the measures by mean of pairwise comparisons. This approach is based on Analytic Hierarchy Process (AHP), and a set of user-ranked patterns to build a preference matrix, which compares the importance of measures according to the user-specific interestingness. A sensitivity based heuristic is proposed for the active learning mode, in order to insure high quality results with few user ranking queries. Experiments conducted on well-known datasets show that our approach significantly reduces the running time and returns precise pattern ranking, while being robust to user-error compared with state-of-the-art approaches.
Solve Optimization Problems with Unknown Constraint Networks
Nov 23, 2021In most optimization problems, users have a clear understanding of the function to optimize (e.g., minimize the makespan for scheduling problems). However, the constraints may be difficult to state and their modelling often requires expertise in Constraint Programming. Active constraint acquisition has been successfully used to support non-experienced users in learning constraint networks through the generation of a sequence of queries. In this paper, we propose Learn&Optimize, a method to solve optimization problems with known objective function and unknown constraint network. It uses an active constraint acquisition algorithm which learns the unknown constraints and computes boundaries for the optimal solution during the learning process. As a result, our method allows users to solve optimization problems without learning the overall constraint network.
Frequent Itemset Mining with Multiple Minimum Supports: a Constraint-based Approach
Sep 16, 2021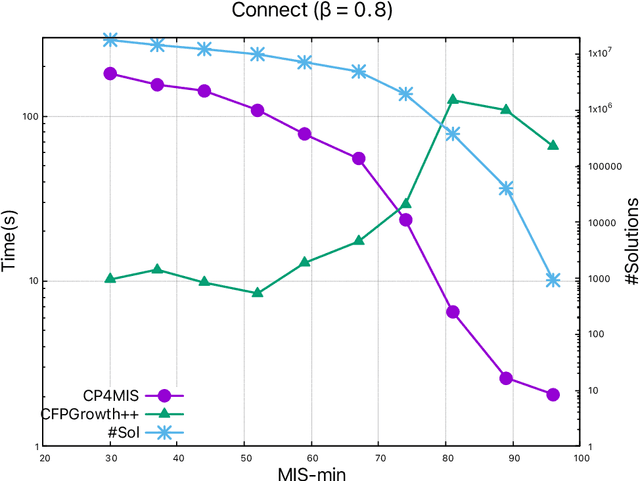

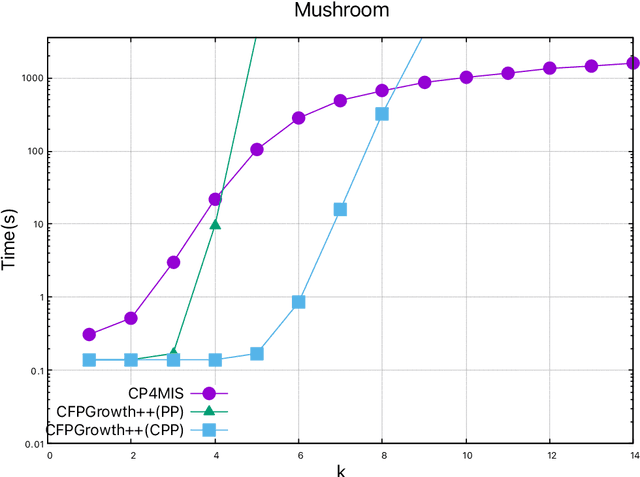
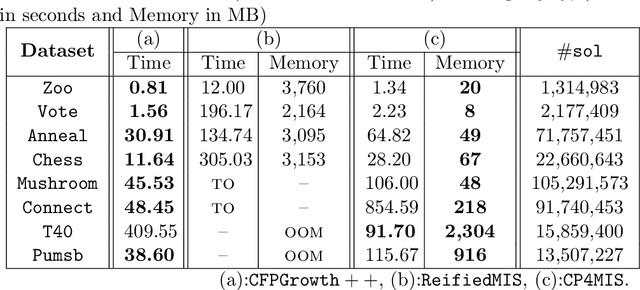
The problem of discovering frequent itemsets including rare ones has received a great deal of attention. The mining process needs to be flexible enough to extract frequent and rare regularities at once. On the other hand, it has recently been shown that constraint programming is a flexible way to tackle data mining tasks. In this paper, we propose a constraint programming approach for mining itemsets with multiple minimum supports. Our approach provides the user with the possibility to express any kind of constraints on the minimum item supports. An experimental analysis shows the practical effectiveness of our approach compared to the state of the art.
Computational Complexity of Three Central Problems in Itemset Mining
Dec 08, 2020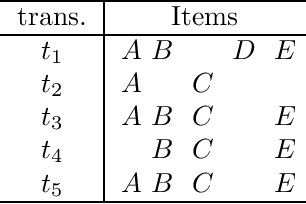

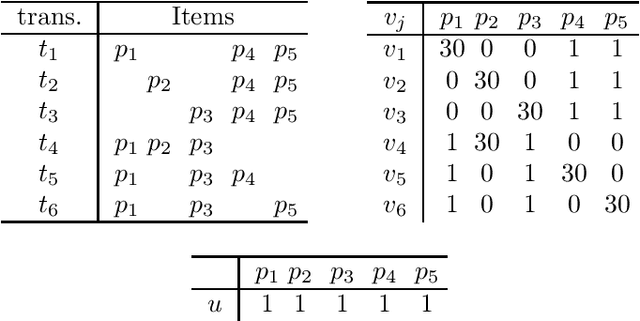
Itemset mining is one of the most studied tasks in knowledge discovery. In this paper we analyze the computational complexity of three central itemset mining problems. We prove that mining confident rules with a given item in the head is NP-hard. We prove that mining high utility itemsets is NP-hard. We finally prove that mining maximal or closed itemsets is coNP-hard as soon as the users can specify constraints on the kind of itemsets they are interested in.
Partial Queries for Constraint Acquisition
Mar 14, 2020
Learning constraint networks is known to require a number of membership queries exponential in the number of variables. In this paper, we learn constraint networks by asking the user partial queries. That is, we ask the user to classify assignments to subsets of the variables as positive or negative. We provide an algorithm, called QUACQ, that, given a negative example, focuses onto a constraint of the target network in a number of queries logarithmic in the size of the example. The whole constraint network can then be learned with a polynomial number of partial queries. We give information theoretic lower bounds for learning some simple classes of constraint networks and show that our generic algorithm is optimal in some cases.
Users Constraints in Itemset Mining
Feb 08, 2018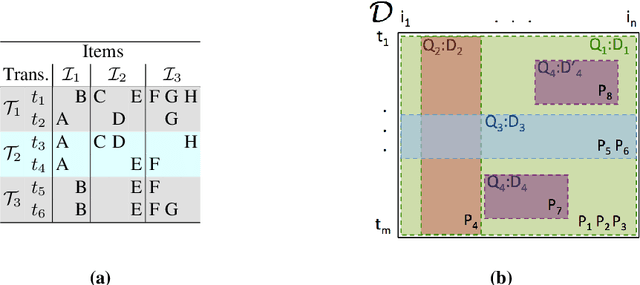
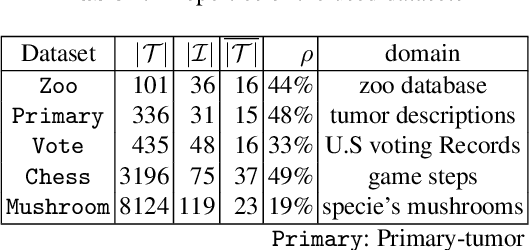
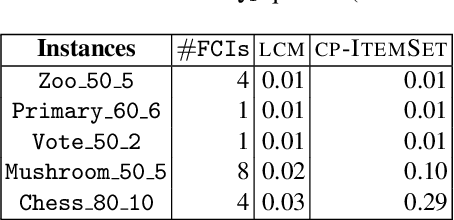
Discovering significant itemsets is one of the fundamental problems in data mining. It has recently been shown that constraint programming is a flexible way to tackle data mining tasks. With a constraint programming approach, we can easily express and efficiently answer queries with users constraints on items. However, in many practical cases it is possible that queries also express users constraints on the dataset itself. For instance, asking for a particular itemset in a particular part of the dataset. This paper presents a general constraint programming model able to handle any kind of query on the items or the dataset for itemset mining.