Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing RL Safety with Counterfactual LLM Reasoning
Paper and Code
Sep 16, 2024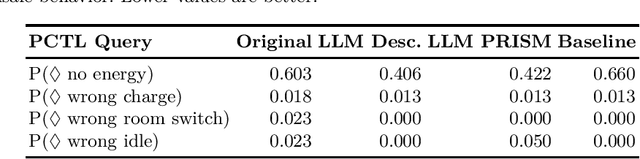
Reinforcement learning (RL) policies may exhibit unsafe behavior and are hard to explain. We use counterfactual large language model reasoning to enhance RL policy safety post-training. We show that our approach improves and helps to explain the RL policy safety.
View paper on