 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming
Jan 16, 2026Large Language Models (LLMs) increasingly succeed on competitive programming problems, yet existing evaluations conflate algorithmic reasoning with code-level implementation. We argue that competitive programming is fundamentally a problem-solving task and propose centering natural-language editorials in both solution generation and evaluation. Generating an editorial prior to code improves solve rates for some LLMs, with substantially larger gains when using expertly written gold editorials. However, even with gold editorials, models continue to struggle with implementation, while the gap between generated and gold editorials reveals a persistent problem-solving bottleneck in specifying correct and complete algorithms. Beyond pass/fail metrics, we diagnose reasoning errors by comparing model-generated editorials to gold standards using expert annotations and validate an LLM-as-a-judge protocol for scalable evaluation. We introduce a dataset of 83 ICPC-style problems with gold editorials and full test suites, and evaluate 19 LLMs, arguing that future benchmarks should explicitly separate problem solving from implementation.
Multilinguality as Sense Adaptation
Jan 15, 2026We approach multilinguality as sense adaptation: aligning latent meaning representations across languages rather than relying solely on shared parameters and scale. In this paper, we introduce SENse-based Symmetric Interlingual Alignment (SENSIA), which adapts a Backpack language model from one language to another by explicitly aligning sense-level mixtures and contextual representations on parallel data, while jointly training a target-language language modeling loss to preserve fluency. Across benchmarks on four typologically diverse languages, SENSIA generally outperforms comparable multilingual alignment methods and achieves competitive accuracy against monolingual from-scratch baselines while using 2-4x less target-language data. Analyses of learned sense geometry indicate that local sense topology and global structure relative to English are largely preserved, and ablations show that the method is robust in terms of design and scale.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Thank You, Stingray: Multilingual Large Language Models Can Not (Yet) Disambiguate Cross-Lingual Word Sense
Oct 28, 2024
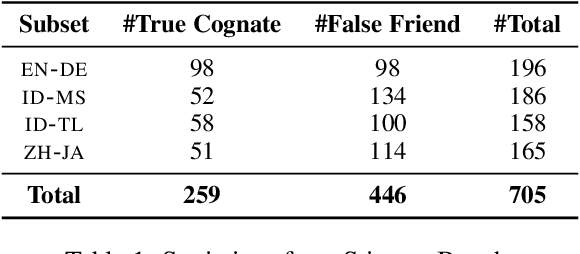
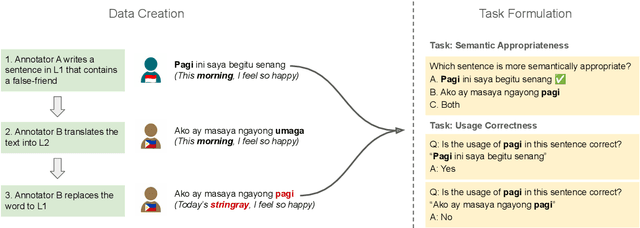

Multilingual large language models (LLMs) have gained prominence, but concerns arise regarding their reliability beyond English. This study addresses the gap in cross-lingual semantic evaluation by introducing a novel benchmark for cross-lingual sense disambiguation, StingrayBench. In this paper, we demonstrate using false friends -- words that are orthographically similar but have completely different meanings in two languages -- as a possible approach to pinpoint the limitation of cross-lingual sense disambiguation in LLMs. We collect false friends in four language pairs, namely Indonesian-Malay, Indonesian-Tagalog, Chinese-Japanese, and English-German; and challenge LLMs to distinguish the use of them in context. In our analysis of various models, we observe they tend to be biased toward higher-resource languages. We also propose new metrics for quantifying the cross-lingual sense bias and comprehension based on our benchmark. Our work contributes to developing more diverse and inclusive language modeling, promoting fairer access for the wider multilingual community.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024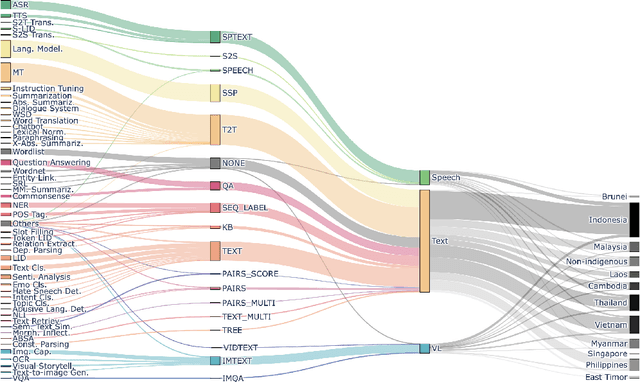
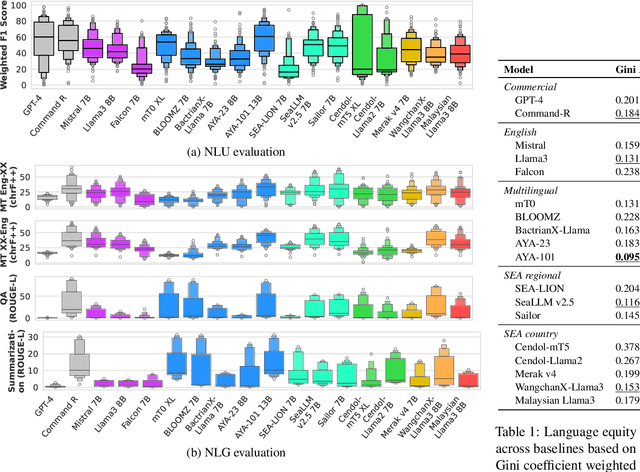
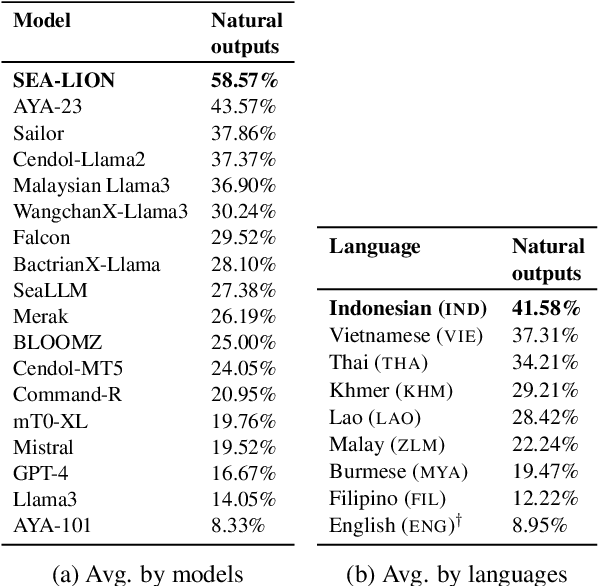
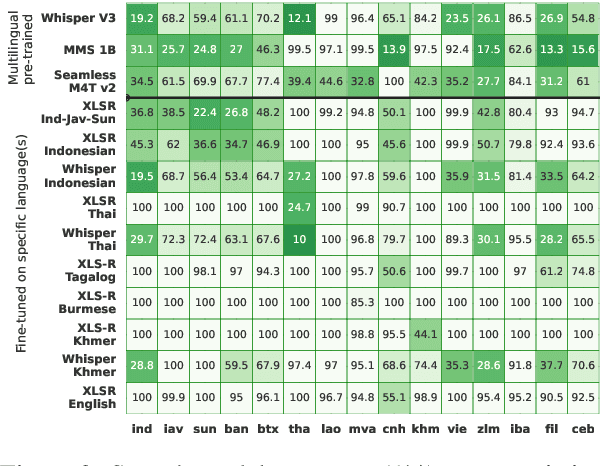
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Samsung R&D Institute Philippines at WMT 2023
Oct 25, 2023In this paper, we describe the constrained MT systems submitted by Samsung R&D Institute Philippines to the WMT 2023 General Translation Task for two directions: en$\rightarrow$he and he$\rightarrow$en. Our systems comprise of Transformer-based sequence-to-sequence models that are trained with a mix of best practices: comprehensive data preprocessing pipelines, synthetic backtranslated data, and the use of noisy channel reranking during online decoding. Our models perform comparably to, and sometimes outperform, strong baseline unconstrained systems such as mBART50 M2M and NLLB 200 MoE despite having significantly fewer parameters on two public benchmarks: FLORES-200 and NTREX-128.
Multilingual Large Language Models Are Not (Yet) Code-Switchers
May 23, 2023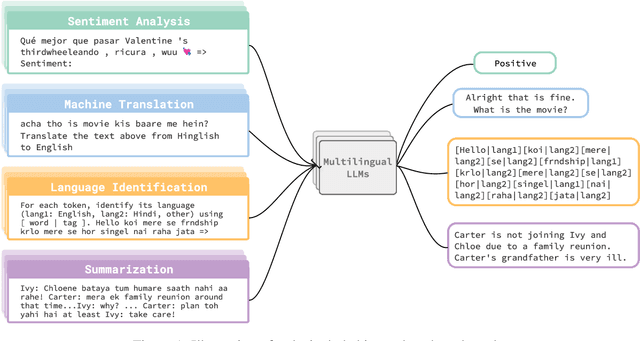
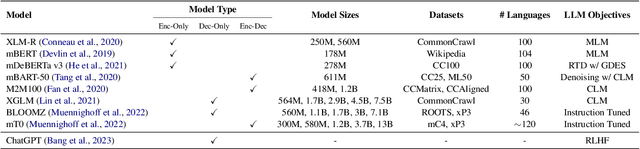
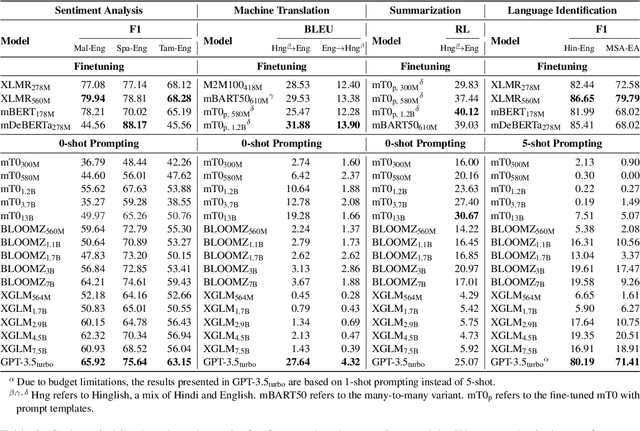
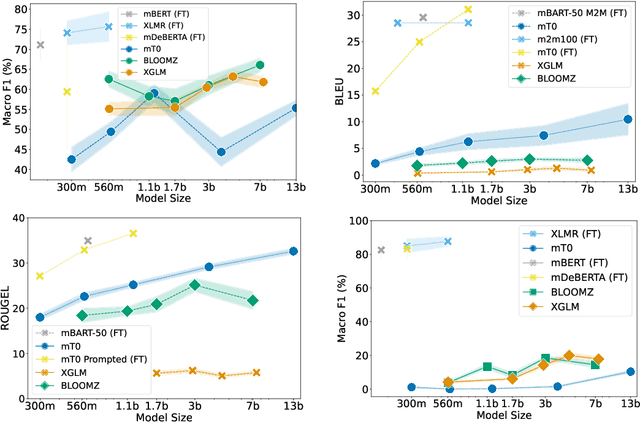
Multilingual Large Language Models (LLMs) have recently shown great capability in various tasks, exhibiting state-of-the-art performance using few-shot or zero-shot prompting methods. While these models have been extensively studied in tasks where inputs are assumed to be in a single language, less attention has been paid to exploring their performance when inputs involve code-switching (CSW). In this paper, we provide an extensive empirical study of various multilingual LLMs and benchmark their performance in three tasks: sentiment analysis, machine translation, and word-level language identification. Our findings indicate that despite multilingual LLMs showing promising outcomes in certain tasks when using zero-/few-shot prompting, their performance still falls short on average when compared to smaller finetuned models. We argue that LLMs that are "multilingual" are not necessarily code-switching compatible and extensive future research is required to fully bridge this gap.