 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThank You, Stingray: Multilingual Large Language Models Can Not (Yet) Disambiguate Cross-Lingual Word Sense
Oct 28, 2024
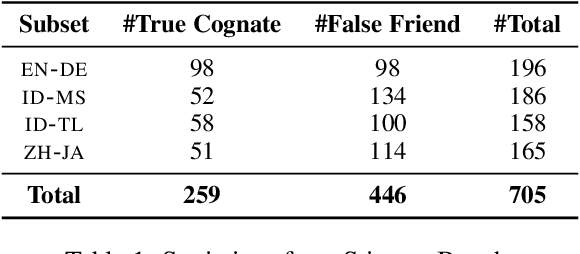
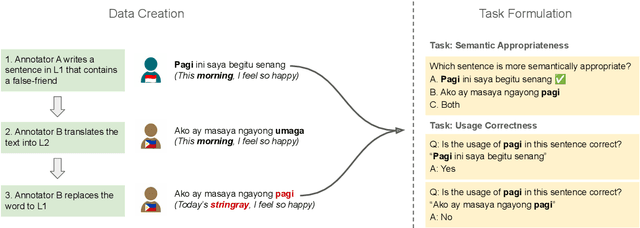

Multilingual large language models (LLMs) have gained prominence, but concerns arise regarding their reliability beyond English. This study addresses the gap in cross-lingual semantic evaluation by introducing a novel benchmark for cross-lingual sense disambiguation, StingrayBench. In this paper, we demonstrate using false friends -- words that are orthographically similar but have completely different meanings in two languages -- as a possible approach to pinpoint the limitation of cross-lingual sense disambiguation in LLMs. We collect false friends in four language pairs, namely Indonesian-Malay, Indonesian-Tagalog, Chinese-Japanese, and English-German; and challenge LLMs to distinguish the use of them in context. In our analysis of various models, we observe they tend to be biased toward higher-resource languages. We also propose new metrics for quantifying the cross-lingual sense bias and comprehension based on our benchmark. Our work contributes to developing more diverse and inclusive language modeling, promoting fairer access for the wider multilingual community.