 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic WordNet Construction using Word Sense Induction through Sentence Embeddings
Apr 07, 2022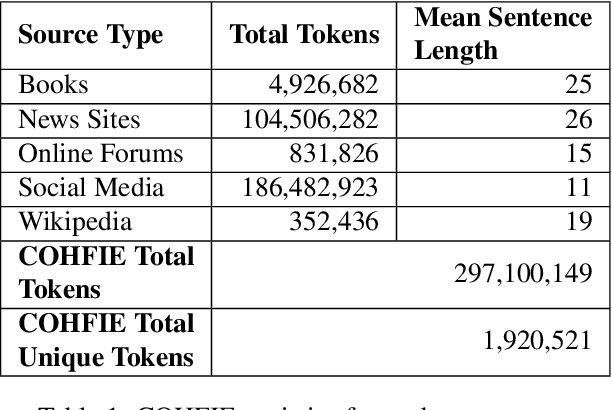
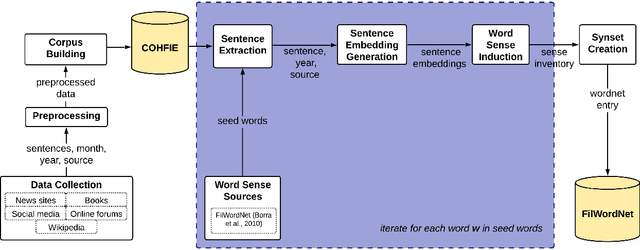
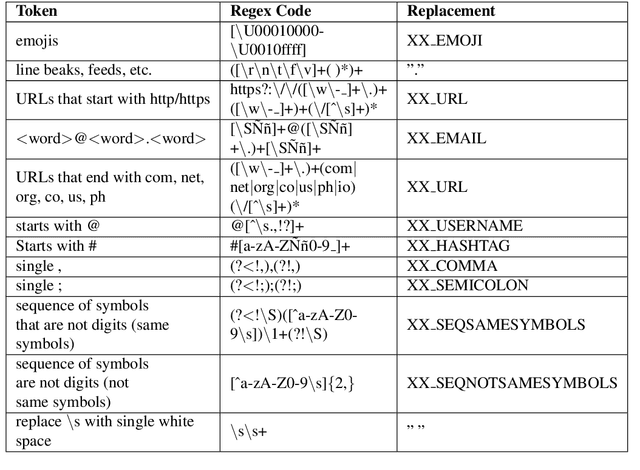
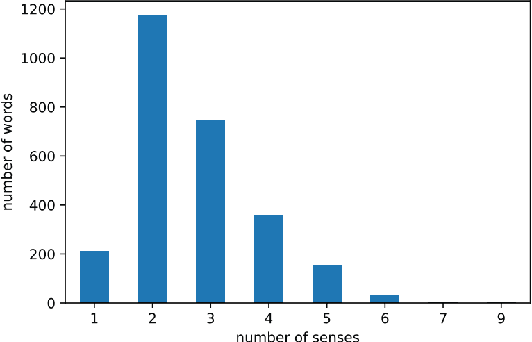
Language resources such as wordnets remain indispensable tools for different natural language tasks and applications. However, for low-resource languages such as Filipino, existing wordnets are old and outdated, and producing new ones may be slow and costly in terms of time and resources. In this paper, we propose an automatic method for constructing a wordnet from scratch using only an unlabeled corpus and a sentence embeddings-based language model. Using this, we produce FilWordNet, a new wordnet that supplants and improves the outdated Filipino WordNet. We evaluate our automatically-induced senses and synsets by matching them with senses from the Princeton WordNet, as well as comparing the synsets to the old Filipino WordNet. We empirically show that our method can induce existing, as well as potentially new, senses and synsets automatically without the need for human supervision.
Using Synthetic Data for Conversational Response Generation in Low-resource Settings
Apr 06, 2022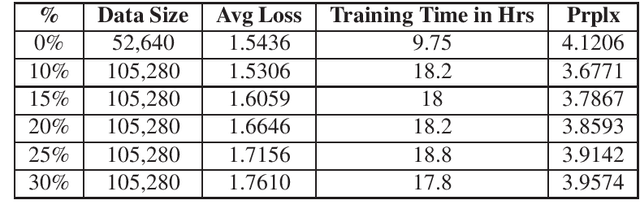
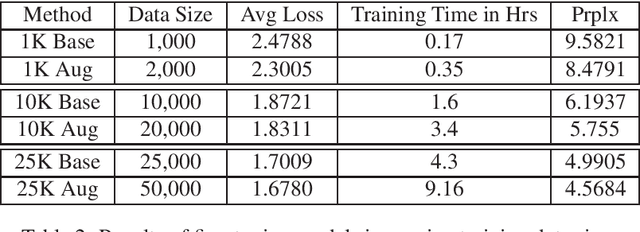
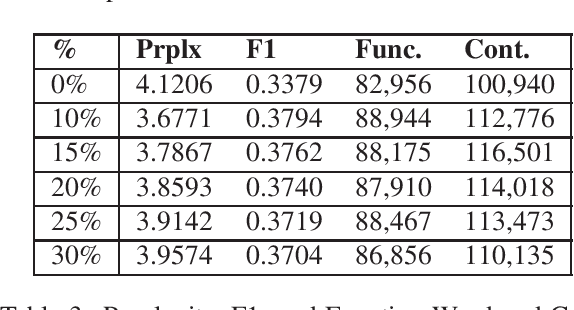
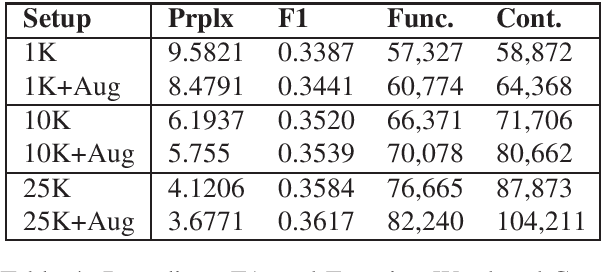
Response generation is a task in natural language processing (NLP) where a model is trained to respond to human statements. Conversational response generators take this one step further with the ability to respond within the context of previous responses. While there are existing techniques for training such models, they all require an abundance of conversational data which are not always available for low-resource languages. In this research, we make three contributions. First, we released the first Filipino conversational dataset collected from a popular Philippine online forum, which we named the PEx Conversations Dataset. Second, we introduce a data augmentation (DA) methodology for Filipino data by employing a Tagalog RoBERTa model to increase the size of the existing corpora. Lastly, we published the first Filipino conversational response generator capable of generating responses related to the previous 3 responses. With the supplementary synthetic data, we were able to improve the performance of the response generator by up to 12.2% in BERTScore, 10.7% in perplexity, and 11.7% in content word usage as compared to training with zero synthetic data.
Improving Large-scale Language Models and Resources for Filipino
Nov 11, 2021

In this paper, we improve on existing language resources for the low-resource Filipino language in two ways. First, we outline the construction of the TLUnified dataset, a large-scale pretraining corpus that serves as an improvement over smaller existing pretraining datasets for the language in terms of scale and topic variety. Second, we pretrain new Transformer language models following the RoBERTa pretraining technique to supplant existing models trained with small corpora. Our new RoBERTa models show significant improvements over existing Filipino models in three benchmark datasets with an average gain of 4.47% test accuracy across the three classification tasks of varying difficulty.
Investigating the True Performance of Transformers in Low-Resource Languages: A Case Study in Automatic Corpus Creation
Oct 22, 2020
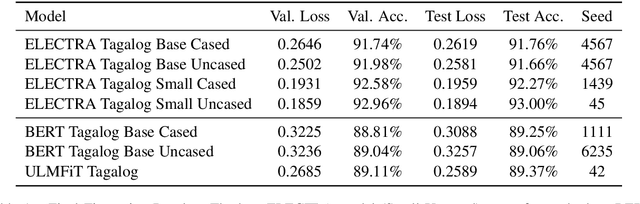
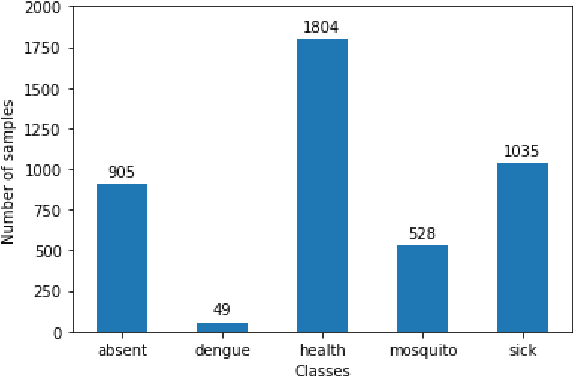
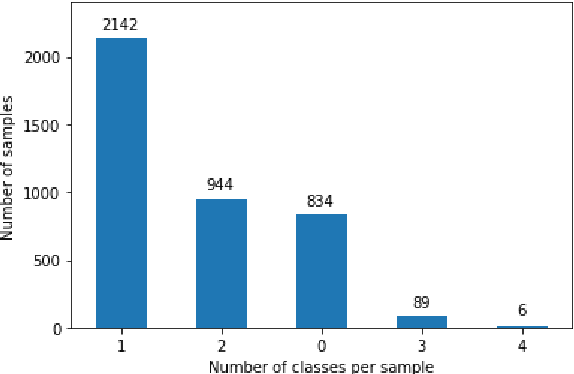
Transformers represent the state-of-the-art in Natural Language Processing (NLP) in recent years, proving effective even in tasks done in low-resource languages. While pretrained transformers for these languages can be made, it is challenging to measure their true performance and capacity due to the lack of hard benchmark datasets, as well as the difficulty and cost of producing them. In this paper, we present three contributions: First, we propose a methodology for automatically producing Natural Language Inference (NLI) benchmark datasets for low-resource languages using published news articles. Through this, we create and release NewsPH-NLI, the first sentence entailment benchmark dataset in the low-resource Filipino language. Second, we produce new pretrained transformers based on the ELECTRA technique to further alleviate the resource scarcity in Filipino, benchmarking them on our dataset against other commonly-used transfer learning techniques. Lastly, we perform analyses on transfer learning techniques to shed light on their true performance when operating in low-data domains through the use of degradation tests.
Establishing Baselines for Text Classification in Low-Resource Languages
May 05, 2020
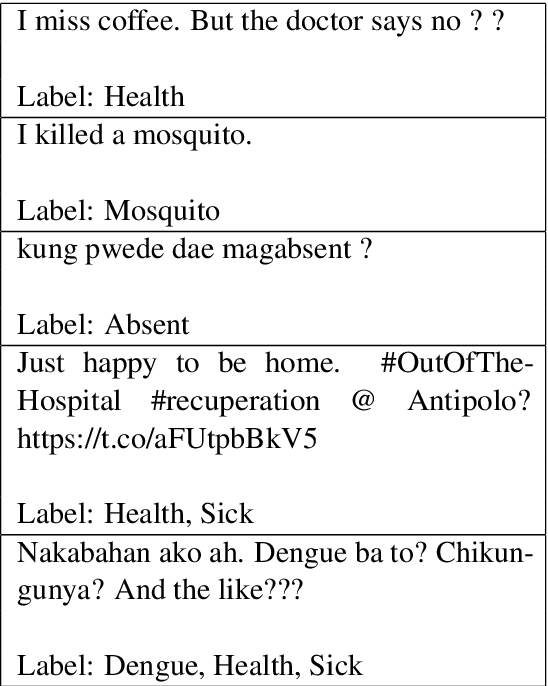
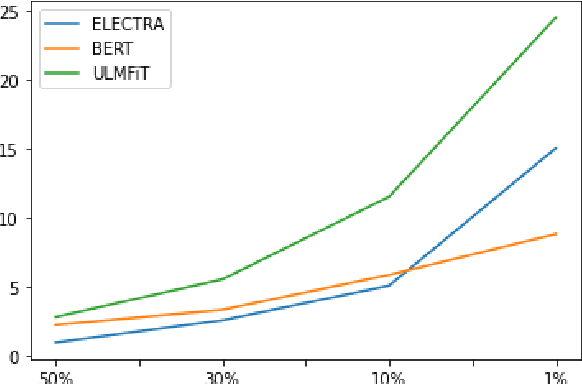
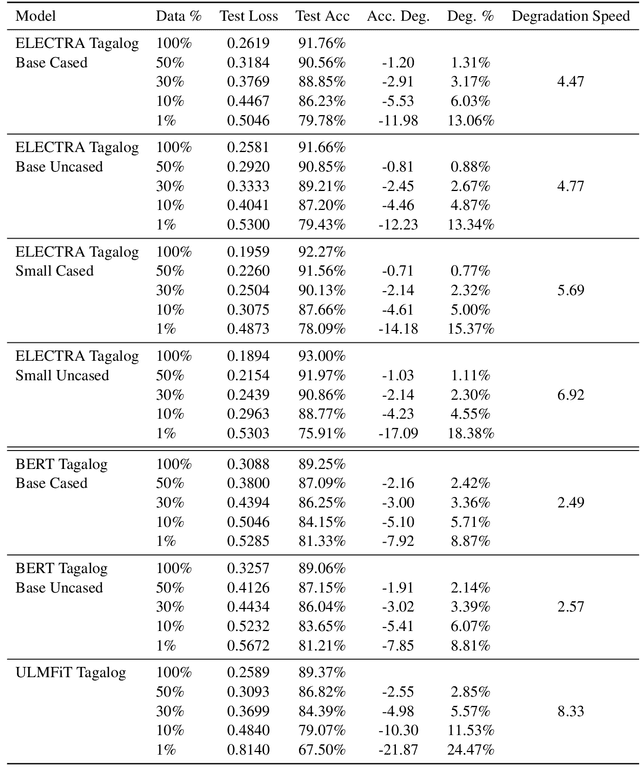
While transformer-based finetuning techniques have proven effective in tasks that involve low-resource, low-data environments, a lack of properly established baselines and benchmark datasets make it hard to compare different approaches that are aimed at tackling the low-resource setting. In this work, we provide three contributions. First, we introduce two previously unreleased datasets as benchmark datasets for text classification and low-resource multilabel text classification for the low-resource language Filipino. Second, we pretrain better BERT and DistilBERT models for use within the Filipino setting. Third, we introduce a simple degradation test that benchmarks a model's resistance to performance degradation as the number of training samples are reduced. We analyze our pretrained model's degradation speeds and look towards the use of this method for comparing models aimed at operating within the low-resource setting. We release all our models and datasets for the research community to use.
Transformer-based End-to-End Question Generation
May 03, 2020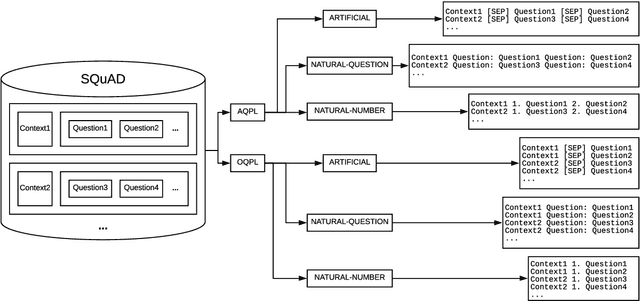
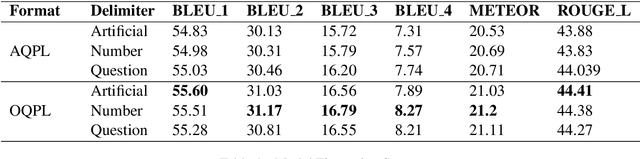

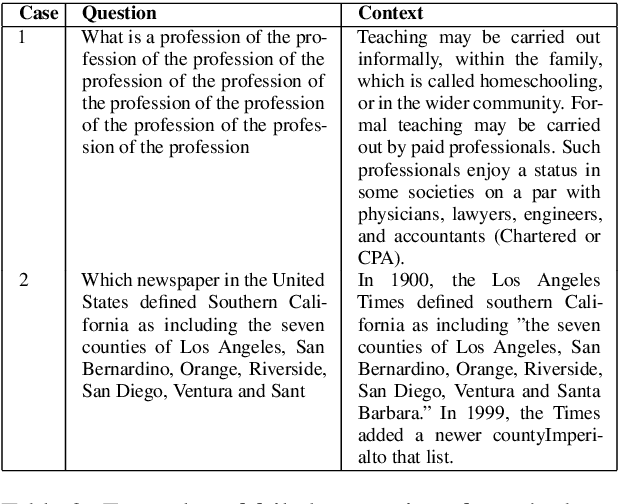
Question Generation (QG) is an important task in Natural Language Processing (NLP) that involves generating questions automatically when given a context paragraph. While many techniques exist for the task of QG, they employ complex model architectures, extensive features, and additional mechanisms to boost model performance. In this work, we show that transformer-based finetuning techniques can be used to create robust question generation systems using only a single pretrained language model, without the use of additional mechanisms, answer metadata, and extensive features. Our best model outperforms previous more complex RNN-based Seq2Seq models, with an 8.62 and a 14.27 increase in METEOR and ROUGE_L scores, respectively. We show that it also performs on par with Seq2Seq models that employ answer-awareness and other special mechanisms, despite being only a single-model system. We analyze how various factors affect the model's performance, such as input data formatting, the length of the context paragraphs, and the use of answer-awareness. In addition, we also look into the modes of failure that the model experiences and identify the reasons why it fails.
Localization of Fake News Detection via Multitask Transfer Learning
Oct 30, 2019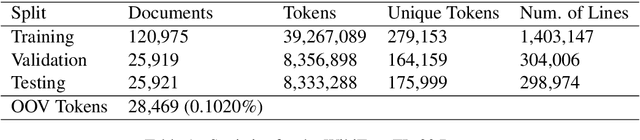
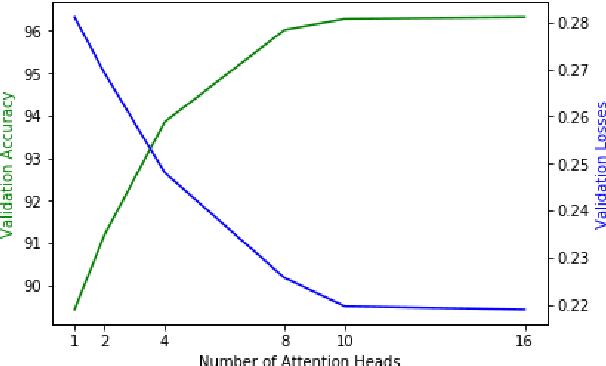

The use of the internet as a fast medium of spreading fake news reinforces the need for computational tools that combat it. Techniques that train fake news classifiers exist, but they all assume an abundance of resources including large labeled datasets and expert-curated corpora, which low-resource languages may not have. In this paper, we show that Transfer Learning (TL) can be used to train robust fake news classifiers from little data, achieving 91% accuracy on a fake news dataset in the low-resourced Filipino language, reducing the error by 14% compared to established few-shot baselines. Furthermore, lifting ideas from multitask learning, we show that augmenting transformer-based transfer techniques with auxiliary language modeling losses improves their performance by adapting to stylometry. Using this, we improve TL performance by 4-6%, achieving an accuracy of 96% on our best model. We perform ablations that establish the causality of attention-based TL techniques to state-of-the-art results, as well as the model's capability to learn and predict via stylometry. Lastly, we show that our method generalizes well to different types of news articles, including political news, entertainment news, and opinion articles.
Evaluating Language Model Finetuning Techniques for Low-resource Languages
Jun 30, 2019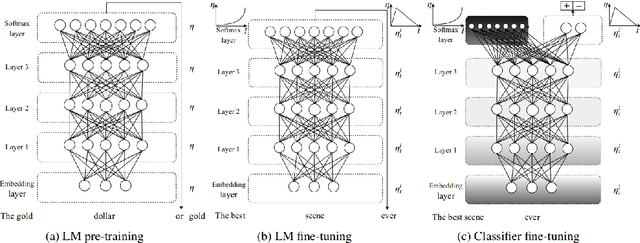

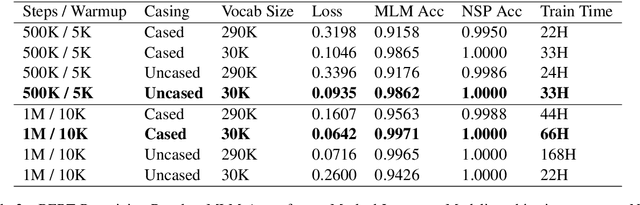
Unlike mainstream languages (such as English and French), low-resource languages often suffer from a lack of expert-annotated corpora and benchmark resources that make it hard to apply state-of-the-art techniques directly. In this paper, we alleviate this scarcity problem for the low-resourced Filipino language in two ways. First, we introduce a new benchmark language modeling dataset in Filipino which we call WikiText-TL-39. Second, we show that language model finetuning techniques such as BERT and ULMFiT can be used to consistently train robust classifiers in low-resource settings, experiencing at most a 0.0782 increase in validation error when the number of training examples is decreased from 10K to 1K while finetuning using a privately-held sentiment dataset.