 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the True Performance of Transformers in Low-Resource Languages: A Case Study in Automatic Corpus Creation
Oct 22, 2020
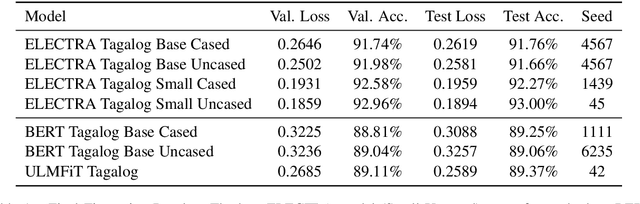
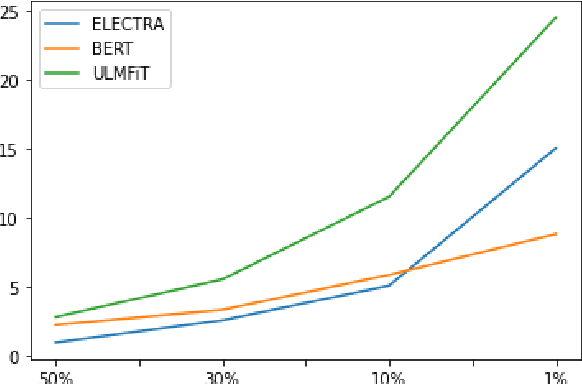
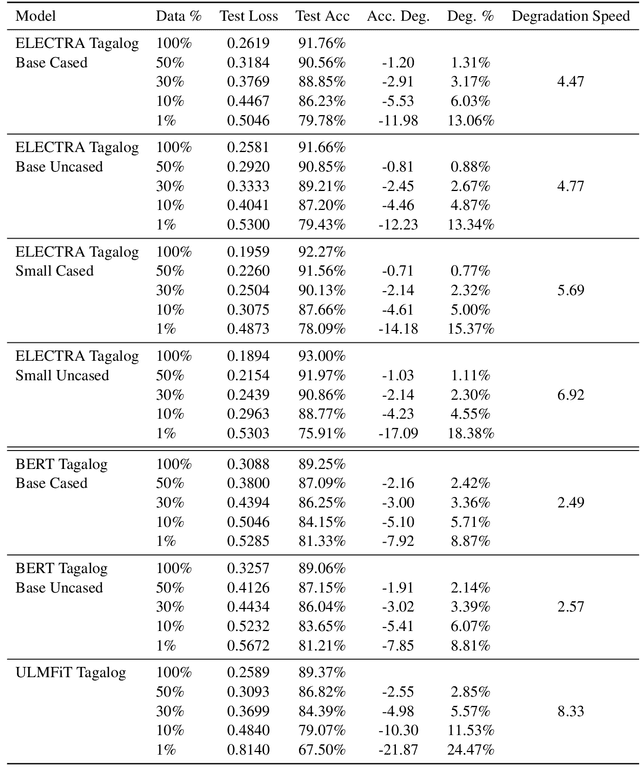
Transformers represent the state-of-the-art in Natural Language Processing (NLP) in recent years, proving effective even in tasks done in low-resource languages. While pretrained transformers for these languages can be made, it is challenging to measure their true performance and capacity due to the lack of hard benchmark datasets, as well as the difficulty and cost of producing them. In this paper, we present three contributions: First, we propose a methodology for automatically producing Natural Language Inference (NLI) benchmark datasets for low-resource languages using published news articles. Through this, we create and release NewsPH-NLI, the first sentence entailment benchmark dataset in the low-resource Filipino language. Second, we produce new pretrained transformers based on the ELECTRA technique to further alleviate the resource scarcity in Filipino, benchmarking them on our dataset against other commonly-used transfer learning techniques. Lastly, we perform analyses on transfer learning techniques to shed light on their true performance when operating in low-data domains through the use of degradation tests.
Training Keyword Spotters with Limited and Synthesized Speech Data
Jan 31, 2020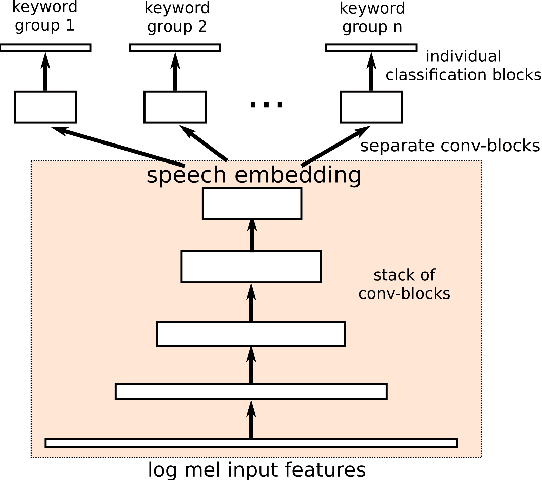
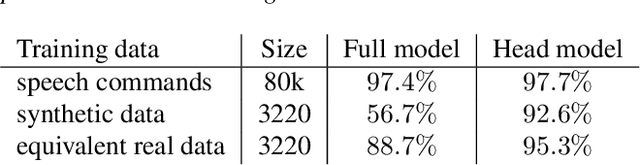
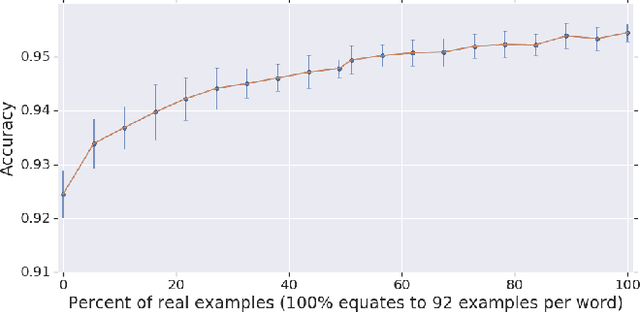
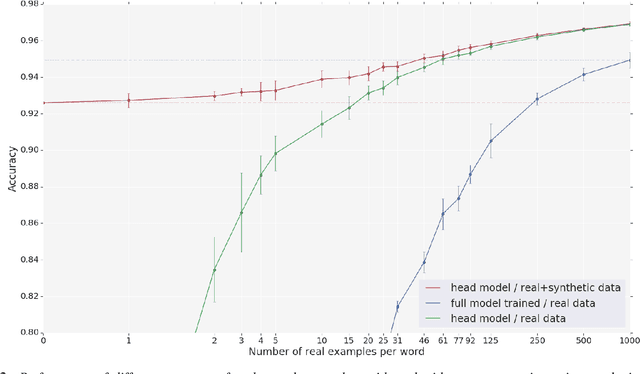
With the rise of low power speech-enabled devices, there is a growing demand to quickly produce models for recognizing arbitrary sets of keywords. As with many machine learning tasks, one of the most challenging parts in the model creation process is obtaining a sufficient amount of training data. In this paper, we explore the effectiveness of synthesized speech data in training small, spoken term detection models of around 400k parameters. Instead of training such models directly on the audio or low level features such as MFCCs, we use a pre-trained speech embedding model trained to extract useful features for keyword spotting models. Using this speech embedding, we show that a model which detects 10 keywords when trained on only synthetic speech is equivalent to a model trained on over 500 real examples. We also show that a model without our speech embeddings would need to be trained on over 4000 real examples to reach the same accuracy.