 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Keyword Spotters with Limited and Synthesized Speech Data
Jan 31, 2020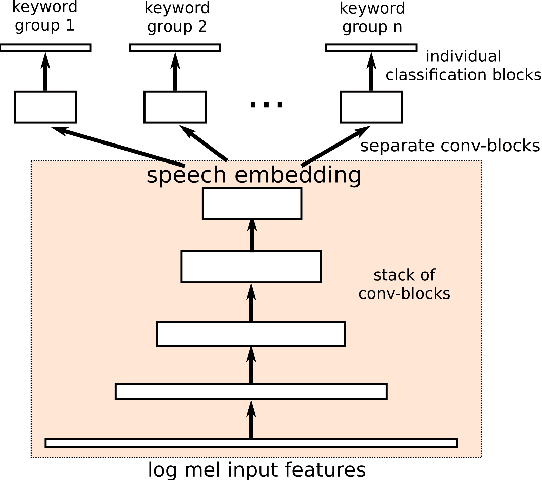
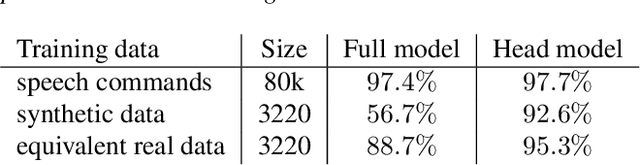
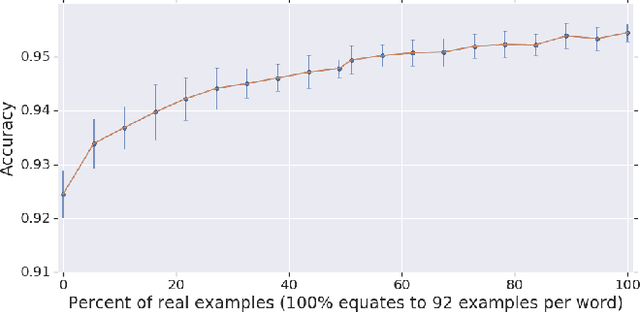
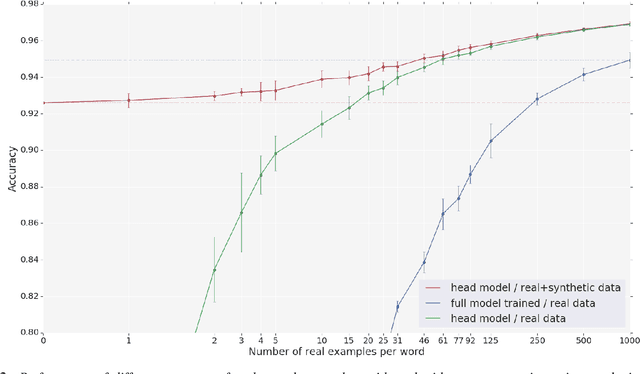
With the rise of low power speech-enabled devices, there is a growing demand to quickly produce models for recognizing arbitrary sets of keywords. As with many machine learning tasks, one of the most challenging parts in the model creation process is obtaining a sufficient amount of training data. In this paper, we explore the effectiveness of synthesized speech data in training small, spoken term detection models of around 400k parameters. Instead of training such models directly on the audio or low level features such as MFCCs, we use a pre-trained speech embedding model trained to extract useful features for keyword spotting models. Using this speech embedding, we show that a model which detects 10 keywords when trained on only synthetic speech is equivalent to a model trained on over 500 real examples. We also show that a model without our speech embeddings would need to be trained on over 4000 real examples to reach the same accuracy.
Low-Dimensional Bottleneck Features for On-Device Continuous Speech Recognition
Oct 31, 2018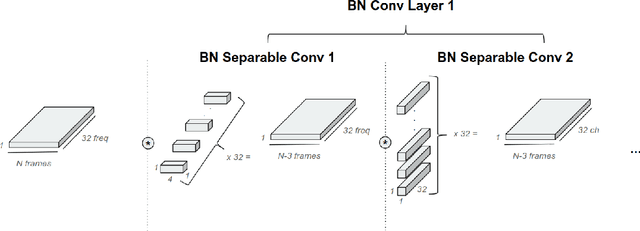

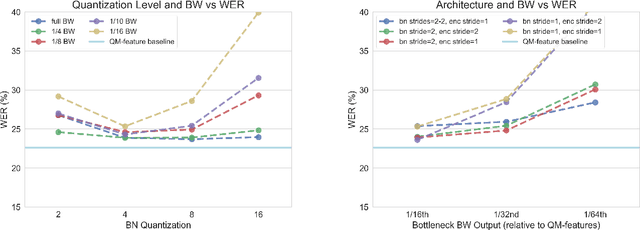
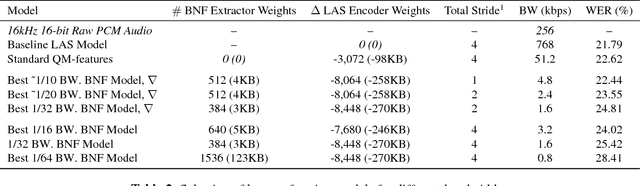
Low power digital signal processors (DSPs) typically have a very limited amount of memory in which to cache data. In this paper we develop efficient bottleneck feature (BNF) extractors that can be run on a DSP, and retrain a baseline large-vocabulary continuous speech recognition (LVCSR) system to use these BNFs with only a minimal loss of accuracy. The small BNFs allow the DSP chip to cache more audio features while the main application processor is suspended, thereby reducing the overall battery usage. Our presented system is able to reduce the footprint of standard, fixed point DSP spectral features by a factor of 10 without any loss in word error rate (WER) and by a factor of 64 with only a 5.8% relative increase in WER.
Now Playing: Continuous low-power music recognition
Nov 29, 2017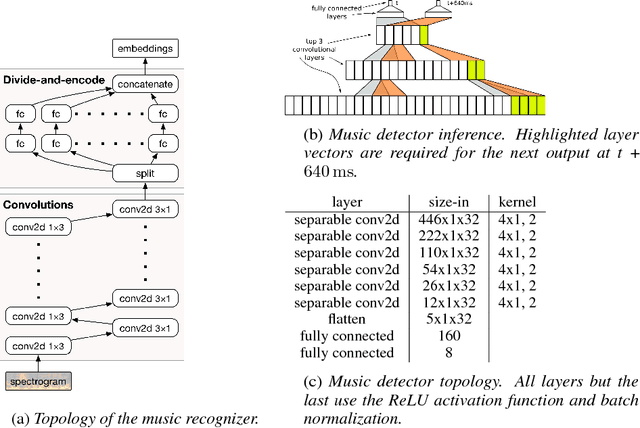
Existing music recognition applications require a connection to a server that performs the actual recognition. In this paper we present a low-power music recognizer that runs entirely on a mobile device and automatically recognizes music without user interaction. To reduce battery consumption, a small music detector runs continuously on the mobile device's DSP chip and wakes up the main application processor only when it is confident that music is present. Once woken, the recognizer on the application processor is provided with a few seconds of audio which is fingerprinted and compared to the stored fingerprints in the on-device fingerprint database of tens of thousands of songs. Our presented system, Now Playing, has a daily battery usage of less than 1% on average, respects user privacy by running entirely on-device and can passively recognize a wide range of music.