 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCU400: An Annotated Dataset for Exploring Aural Phenomenology Through Causal Uncertainty
Nov 15, 2018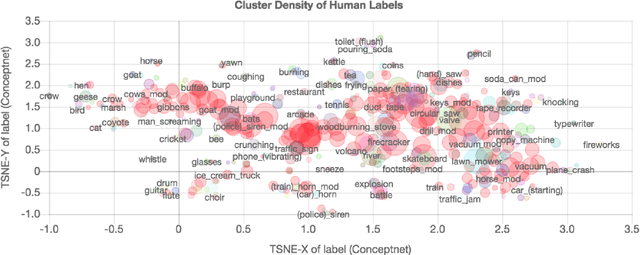
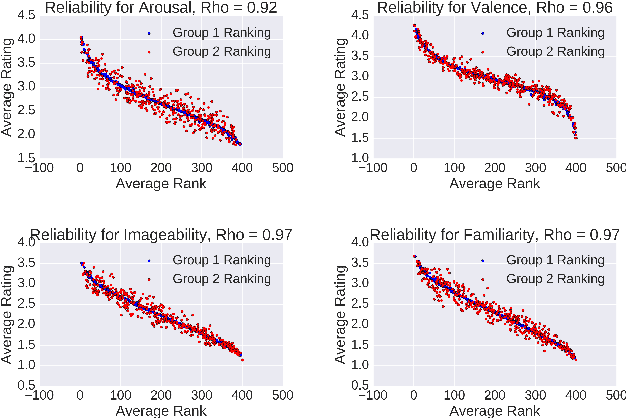
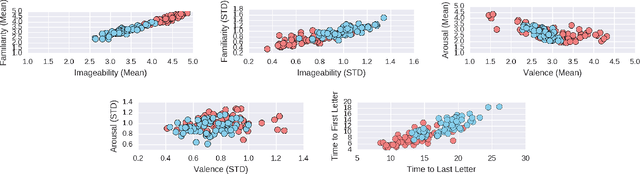
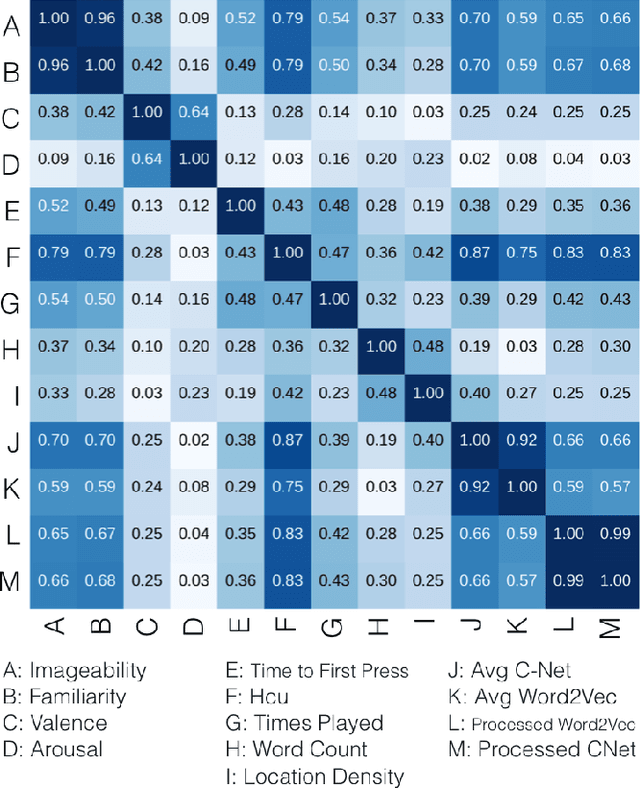
The way we perceive a sound depends on many aspects-- its ecological frequency, acoustic features, typicality, and most notably, its identified source. In this paper, we present the HCU400: a dataset of 402 sounds ranging from easily identifiable everyday sounds to intentionally obscured artificial ones. It aims to lower the barrier for the study of aural phenomenology as the largest available audio dataset to include an analysis of causal attribution. Each sample has been annotated with crowd-sourced descriptions, as well as familiarity, imageability, arousal, and valence ratings. We extend existing calculations of causal uncertainty, automating and generalizing them with word embeddings. Upon analysis we find that individuals will provide less polarized emotion ratings as a sound's source becomes increasingly ambiguous; individual ratings of familiarity and imageability, on the other hand, diverge as uncertainty increases despite a clear negative trend on average.
Low-Dimensional Bottleneck Features for On-Device Continuous Speech Recognition
Oct 31, 2018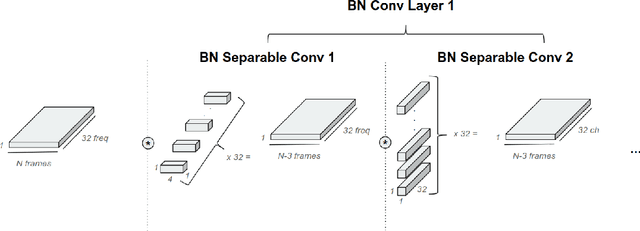

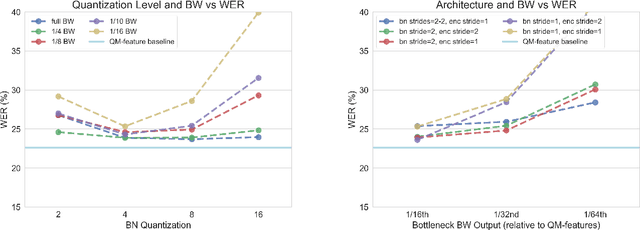
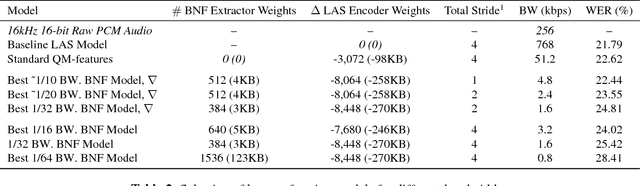
Low power digital signal processors (DSPs) typically have a very limited amount of memory in which to cache data. In this paper we develop efficient bottleneck feature (BNF) extractors that can be run on a DSP, and retrain a baseline large-vocabulary continuous speech recognition (LVCSR) system to use these BNFs with only a minimal loss of accuracy. The small BNFs allow the DSP chip to cache more audio features while the main application processor is suspended, thereby reducing the overall battery usage. Our presented system is able to reduce the footprint of standard, fixed point DSP spectral features by a factor of 10 without any loss in word error rate (WER) and by a factor of 64 with only a 5.8% relative increase in WER.