 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCU400: An Annotated Dataset for Exploring Aural Phenomenology Through Causal Uncertainty
Paper and Code
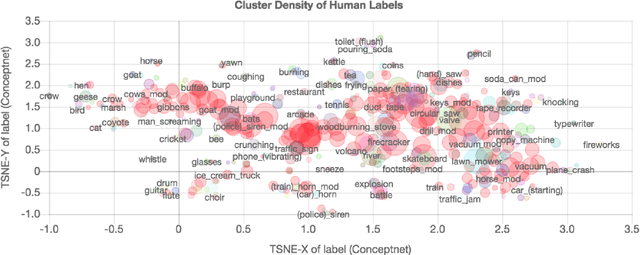
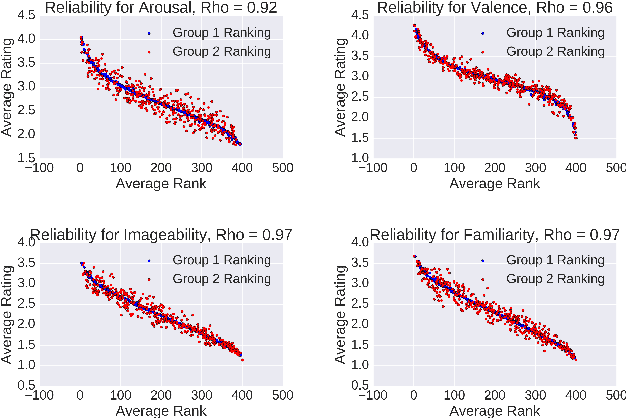
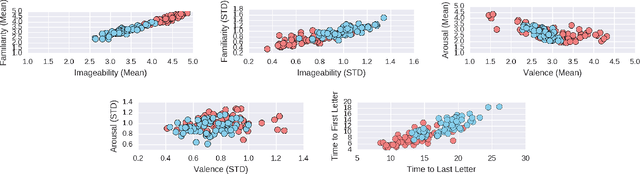
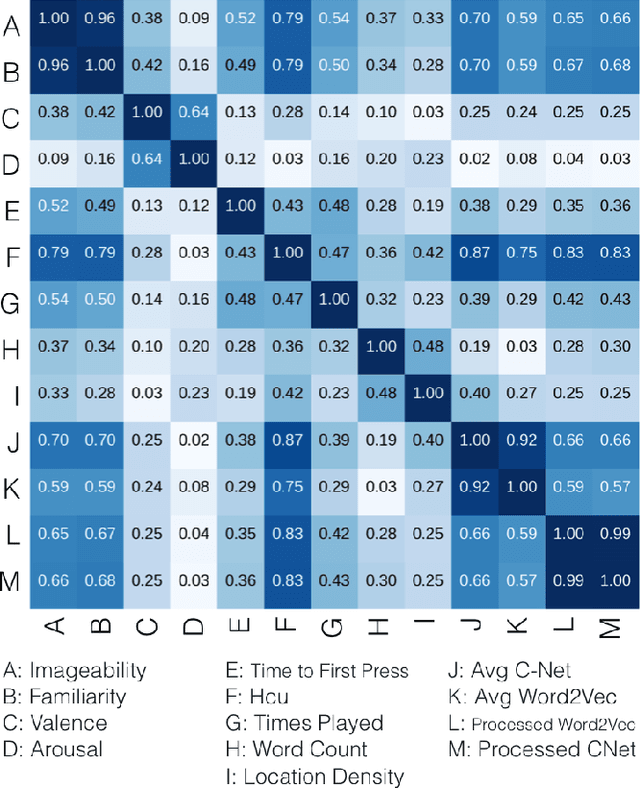
The way we perceive a sound depends on many aspects-- its ecological frequency, acoustic features, typicality, and most notably, its identified source. In this paper, we present the HCU400: a dataset of 402 sounds ranging from easily identifiable everyday sounds to intentionally obscured artificial ones. It aims to lower the barrier for the study of aural phenomenology as the largest available audio dataset to include an analysis of causal attribution. Each sample has been annotated with crowd-sourced descriptions, as well as familiarity, imageability, arousal, and valence ratings. We extend existing calculations of causal uncertainty, automating and generalizing them with word embeddings. Upon analysis we find that individuals will provide less polarized emotion ratings as a sound's source becomes increasingly ambiguous; individual ratings of familiarity and imageability, on the other hand, diverge as uncertainty increases despite a clear negative trend on average.