 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synthetic Data for Conversational Response Generation in Low-resource Settings
Apr 06, 2022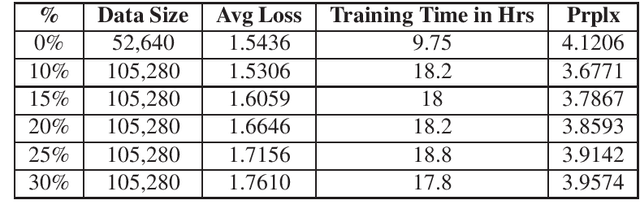
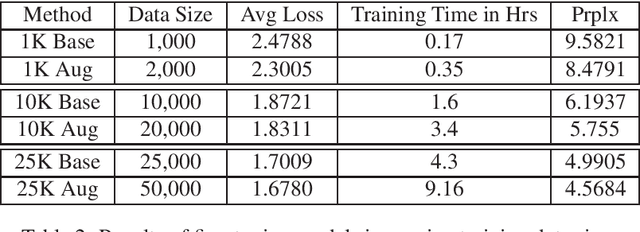
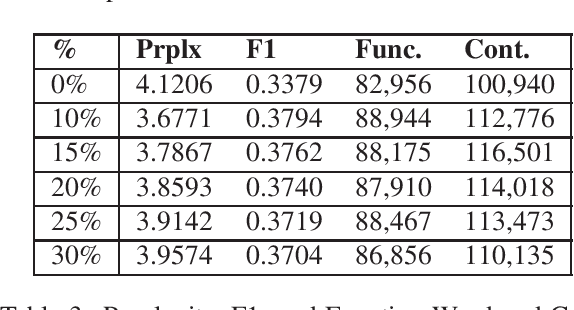
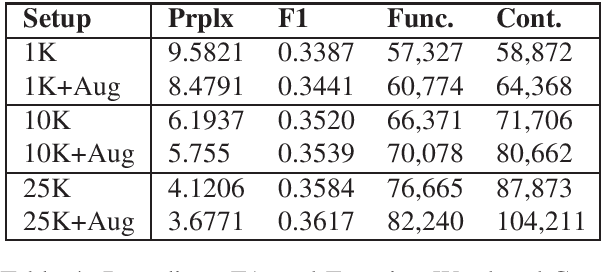
Response generation is a task in natural language processing (NLP) where a model is trained to respond to human statements. Conversational response generators take this one step further with the ability to respond within the context of previous responses. While there are existing techniques for training such models, they all require an abundance of conversational data which are not always available for low-resource languages. In this research, we make three contributions. First, we released the first Filipino conversational dataset collected from a popular Philippine online forum, which we named the PEx Conversations Dataset. Second, we introduce a data augmentation (DA) methodology for Filipino data by employing a Tagalog RoBERTa model to increase the size of the existing corpora. Lastly, we published the first Filipino conversational response generator capable of generating responses related to the previous 3 responses. With the supplementary synthetic data, we were able to improve the performance of the response generator by up to 12.2% in BERTScore, 10.7% in perplexity, and 11.7% in content word usage as compared to training with zero synthetic data.