 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization of Fake News Detection via Multitask Transfer Learning
Paper and Code
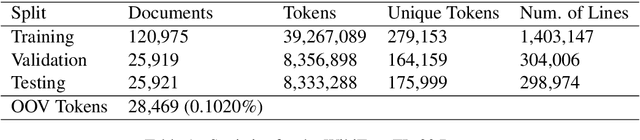
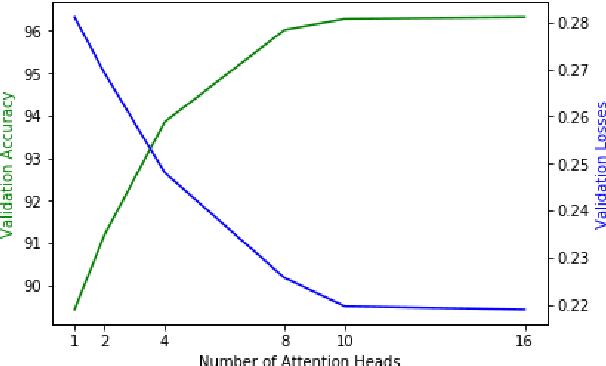

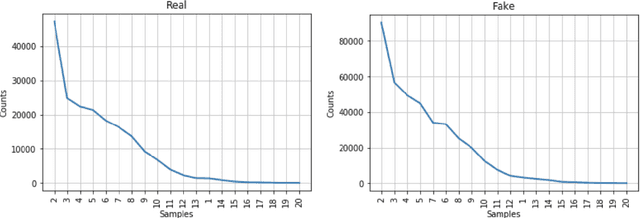
The use of the internet as a fast medium of spreading fake news reinforces the need for computational tools that combat it. Techniques that train fake news classifiers exist, but they all assume an abundance of resources including large labeled datasets and expert-curated corpora, which low-resource languages may not have. In this paper, we show that Transfer Learning (TL) can be used to train robust fake news classifiers from little data, achieving 91% accuracy on a fake news dataset in the low-resourced Filipino language, reducing the error by 14% compared to established few-shot baselines. Furthermore, lifting ideas from multitask learning, we show that augmenting transformer-based transfer techniques with auxiliary language modeling losses improves their performance by adapting to stylometry. Using this, we improve TL performance by 4-6%, achieving an accuracy of 96% on our best model. We perform ablations that establish the causality of attention-based TL techniques to state-of-the-art results, as well as the model's capability to learn and predict via stylometry. Lastly, we show that our method generalizes well to different types of news articles, including political news, entertainment news, and opinion articles.