Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Large-scale Language Models and Resources for Filipino
Paper and Code
Nov 11, 2021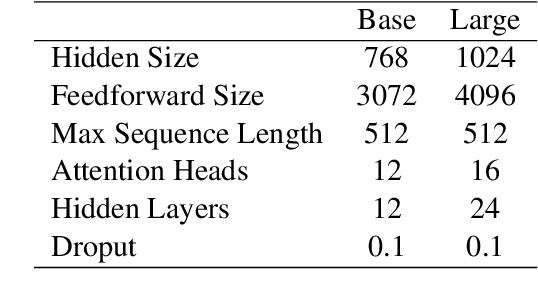

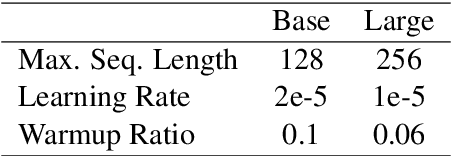
In this paper, we improve on existing language resources for the low-resource Filipino language in two ways. First, we outline the construction of the TLUnified dataset, a large-scale pretraining corpus that serves as an improvement over smaller existing pretraining datasets for the language in terms of scale and topic variety. Second, we pretrain new Transformer language models following the RoBERTa pretraining technique to supplant existing models trained with small corpora. Our new RoBERTa models show significant improvements over existing Filipino models in three benchmark datasets with an average gain of 4.47% test accuracy across the three classification tasks of varying difficulty.
* Resources are available at blaisecruz.com/resources
View paper on