Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Selection's Disparate Impact in Real-World Deep Learning Applications
Paper and Code
Apr 01, 2021
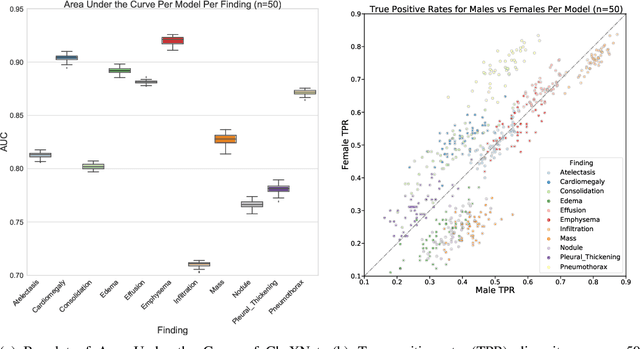
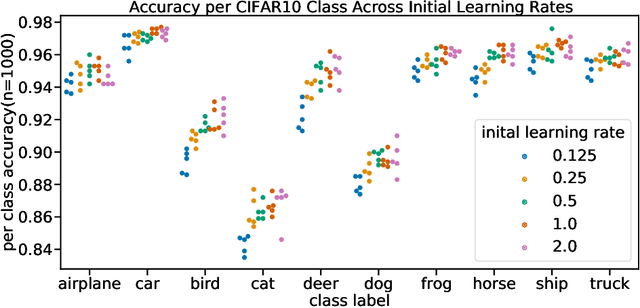
Algorithmic fairness has emphasized the role of biased data in automated decision outcomes. Recently, there has been a shift in attention to sources of bias that implicate fairness in other stages in the ML pipeline. We contend that one source of such bias, human preferences in model selection, remains under-explored in terms of its role in disparate impact across demographic groups. Using a deep learning model trained on real-world medical imaging data, we verify our claim empirically and argue that choice of metric for model comparison can significantly bias model selection outcomes.
* Accepted to the Science and Engineering of Deep Learning Workshop,
ICLR 2021
View paper on