 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Downstream Fairness with Geometric Repair
Mar 14, 2022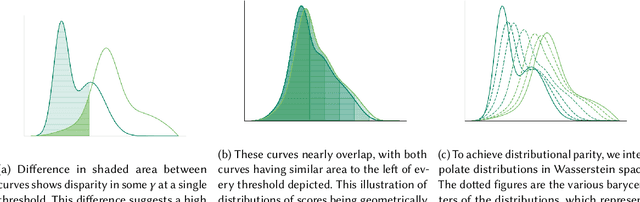
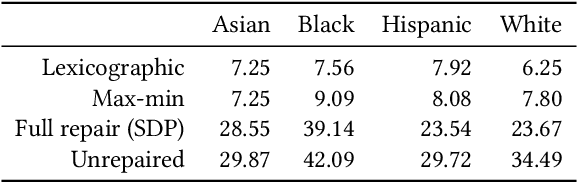
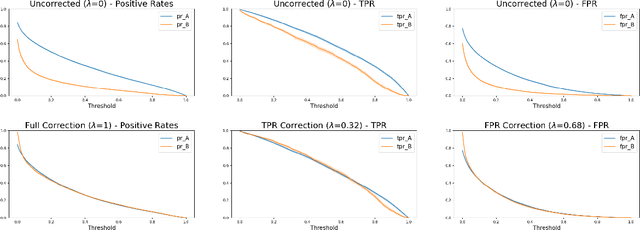

Consider a scenario where some upstream model developer must train a fair model, but is unaware of the fairness requirements of a downstream model user or stakeholder. In the context of fair classification, we present a technique that specifically addresses this setting, by post-processing a regressor's scores such they yield fair classifications for any downstream choice in decision threshold. To begin, we leverage ideas from optimal transport to show how this can be achieved for binary protected groups across a broad class of fairness metrics. Then, we extend our approach to address the setting where a protected attribute takes on multiple values, by re-recasting our technique as a convex optimization problem that leverages lexicographic fairness.
Model Selection's Disparate Impact in Real-World Deep Learning Applications
Apr 01, 2021
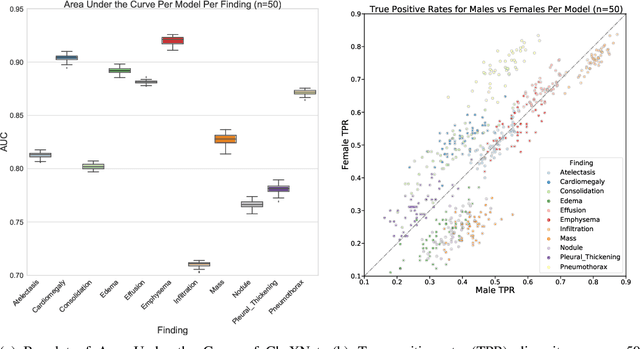
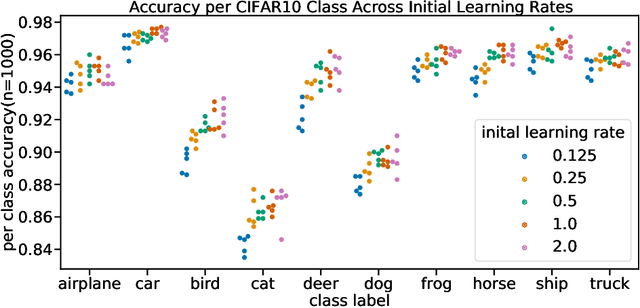
Algorithmic fairness has emphasized the role of biased data in automated decision outcomes. Recently, there has been a shift in attention to sources of bias that implicate fairness in other stages in the ML pipeline. We contend that one source of such bias, human preferences in model selection, remains under-explored in terms of its role in disparate impact across demographic groups. Using a deep learning model trained on real-world medical imaging data, we verify our claim empirically and argue that choice of metric for model comparison can significantly bias model selection outcomes.
Everything is Relative: Understanding Fairness with Optimal Transport
Feb 20, 2021
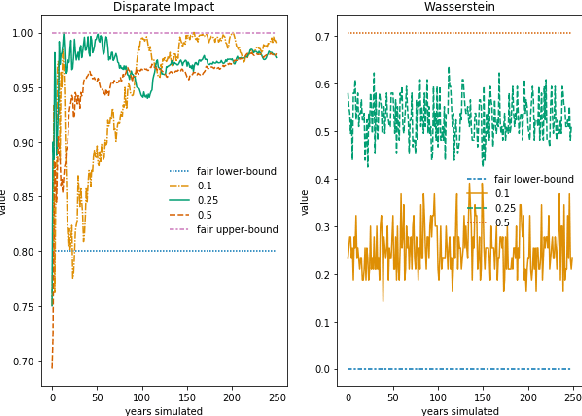


To study discrimination in automated decision-making systems, scholars have proposed several definitions of fairness, each expressing a different fair ideal. These definitions require practitioners to make complex decisions regarding which notion to employ and are often difficult to use in practice since they make a binary judgement a system is fair or unfair instead of explaining the structure of the detected unfairness. We present an optimal transport-based approach to fairness that offers an interpretable and quantifiable exploration of bias and its structure by comparing a pair of outcomes to one another. In this work, we use the optimal transport map to examine individual, subgroup, and group fairness. Our framework is able to recover well known examples of algorithmic discrimination, detect unfairness when other metrics fail, and explore recourse opportunities.