 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatio-Temporal Dynamics for Trajectory Recovery via Time-Aware Transformer
May 20, 2025In real-world applications, GPS trajectories often suffer from low sampling rates, with large and irregular intervals between consecutive GPS points. This sparse characteristic presents challenges for their direct use in GPS-based systems. This paper addresses the task of map-constrained trajectory recovery, aiming to enhance trajectory sampling rates of GPS trajectories. Previous studies commonly adopt a sequence-to-sequence framework, where an encoder captures the trajectory patterns and a decoder reconstructs the target trajectory. Within this framework, effectively representing the road network and extracting relevant trajectory features are crucial for overall performance. Despite advancements in these models, they fail to fully leverage the complex spatio-temporal dynamics present in both the trajectory and the road network. To overcome these limitations, we categorize the spatio-temporal dynamics of trajectory data into two distinct aspects: spatial-temporal traffic dynamics and trajectory dynamics. Furthermore, We propose TedTrajRec, a novel method for trajectory recovery. To capture spatio-temporal traffic dynamics, we introduce PD-GNN, which models periodic patterns and learns topologically aware dynamics concurrently for each road segment. For spatio-temporal trajectory dynamics, we present TedFormer, a time-aware Transformer that incorporates temporal dynamics for each GPS location by integrating closed-form neural ordinary differential equations into the attention mechanism. This allows TedFormer to effectively handle irregularly sampled data. Extensive experiments on three real-world datasets demonstrate the superior performance of TedTrajRec. The code is publicly available at https://github.com/ysygMhdxw/TEDTrajRec/.
RNTrajRec: Road Network Enhanced Trajectory Recovery with Spatial-Temporal Transformer
Nov 28, 2022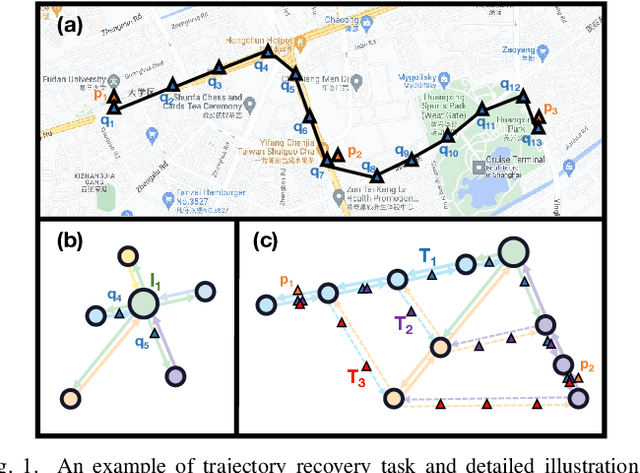
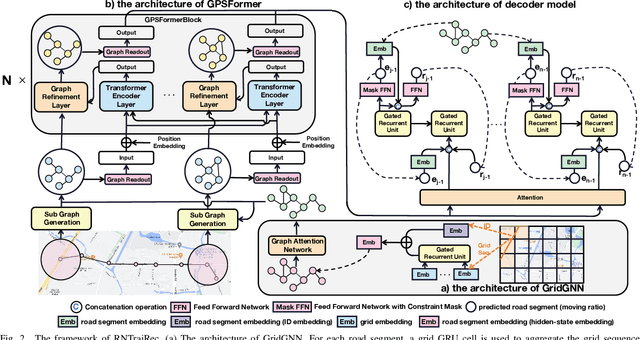
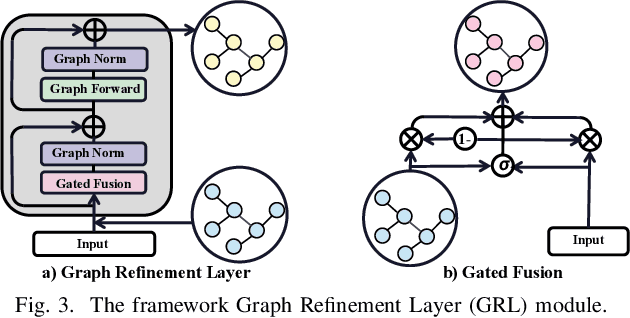
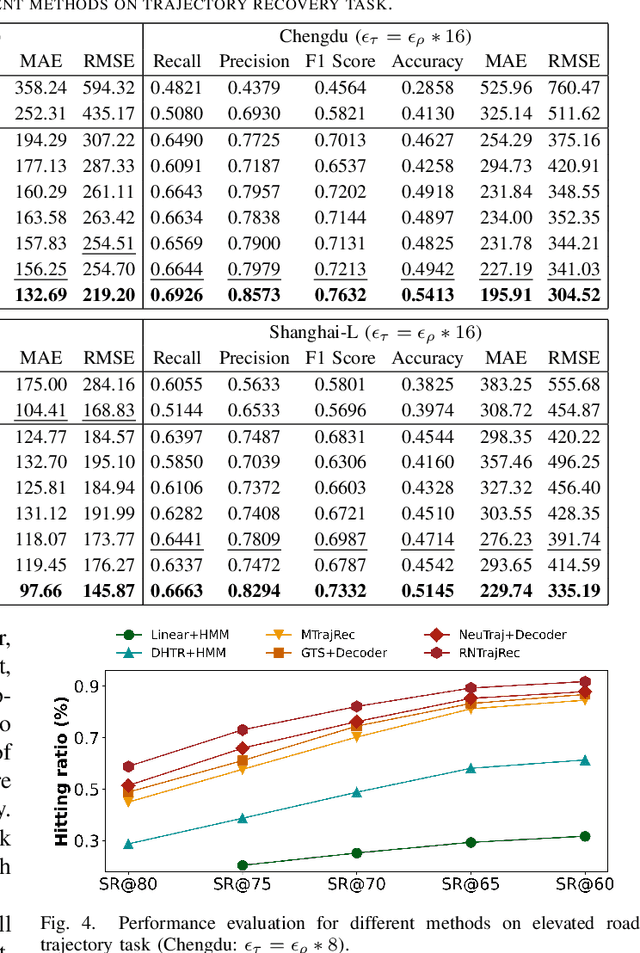
GPS trajectories are the essential foundations for many trajectory-based applications, such as travel time estimation, traffic prediction and trajectory similarity measurement. Most applications require a large amount of high sample rate trajectories to achieve a good performance. However, many real-life trajectories are collected with low sample rate due to energy concern or other constraints.We study the task of trajectory recovery in this paper as a means for increasing the sample rate of low sample trajectories. Currently, most existing works on trajectory recovery follow a sequence-to-sequence diagram, with an encoder to encode a trajectory and a decoder to recover real GPS points in the trajectory. However, these works ignore the topology of road network and only use grid information or raw GPS points as input. Therefore, the encoder model is not able to capture rich spatial information of the GPS points along the trajectory, making the prediction less accurate and lack spatial consistency. In this paper, we propose a road network enhanced transformer-based framework, namely RNTrajRec, for trajectory recovery. RNTrajRec first uses a graph model, namely GridGNN, to learn the embedding features of each road segment. It next develops a spatial-temporal transformer model, namely GPSFormer, to learn rich spatial and temporal features along with a Sub-Graph Generation module to capture the spatial features for each GPS point in the trajectory. It finally forwards the outputs of encoder model into a multi-task decoder model to recover the missing GPS points. Extensive experiments based on three large-scale real-life trajectory datasets confirm the effectiveness of our approach.
Adaptive Structural Similarity Preserving for Unsupervised Cross Modal Hashing
Jul 09, 2022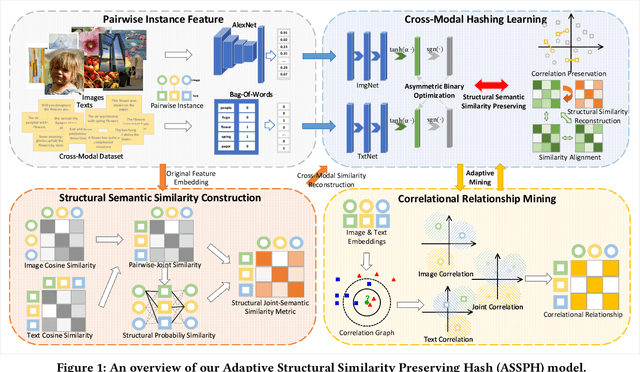
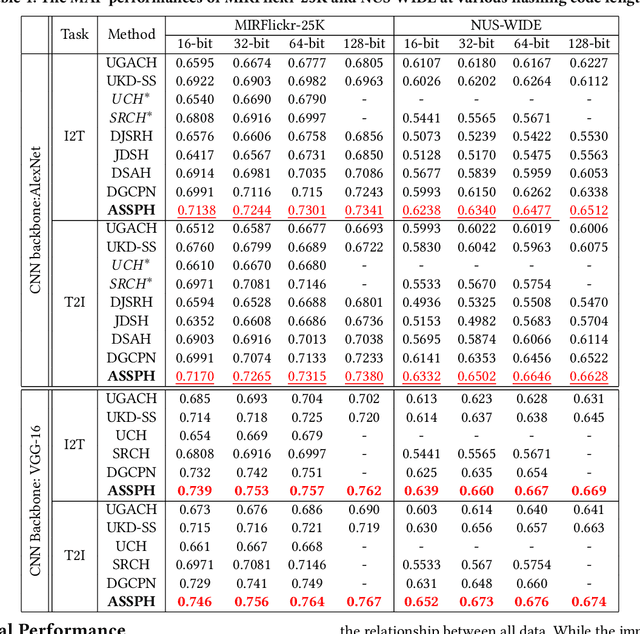
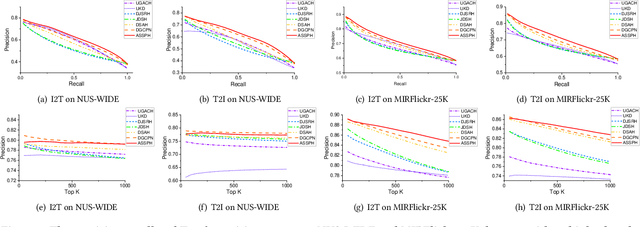
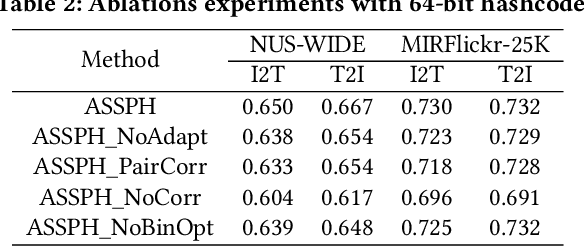
Cross-modal hashing is an important approach for multimodal data management and application. Existing unsupervised cross-modal hashing algorithms mainly rely on data features in pre-trained models to mine their similarity relationships. However, their optimization objectives are based on the static metric between the original uni-modal features, without further exploring data correlations during the training. In addition, most of them mainly focus on association mining and alignment among pairwise instances in continuous space but ignore the latent structural correlations contained in the semantic hashing space. In this paper, we propose an unsupervised hash learning framework, namely Adaptive Structural Similarity Preservation Hashing (ASSPH), to solve the above problems. Firstly, we propose an adaptive learning scheme, with limited data and training batches, to enrich semantic correlations of unlabeled instances during the training process and meanwhile to ensure a smooth convergence of the training process. Secondly, we present an asymmetric structural semantic representation learning scheme. We introduce structural semantic metrics based on graph adjacency relations during the semantic reconstruction and correlation mining stage and meanwhile align the structure semantics in the hash space with an asymmetric binary optimization process. Finally, we conduct extensive experiments to validate the enhancements of our work in comparison with existing works.
Multi-Agent Reinforcement Learning for Traffic Signal Control through Universal Communication Method
Apr 26, 2022
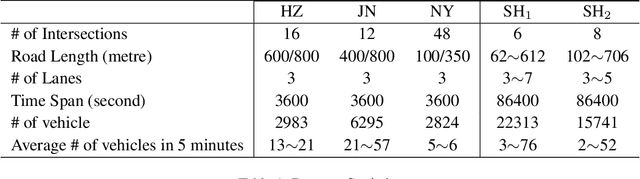
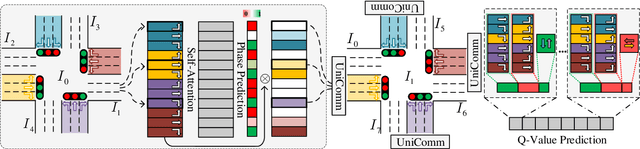
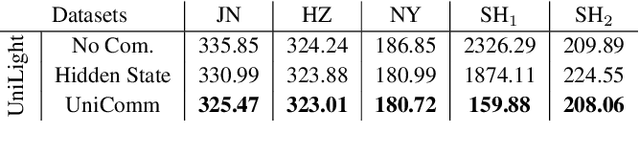
How to coordinate the communication among intersections effectively in real complex traffic scenarios with multi-intersection is challenging. Existing approaches only enable the communication in a heuristic manner without considering the content/importance of information to be shared. In this paper, we propose a universal communication form UniComm between intersections. UniComm embeds massive observations collected at one agent into crucial predictions of their impact on its neighbors, which improves the communication efficiency and is universal across existing methods. We also propose a concise network UniLight to make full use of communications enabled by UniComm. Experimental results on real datasets demonstrate that UniComm universally improves the performance of existing state-of-the-art methods, and UniLight significantly outperforms existing methods on a wide range of traffic situations.
Self-Guided Learning to Denoise for Robust Recommendation
Apr 14, 2022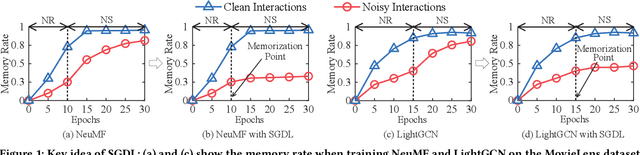
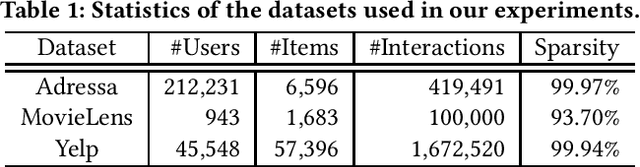
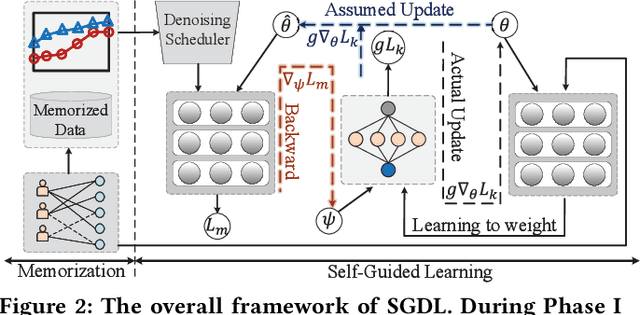
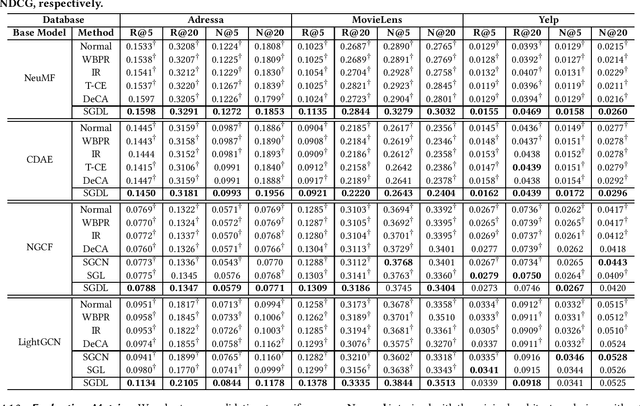
The ubiquity of implicit feedback makes them the default choice to build modern recommender systems. Generally speaking, observed interactions are considered as positive samples, while unobserved interactions are considered as negative ones. However, implicit feedback is inherently noisy because of the ubiquitous presence of noisy-positive and noisy-negative interactions. Recently, some studies have noticed the importance of denoising implicit feedback for recommendations, and enhanced the robustness of recommendation models to some extent. Nonetheless, they typically fail to (1) capture the hard yet clean interactions for learning comprehensive user preference, and (2) provide a universal denoising solution that can be applied to various kinds of recommendation models. In this paper, we thoroughly investigate the memorization effect of recommendation models, and propose a new denoising paradigm, i.e., Self-Guided Denoising Learning (SGDL), which is able to collect memorized interactions at the early stage of the training (i.e., "noise-resistant" period), and leverage those data as denoising signals to guide the following training (i.e., "noise-sensitive" period) of the model in a meta-learning manner. Besides, our method can automatically switch its learning phase at the memorization point from memorization to self-guided learning, and select clean and informative memorized data via a novel adaptive denoising scheduler to improve the robustness. We incorporate SGDL with four representative recommendation models (i.e., NeuMF, CDAE, NGCF and LightGCN) and different loss functions (i.e., binary cross-entropy and BPR loss). The experimental results on three benchmark datasets demonstrate the effectiveness of SGDL over the state-of-the-art denoising methods like T-CE, IR, DeCA, and even state-of-the-art robust graph-based methods like SGCN and SGL.
HAKG: Hierarchy-Aware Knowledge Gated Network for Recommendation
Apr 11, 2022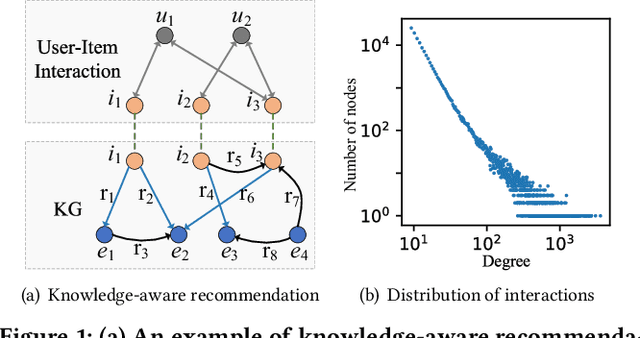
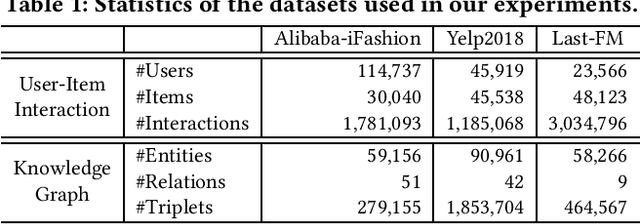
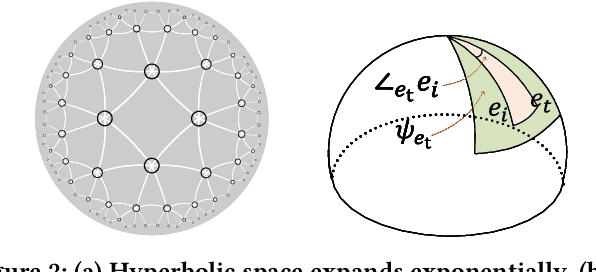
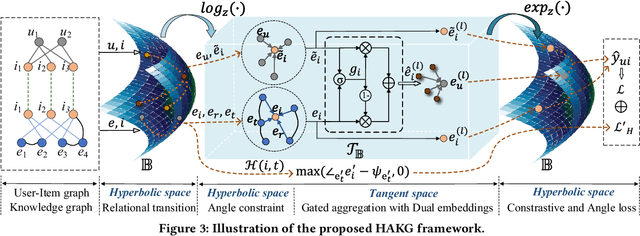
Knowledge graph (KG) plays an increasingly important role to improve the recommendation performance and interpretability. A recent technical trend is to design end-to-end models based on information propagation schemes. However, existing propagation-based methods fail to (1) model the underlying hierarchical structures and relations, and (2) capture the high-order collaborative signals of items for learning high-quality user and item representations. In this paper, we propose a new model, called Hierarchy-Aware Knowledge Gated Network (HAKG), to tackle the aforementioned problems. Technically, we model users and items (that are captured by a user-item graph), as well as entities and relations (that are captured in a KG) in hyperbolic space, and design a hyperbolic aggregation scheme to gather relational contexts over KG. Meanwhile, we introduce a novel angle constraint to preserve characteristics of items in the embedding space. Furthermore, we propose a dual item embeddings design to represent and propagate collaborative signals and knowledge associations separately, and leverage the gated aggregation to distill discriminative information for better capturing user behavior patterns. Experimental results on three benchmark datasets show that, HAKG achieves significant improvement over the state-of-the-art methods like CKAN, Hyper-Know, and KGIN. Further analyses on the learned hyperbolic embeddings confirm that HAKG offers meaningful insights into the hierarchies of data.
Crowding Prediction of In-Situ Metro Passengers Using Smart Card Data
Sep 07, 2020
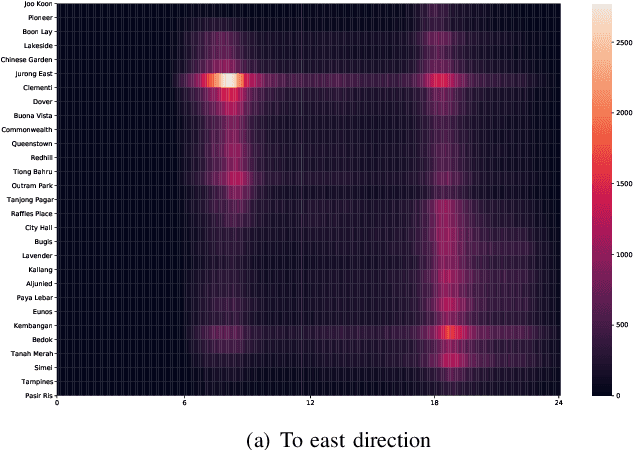
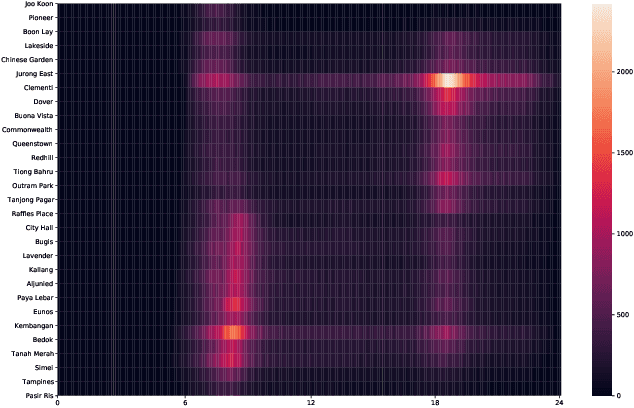
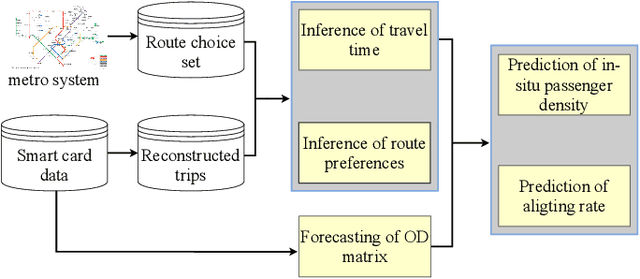
The metro system is playing an increasingly important role in the urban public transit network, transferring a massive human flow across space everyday in the city. In recent years, extensive research studies have been conducted to improve the service quality of metro systems. Among them, crowd management has been a critical issue for both public transport agencies and train operators. In this paper, by utilizing accumulated smart card data, we propose a statistical model to predict in-situ passenger density, i.e., number of on-board passengers between any two neighbouring stations, inside a closed metro system. The proposed model performs two main tasks: i) forecasting time-dependent Origin-Destination (OD) matrix by applying mature statistical models; and ii) estimating the travel time cost required by different parts of the metro network via truncated normal mixture distributions with Expectation-Maximization (EM) algorithm. Based on the prediction results, we are able to provide accurate prediction of in-situ passenger density for a future time point. A case study using real smart card data in Singapore Mass Rapid Transit (MRT) system demonstrate the efficacy and efficiency of our proposed method.
Probabilistic Value Selection for Space Efficient Model
Jul 09, 2020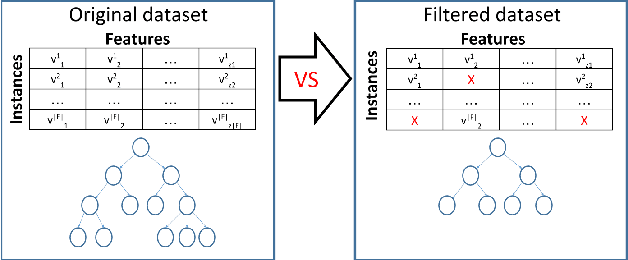
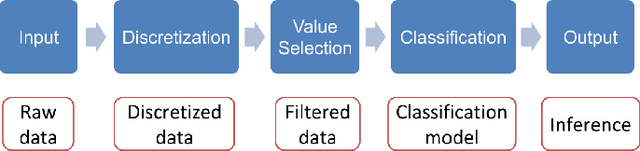
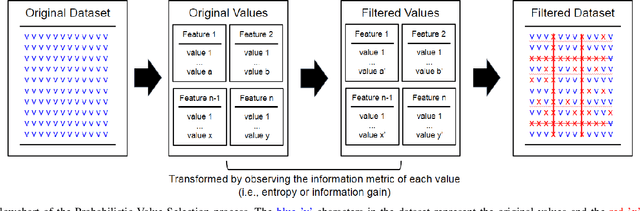
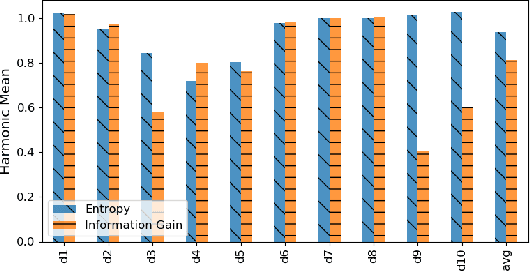
An alternative to current mainstream preprocessing methods is proposed: Value Selection (VS). Unlike the existing methods such as feature selection that removes features and instance selection that eliminates instances, value selection eliminates the values (with respect to each feature) in the dataset with two purposes: reducing the model size and preserving its accuracy. Two probabilistic methods based on information theory's metric are proposed: PVS and P + VS. Extensive experiments on the benchmark datasets with various sizes are elaborated. Those results are compared with the existing preprocessing methods such as feature selection, feature transformation, and instance selection methods. Experiment results show that value selection can achieve the balance between accuracy and model size reduction.
TRIPDECODER: Study Travel Time Attributes and Route Preferences of Metro Systems from Smart Card Data
May 01, 2020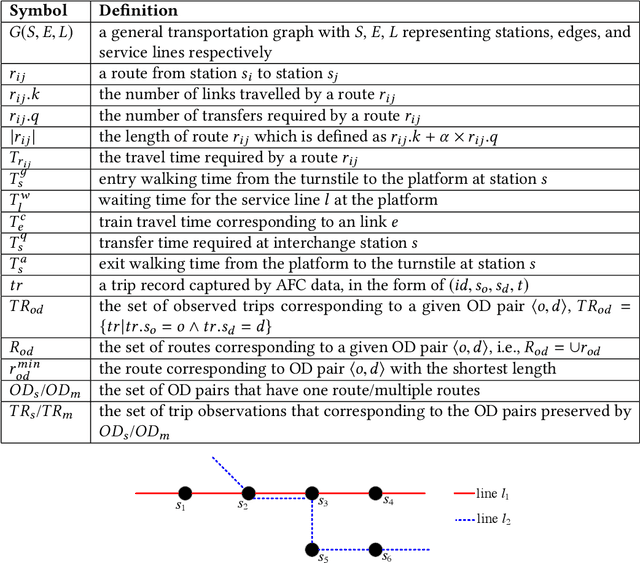

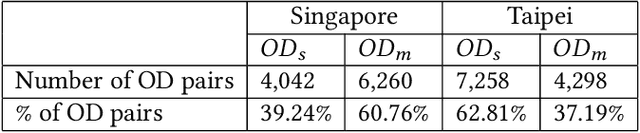
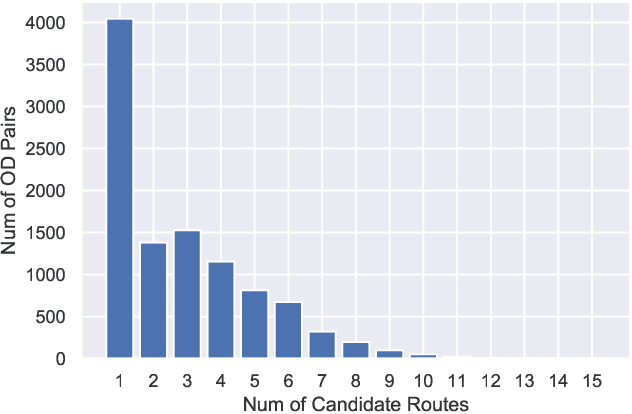
In this paper, we target at recovering the exact routes taken by commuters inside a metro system that arenot captured by an Automated Fare Collection (AFC) system and hence remain unknown. We strategicallypropose two inference tasks to handle the recovering, one to infer the travel time of each travel link thatcontributes to the total duration of any trip inside a metro network and the other to infer the route preferencesbased on historical trip records and the travel time of each travel link inferred in the previous inferencetask. As these two inference tasks have interrelationship, most of existing works perform these two taskssimultaneously. However, our solutionTripDecoderadopts a totally different approach. To the best of ourknowledge,TripDecoderis the first model that points out and fully utilizes the fact that there are some tripsinside a metro system with only one practical route available. It strategically decouples these two inferencetasks by only taking those trip records with only one practical route as the input for the first inference taskof travel time and feeding the inferred travel time to the second inference task as an additional input whichnot only improves the accuracy but also effectively reduces the complexity of both inference tasks. Twocase studies have been performed based on the city-scale real trip records captured by the AFC systems inSingapore and Taipei to compare the accuracy and efficiency ofTripDecoderand its competitors. As expected,TripDecoderhas achieved the best accuracy in both datasets, and it also demonstrates its superior efficiencyand scalability.
CrowdTSC: Crowd-based Neural Networks for Text Sentiment Classification
Apr 26, 2020
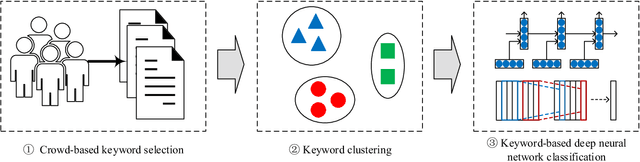

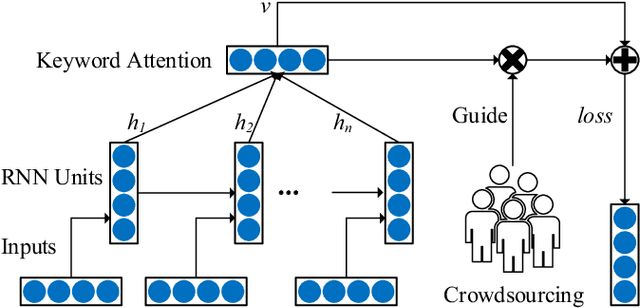
Sentiment classification is a fundamental task in content analysis. Although deep learning has demonstrated promising performance in text classification compared with shallow models, it is still not able to train a satisfying classifier for text sentiment. Human beings are more sophisticated than machine learning models in terms of understanding and capturing the emotional polarities of texts. In this paper, we leverage the power of human intelligence into text sentiment classification. We propose Crowd-based neural networks for Text Sentiment Classification (CrowdTSC for short). We design and post the questions on a crowdsourcing platform to collect the keywords in texts. Sampling and clustering are utilized to reduce the cost of crowdsourcing. Also, we present an attention-based neural network and a hybrid neural network, which incorporate the collected keywords as human being's guidance into deep neural networks. Extensive experiments on public datasets confirm that CrowdTSC outperforms state-of-the-art models, justifying the effectiveness of crowd-based keyword guidance.