 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Value Selection for Space Efficient Model
Jul 09, 2020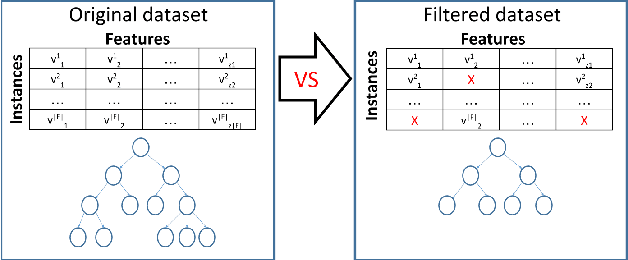
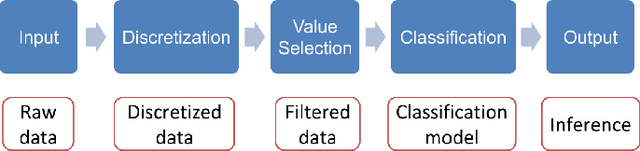
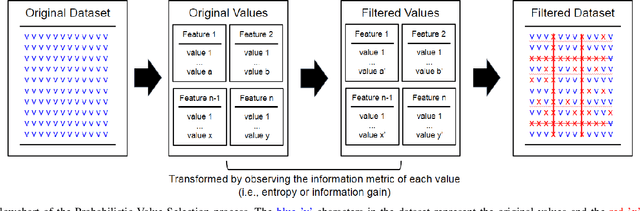
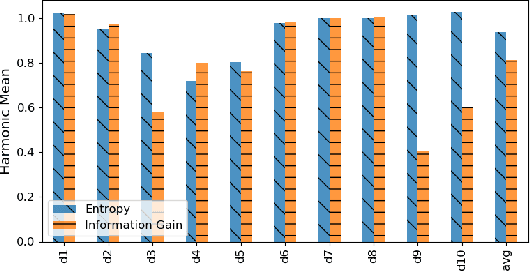
An alternative to current mainstream preprocessing methods is proposed: Value Selection (VS). Unlike the existing methods such as feature selection that removes features and instance selection that eliminates instances, value selection eliminates the values (with respect to each feature) in the dataset with two purposes: reducing the model size and preserving its accuracy. Two probabilistic methods based on information theory's metric are proposed: PVS and P + VS. Extensive experiments on the benchmark datasets with various sizes are elaborated. Those results are compared with the existing preprocessing methods such as feature selection, feature transformation, and instance selection methods. Experiment results show that value selection can achieve the balance between accuracy and model size reduction.