 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-refined Denoising Network for Robust Recommendation
Apr 28, 2023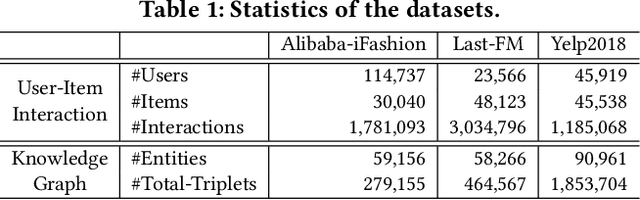
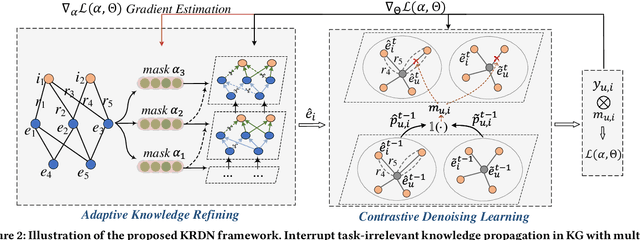

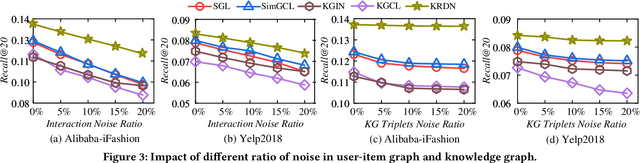
Knowledge graph (KG), which contains rich side information, becomes an essential part to boost the recommendation performance and improve its explainability. However, existing knowledge-aware recommendation methods directly perform information propagation on KG and user-item bipartite graph, ignoring the impacts of \textit{task-irrelevant knowledge propagation} and \textit{vulnerability to interaction noise}, which limits their performance. To solve these issues, we propose a robust knowledge-aware recommendation framework, called \textit{Knowledge-refined Denoising Network} (KRDN), to prune the task-irrelevant knowledge associations and noisy implicit feedback simultaneously. KRDN consists of an adaptive knowledge refining strategy and a contrastive denoising mechanism, which are able to automatically distill high-quality KG triplets for aggregation and prune noisy implicit feedback respectively. Besides, we also design the self-adapted loss function and the gradient estimator for model optimization. The experimental results on three benchmark datasets demonstrate the effectiveness and robustness of KRDN over the state-of-the-art knowledge-aware methods like KGIN, MCCLK, and KGCL, and also outperform robust recommendation models like SGL and SimGCL.
Self-Guided Learning to Denoise for Robust Recommendation
Apr 14, 2022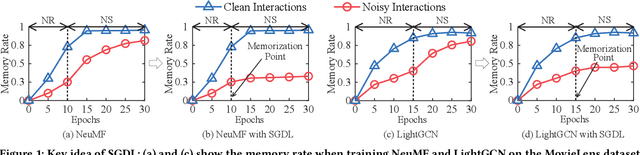
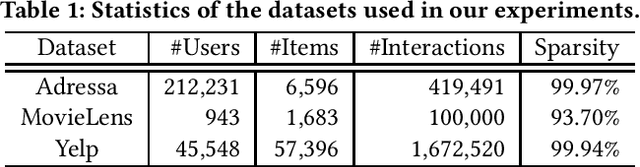
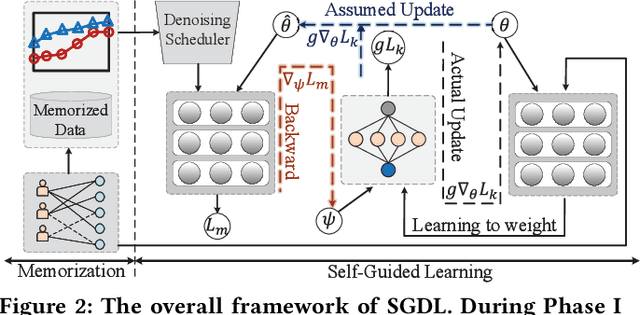
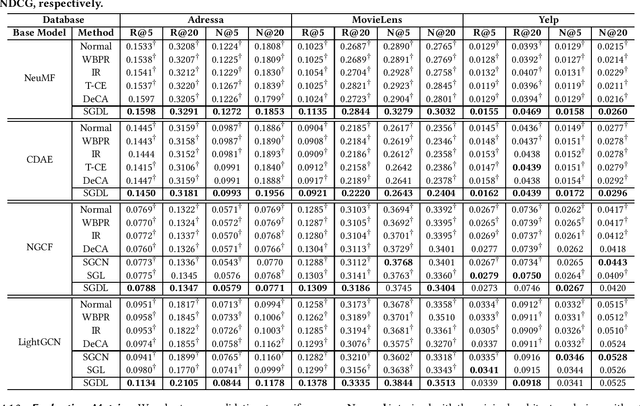
The ubiquity of implicit feedback makes them the default choice to build modern recommender systems. Generally speaking, observed interactions are considered as positive samples, while unobserved interactions are considered as negative ones. However, implicit feedback is inherently noisy because of the ubiquitous presence of noisy-positive and noisy-negative interactions. Recently, some studies have noticed the importance of denoising implicit feedback for recommendations, and enhanced the robustness of recommendation models to some extent. Nonetheless, they typically fail to (1) capture the hard yet clean interactions for learning comprehensive user preference, and (2) provide a universal denoising solution that can be applied to various kinds of recommendation models. In this paper, we thoroughly investigate the memorization effect of recommendation models, and propose a new denoising paradigm, i.e., Self-Guided Denoising Learning (SGDL), which is able to collect memorized interactions at the early stage of the training (i.e., "noise-resistant" period), and leverage those data as denoising signals to guide the following training (i.e., "noise-sensitive" period) of the model in a meta-learning manner. Besides, our method can automatically switch its learning phase at the memorization point from memorization to self-guided learning, and select clean and informative memorized data via a novel adaptive denoising scheduler to improve the robustness. We incorporate SGDL with four representative recommendation models (i.e., NeuMF, CDAE, NGCF and LightGCN) and different loss functions (i.e., binary cross-entropy and BPR loss). The experimental results on three benchmark datasets demonstrate the effectiveness of SGDL over the state-of-the-art denoising methods like T-CE, IR, DeCA, and even state-of-the-art robust graph-based methods like SGCN and SGL.
HAKG: Hierarchy-Aware Knowledge Gated Network for Recommendation
Apr 11, 2022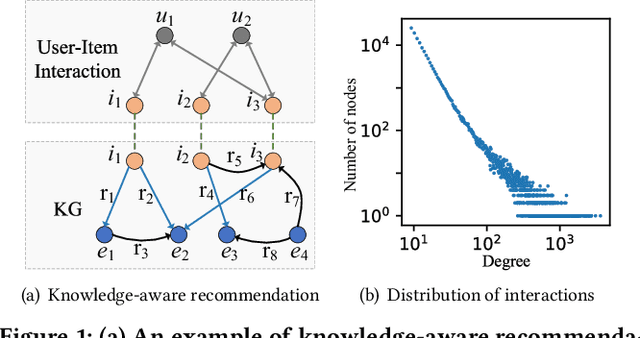
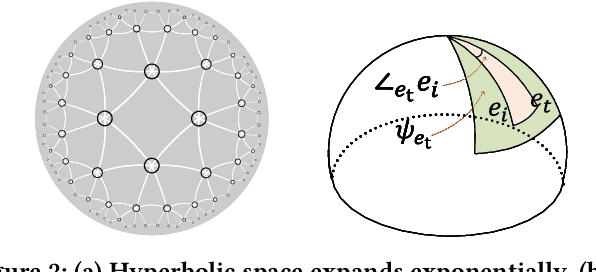
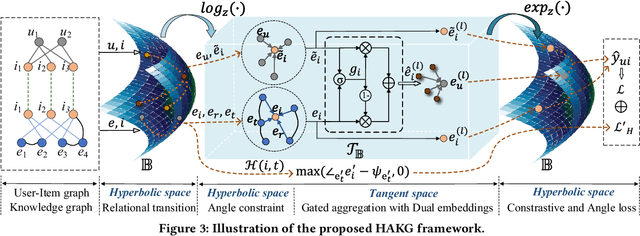
Knowledge graph (KG) plays an increasingly important role to improve the recommendation performance and interpretability. A recent technical trend is to design end-to-end models based on information propagation schemes. However, existing propagation-based methods fail to (1) model the underlying hierarchical structures and relations, and (2) capture the high-order collaborative signals of items for learning high-quality user and item representations. In this paper, we propose a new model, called Hierarchy-Aware Knowledge Gated Network (HAKG), to tackle the aforementioned problems. Technically, we model users and items (that are captured by a user-item graph), as well as entities and relations (that are captured in a KG) in hyperbolic space, and design a hyperbolic aggregation scheme to gather relational contexts over KG. Meanwhile, we introduce a novel angle constraint to preserve characteristics of items in the embedding space. Furthermore, we propose a dual item embeddings design to represent and propagate collaborative signals and knowledge associations separately, and leverage the gated aggregation to distill discriminative information for better capturing user behavior patterns. Experimental results on three benchmark datasets show that, HAKG achieves significant improvement over the state-of-the-art methods like CKAN, Hyper-Know, and KGIN. Further analyses on the learned hyperbolic embeddings confirm that HAKG offers meaningful insights into the hierarchies of data.
MetaKG: Meta-learning on Knowledge Graph for Cold-start Recommendation
Feb 08, 2022
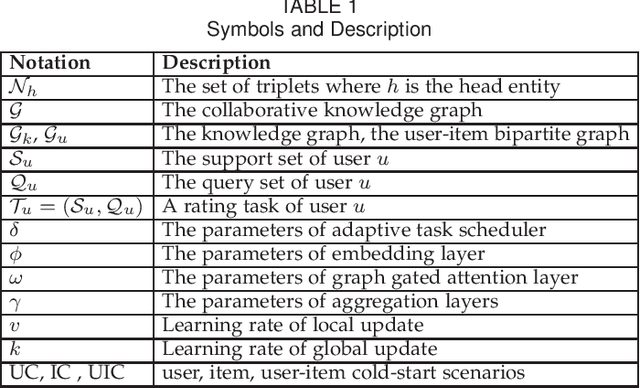
A knowledge graph (KG) consists of a set of interconnected typed entities and their attributes. Recently, KGs are popularly used as the auxiliary information to enable more accurate, explainable, and diverse user preference recommendations. Specifically, existing KG-based recommendation methods target modeling high-order relations/dependencies from long connectivity user-item interactions hidden in KG. However, most of them ignore the cold-start problems (i.e., user cold-start and item cold-start) of recommendation analytics, which restricts their performance in scenarios when involving new users or new items. Inspired by the success of meta-learning on scarce training samples, we propose a novel meta-learning based framework called MetaKG, which encompasses a collaborative-aware meta learner and a knowledge-aware meta learner, to capture meta users' preference and entities' knowledge for cold-start recommendations. The collaborative-aware meta learner aims to locally aggregate user preferences for each user preference learning task. In contrast, the knowledge-aware meta learner is to globally generalize knowledge representation across different user preference learning tasks. Guided by two meta learners, MetaKG can effectively capture the high-order collaborative relations and semantic representations, which could be easily adapted to cold-start scenarios. Besides, we devise a novel adaptive task scheduler which can adaptively select the informative tasks for meta learning in order to prevent the model from being corrupted by noisy tasks. Extensive experiments on various cold-start scenarios using three real data sets demonstrate that our presented MetaKG outperforms all the existing state-of-the-art competitors in terms of effectiveness, efficiency, and scalability.
ST2Vec: Spatio-Temporal Trajectory Similarity Learning in Road Networks
Dec 17, 2021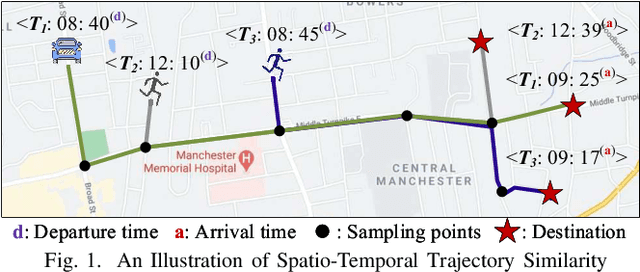

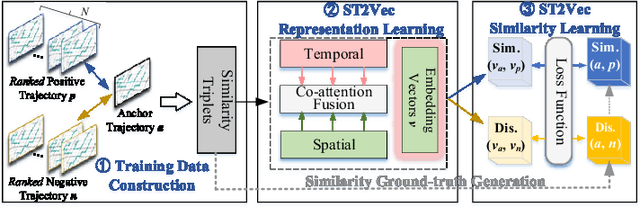
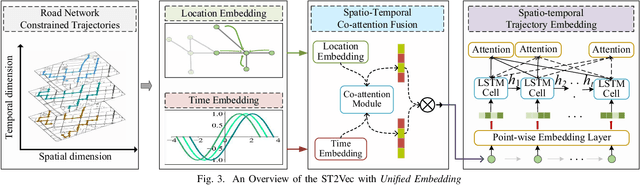
People and vehicle trajectories embody important information of transportation infrastructures, and trajectory similarity computation is functionality in many real-world applications involving trajectory data analysis. Recently, deep-learning based trajectory similarity techniques hold the potential to offer improved efficiency and adaptability over traditional similarity techniques. Nevertheless, the existing trajectory similarity learning proposals emphasize spatial similarity over temporal similarity, making them suboptimal for time-aware analyses. To this end, we propose ST2Vec, a trajectory-representation-learning based architecture that considers fine-grained spatial and temporal correlations between pairs of trajectories for spatio-temporal similarity learning in road networks. To the best of our knowledge, this is the first deep-learning proposal for spatio-temporal trajectory similarity analytics. Specifically, ST2Vec encompasses three phases: (i) training data preparation that selects representative training samples; (ii) spatial and temporal modeling that encode spatial and temporal characteristics of trajectories, where a generic temporal modeling module (TMM) is designed; and (iii) spatio-temporal co-attention fusion (STCF), where a unified fusion (UF) approach is developed to help generating unified spatio-temporal trajectory embeddings that capture the spatio-temporal similarity relations between trajectories. Further, inspired by curriculum concept, ST2Vec employs the curriculum learning for model optimization to improve both convergence and effectiveness. An experimental study offers evidence that ST2Vec outperforms all state-of-the-art competitors substantially in terms of effectiveness, efficiency, and scalability, while showing low parameter sensitivity and good model robustness.
Hformer: Hybrid CNN-Transformer for Fringe Order Prediction in Phase Unwrapping of Fringe Projection
Dec 13, 2021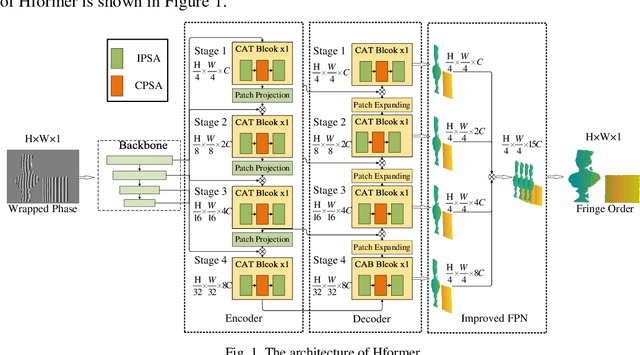
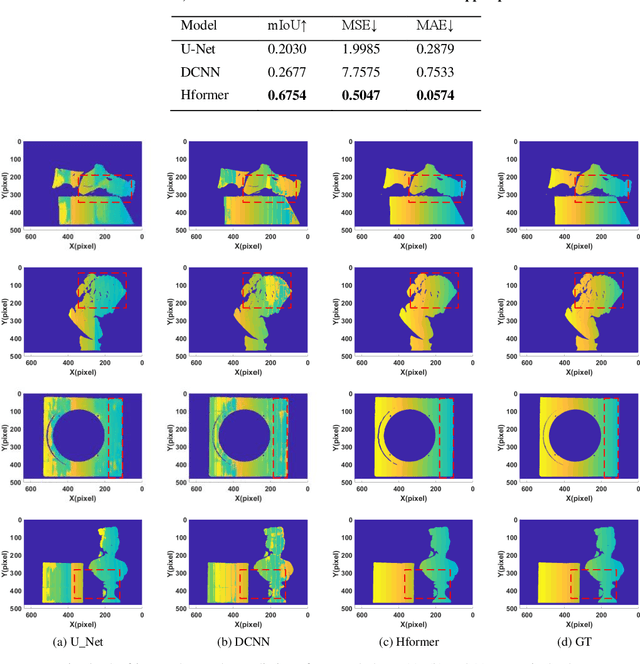
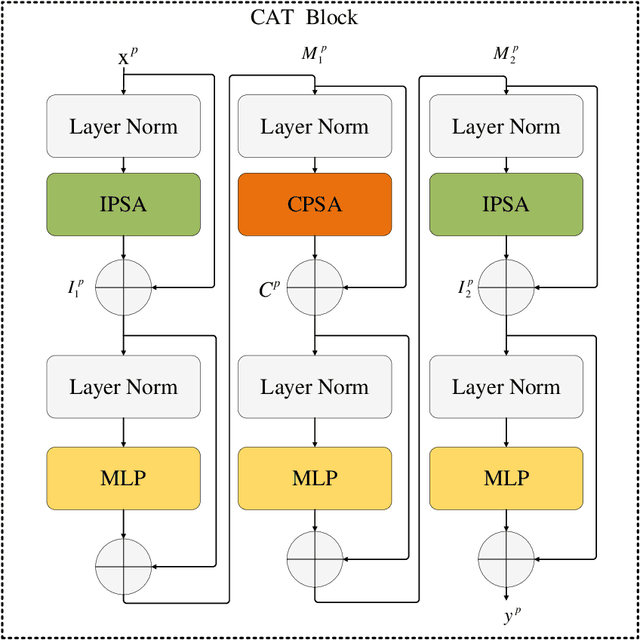
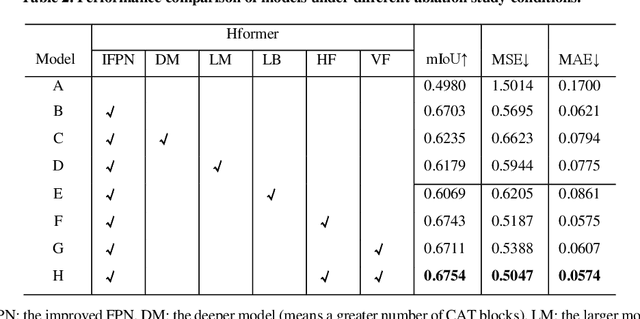
Recently, deep learning has attracted more and more attention in phase unwrapping of fringe projection three-dimensional (3D) measurement, with the aim to improve the performance leveraging the powerful Convolutional Neural Network (CNN) models. In this paper, for the first time (to the best of our knowledge), we introduce the Transformer into the phase unwrapping which is different from CNN and propose Hformer model dedicated to phase unwrapping via fringe order prediction. The proposed model has a hybrid CNN-Transformer architecture that is mainly composed of backbone, encoder and decoder to take advantage of both CNN and Transformer. Encoder and decoder with cross attention are designed for the fringe order prediction. Experimental results show that the proposed Hformer model achieves better performance in fringe order prediction compared with the CNN models such as U-Net and DCNN. Moreover, ablation study on Hformer is made to verify the improved feature pyramid networks (FPN) and testing strategy with flipping in the predicted fringe order. Our work opens an alternative way to deep learning based phase unwrapping methods, which are dominated by CNN in fringe projection 3D measurement.