 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient Subjective Task Annotation and Modeling through Few-Shot Annotator Adaptation
Feb 21, 2024In subjective NLP tasks, where a single ground truth does not exist, the inclusion of diverse annotators becomes crucial as their unique perspectives significantly influence the annotations. In realistic scenarios, the annotation budget often becomes the main determinant of the number of perspectives (i.e., annotators) included in the data and subsequent modeling. We introduce a novel framework for annotation collection and modeling in subjective tasks that aims to minimize the annotation budget while maximizing the predictive performance for each annotator. Our framework has a two-stage design: first, we rely on a small set of annotators to build a multitask model, and second, we augment the model for a new perspective by strategically annotating a few samples per annotator. To test our framework at scale, we introduce and release a unique dataset, Moral Foundations Subjective Corpus, of 2000 Reddit posts annotated by 24 annotators for moral sentiment. We demonstrate that our framework surpasses the previous SOTA in capturing the annotators' individual perspectives with as little as 25% of the original annotation budget on two datasets. Furthermore, our framework results in more equitable models, reducing the performance disparity among annotators.
Towards a Unified Framework for Adaptable Problematic Content Detection via Continual Learning
Sep 29, 2023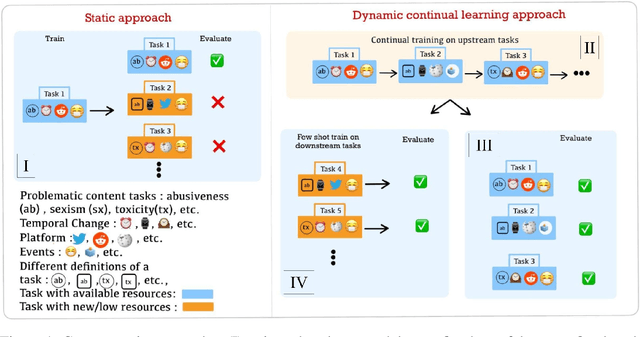
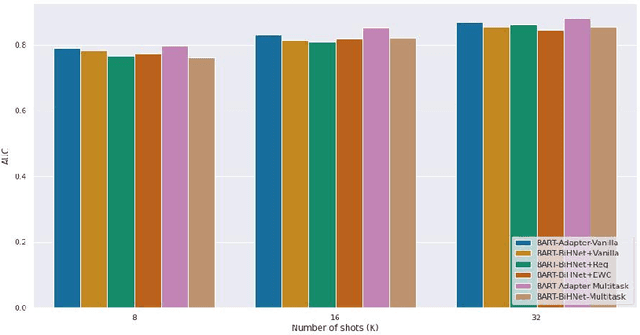
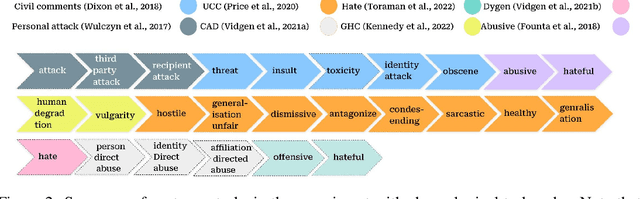
Detecting problematic content, such as hate speech, is a multifaceted and ever-changing task, influenced by social dynamics, user populations, diversity of sources, and evolving language. There has been significant efforts, both in academia and in industry, to develop annotated resources that capture various aspects of problematic content. Due to researchers' diverse objectives, the annotations are inconsistent and hence, reports of progress on detection of problematic content are fragmented. This pattern is expected to persist unless we consolidate resources considering the dynamic nature of the problem. We propose integrating the available resources, and leveraging their dynamic nature to break this pattern. In this paper, we introduce a continual learning benchmark and framework for problematic content detection comprising over 84 related tasks encompassing 15 annotation schemas from 8 sources. Our benchmark creates a novel measure of progress: prioritizing the adaptability of classifiers to evolving tasks over excelling in specific tasks. To ensure the continuous relevance of our framework, we designed it so that new tasks can easily be integrated into the benchmark. Our baseline results demonstrate the potential of continual learning in capturing the evolving content and adapting to novel manifestations of problematic content.
Social-Group-Agnostic Word Embedding Debiasing via the Stereotype Content Model
Oct 11, 2022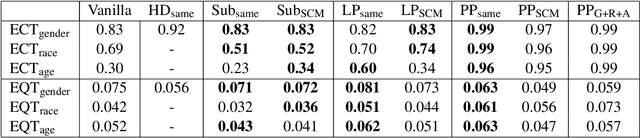
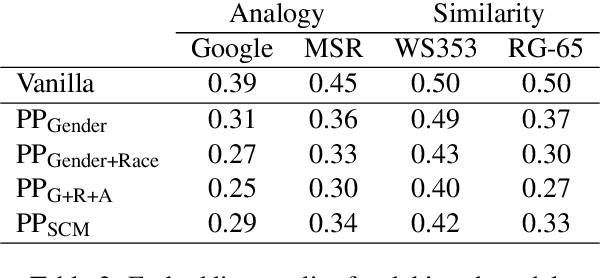
Existing word embedding debiasing methods require social-group-specific word pairs (e.g., "man"-"woman") for each social attribute (e.g., gender), which cannot be used to mitigate bias for other social groups, making these methods impractical or costly to incorporate understudied social groups in debiasing. We propose that the Stereotype Content Model (SCM), a theoretical framework developed in social psychology for understanding the content of stereotypes, which structures stereotype content along two psychological dimensions - "warmth" and "competence" - can help debiasing efforts to become social-group-agnostic by capturing the underlying connection between bias and stereotypes. Using only pairs of terms for warmth (e.g., "genuine"-"fake") and competence (e.g.,"smart"-"stupid"), we perform debiasing with established methods and find that, across gender, race, and age, SCM-based debiasing performs comparably to group-specific debiasing
The Moral Foundations Reddit Corpus
Aug 18, 2022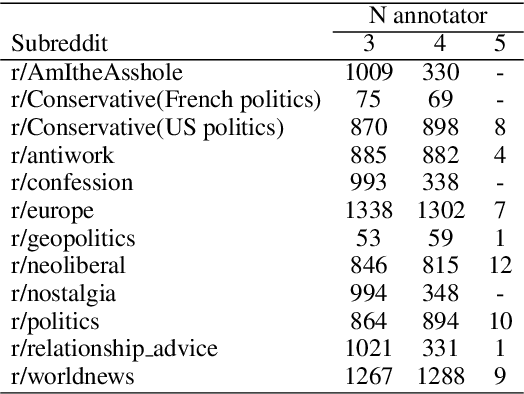
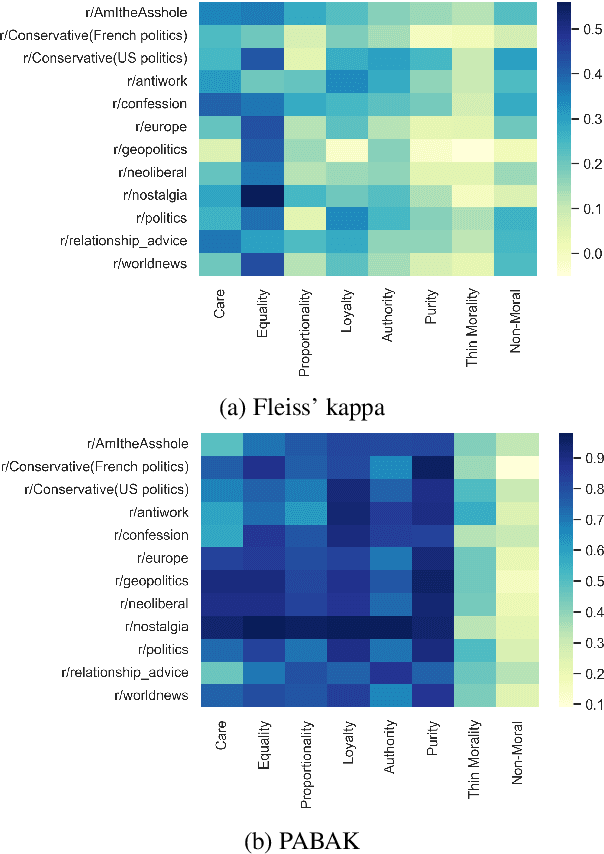
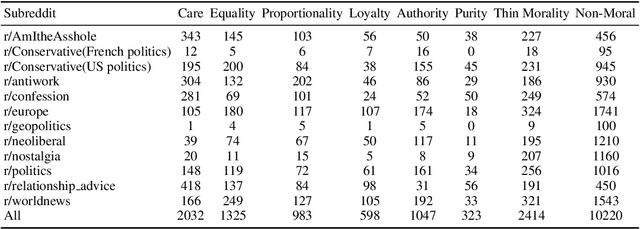
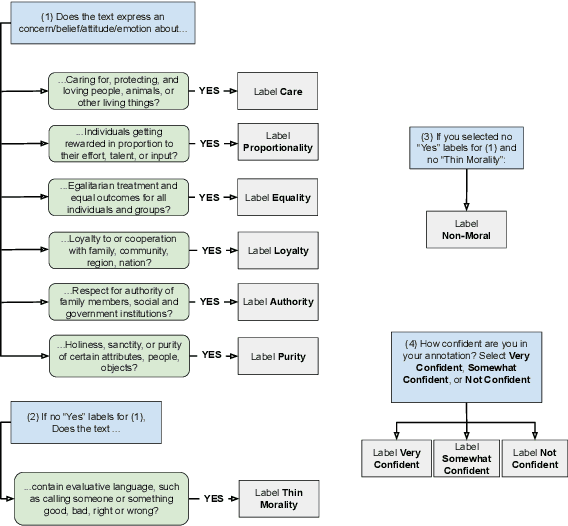
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.
Improving Counterfactual Generation for Fair Hate Speech Detection
Aug 03, 2021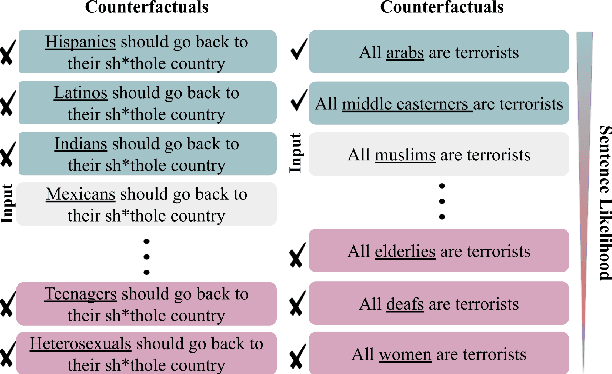


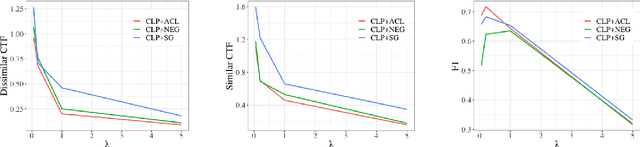
Bias mitigation approaches reduce models' dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020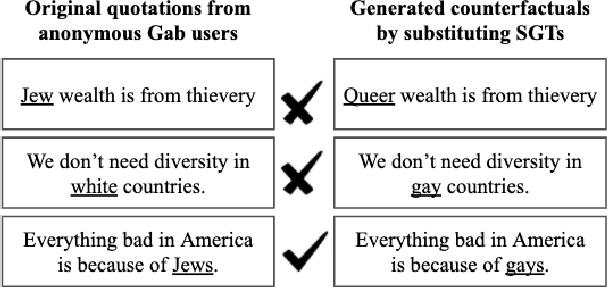
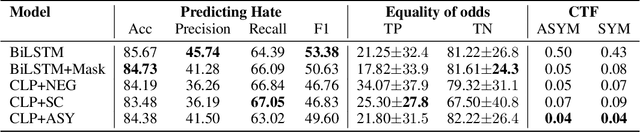
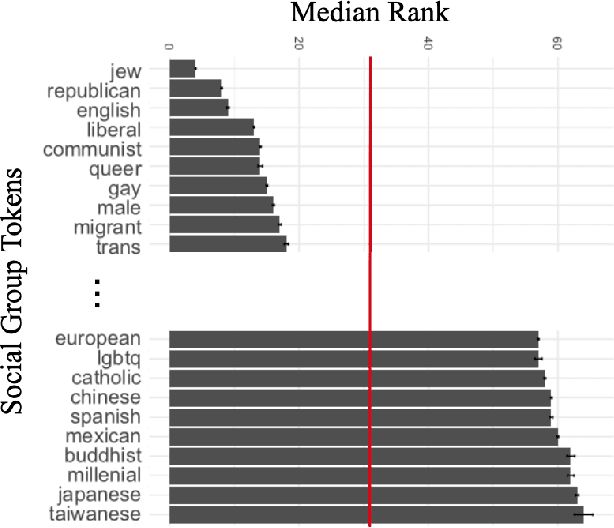
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.