 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Mitigating Classification Bias via Transfer Learning
Paper and Code
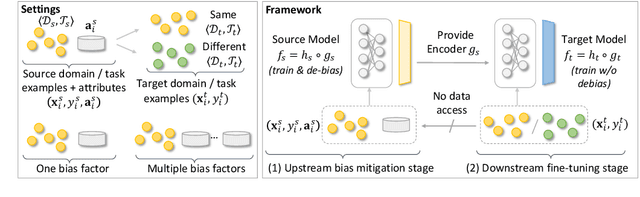
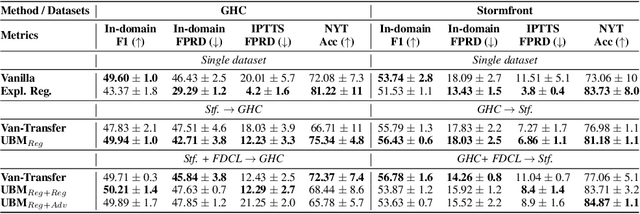
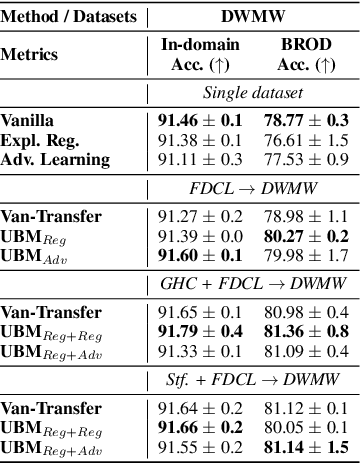
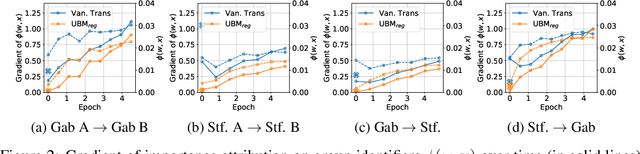
Prediction bias in machine learning models refers to unintended model behaviors that discriminate against inputs mentioning or produced by certain groups; for example, hate speech classifiers predict more false positives for neutral text mentioning specific social groups. Mitigating bias for each task or domain is inefficient, as it requires repetitive model training, data annotation (e.g., demographic information), and evaluation. In pursuit of a more accessible solution, we propose the Upstream Bias Mitigation for Downstream Fine-Tuning (UBM) framework, which mitigate one or multiple bias factors in downstream classifiers by transfer learning from an upstream model. In the upstream bias mitigation stage, explanation regularization and adversarial training are applied to mitigate multiple bias factors. In the downstream fine-tuning stage, the classifier layer of the model is re-initialized, and the entire model is fine-tuned to downstream tasks in potentially novel domains without any further bias mitigation. We expect downstream classifiers to be less biased by transfer learning from de-biased upstream models. We conduct extensive experiments varying the similarity between the source and target data, as well as varying the number of dimensions of bias (e.g., discrimination against specific social groups or dialects). Our results indicate the proposed UBM framework can effectively reduce bias in downstream classifiers.