 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Forgetting in Language Model Fine-Tuning with Statistical Analysis of Example Associations
Jun 20, 2024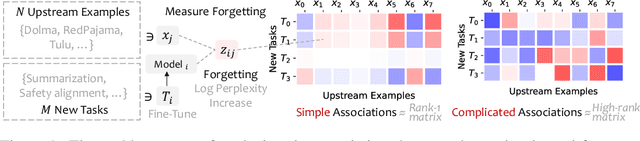
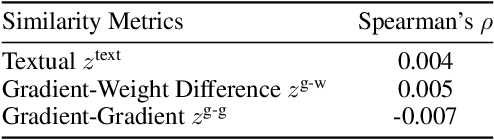
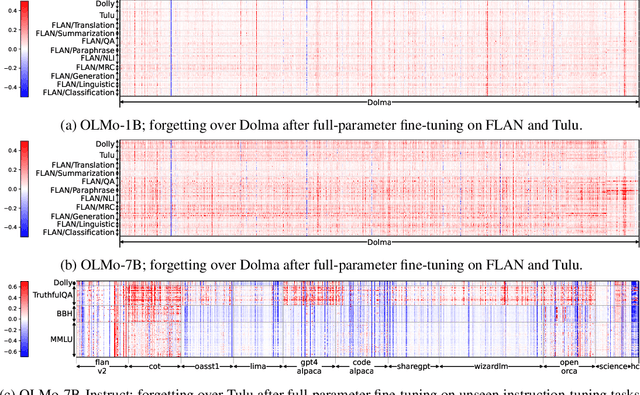

Language models (LMs) are known to suffer from forgetting of previously learned examples when fine-tuned, breaking stability of deployed LM systems. Despite efforts on mitigating forgetting, few have investigated whether, and how forgotten upstream examples are associated with newly learned tasks. Insights on such associations enable efficient and targeted mitigation of forgetting. In this paper, we empirically analyze forgetting that occurs in $N$ upstream examples while the model learns $M$ new tasks and visualize their associations with a $M \times N$ matrix. We empirically demonstrate that the degree of forgetting can often be approximated by simple multiplicative contributions of the upstream examples and newly learned tasks. We also reveal more complicated patterns where specific subsets of examples are forgotten with statistics and visualization. Following our analysis, we predict forgetting that happens on upstream examples when learning a new task with matrix completion over the empirical associations, outperforming prior approaches that rely on trainable LMs. Project website: https://inklab.usc.edu/lm-forgetting-prediction/
What Will My Model Forget? Forecasting Forgotten Examples in Language Model Refinement
Feb 02, 2024
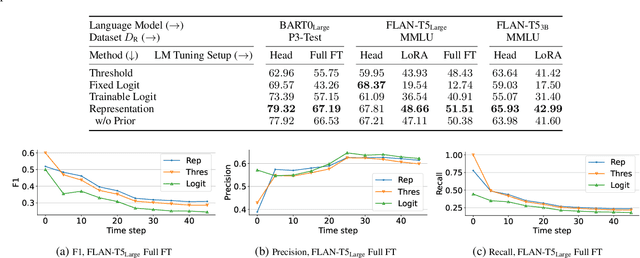

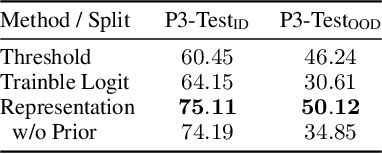
Language models deployed in the wild make errors. However, simply updating the model with the corrected error instances causes catastrophic forgetting -- the updated model makes errors on instances learned during the instruction tuning or upstream training phase. Randomly replaying upstream data yields unsatisfactory performance and often comes with high variance and poor controllability. To this end, we try to forecast upstream examples that will be forgotten due to a model update for improved controllability of the replay process and interpretability. We train forecasting models given a collection of online learned examples and corresponding forgotten upstream pre-training examples. We propose a partially interpretable forecasting model based on the observation that changes in pre-softmax logit scores of pretraining examples resemble that of online learned examples, which performs decently on BART but fails on T5 models. We further show a black-box classifier based on inner products of example representations achieves better forecasting performance over a series of setups. Finally, we show that we reduce forgetting of upstream pretraining examples by replaying examples that are forecasted to be forgotten, demonstrating the practical utility of forecasting example forgetting.
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023
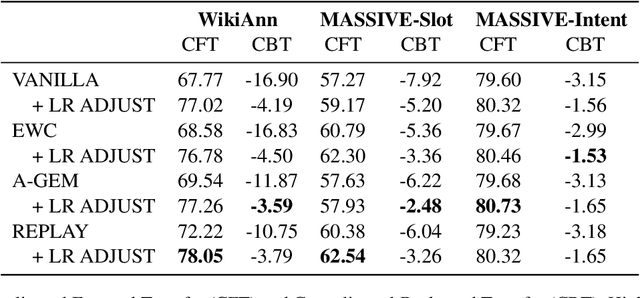
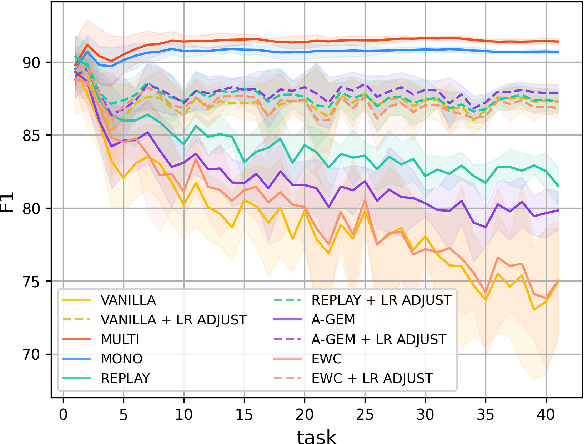
Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
Dataless Knowledge Fusion by Merging Weights of Language Models
Dec 19, 2022



Fine-tuning pre-trained language models has become the prevalent paradigm for building downstream NLP models. Oftentimes fine-tuned models are readily available but their training data is not, due to data privacy or intellectual property concerns. This creates a barrier to fusing knowledge across individual models to yield a better single model. In this paper, we study the problem of merging individual models built on different training data sets to obtain a single model that performs well both across all data set domains and can generalize on out-of-domain data. We propose a dataless knowledge fusion method that merges models in their parameter space, guided by weights that minimize prediction differences between the merged model and the individual models. Over a battery of evaluation settings, we show that the proposed method significantly outperforms baselines such as Fisher-weighted averaging or model ensembling. Further, we find that our method is a promising alternative to multi-task learning that can preserve or sometimes improve over the individual models without access to the training data. Finally, model merging is more efficient than training a multi-task model, thus making it applicable to a wider set of scenarios.
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021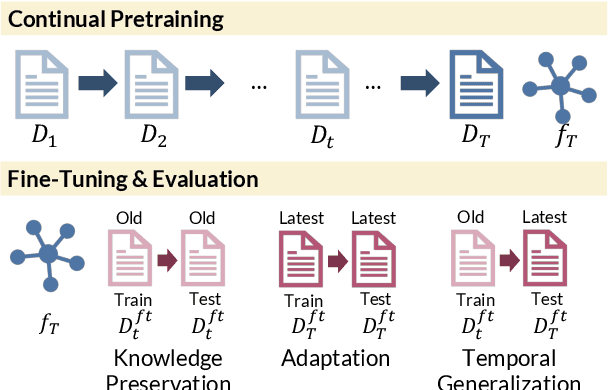
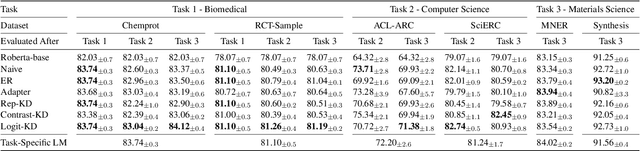
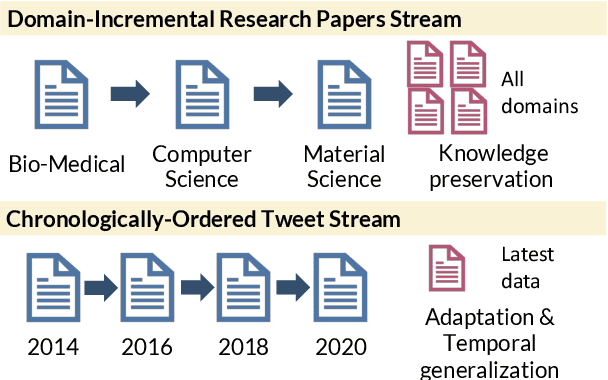
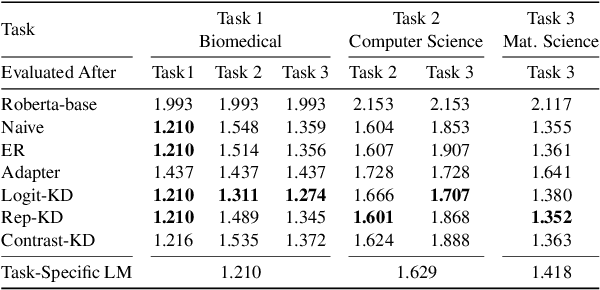
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Lifelong Learning of Few-shot Learners across NLP Tasks
Apr 18, 2021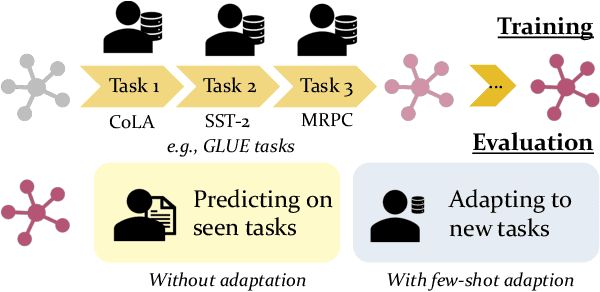
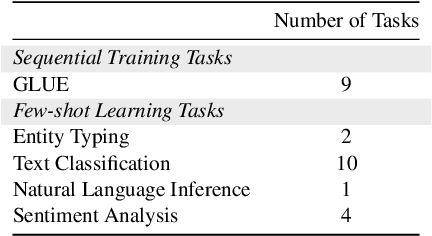
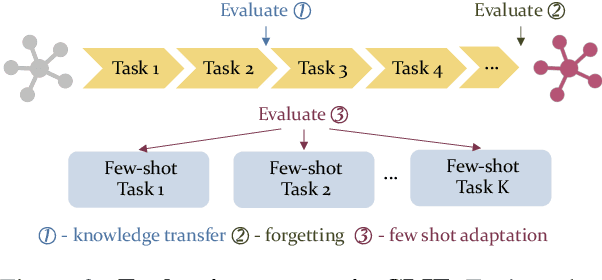
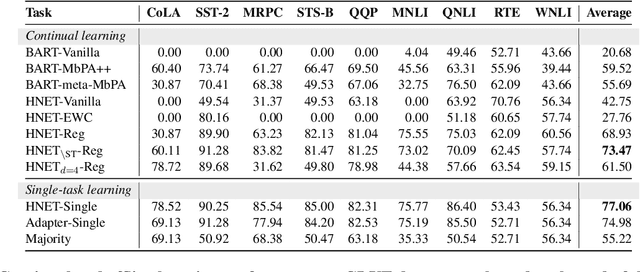
Recent advances in large pre-trained language models have greatly improved the performance on a broad set of NLP tasks. However, adapting an existing model to new tasks often requires (repeated) re-training over enormous labeled data that is prohibitively expensive to obtain. Moreover, models learned on new tasks may gradually "forget" about the knowledge learned from earlier tasks (i.e., catastrophic forgetting). In this paper, we study the challenge of lifelong learning to few-shot learn over a sequence of diverse NLP tasks, through continuously fine-tuning a language model. We investigate the model's ability of few-shot generalization to new tasks while retaining its performance on the previously learned tasks. We explore existing continual learning methods in solving this problem and propose a continual meta-learning approach which learns to generate adapter weights from a few examples while regularizing changes of the weights to mitigate catastrophic forgetting. We demonstrate our approach preserves model performance over training tasks and leads to positive knowledge transfer when the future tasks are learned.
Refining Neural Networks with Compositional Explanations
Mar 18, 2021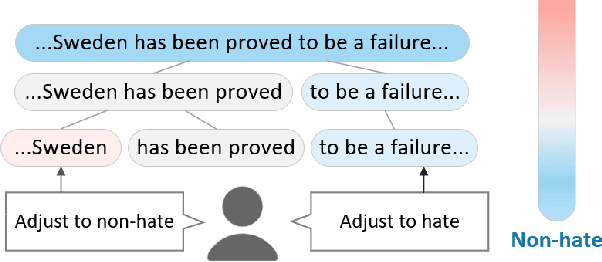
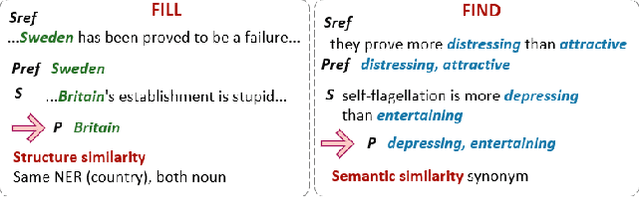


Neural networks are prone to learning spurious correlations from biased datasets, and are thus vulnerable when making inferences in a new target domain. Prior work reveals spurious patterns via post-hoc model explanations which compute the importance of input features, and further eliminates the unintended model behaviors by regularizing importance scores with human knowledge. However, such regularization technique lacks flexibility and coverage, since only importance scores towards a pre-defined list of features are adjusted, while more complex human knowledge such as feature interaction and pattern generalization can hardly be incorporated. In this work, we propose to refine a learned model by collecting human-provided compositional explanations on the models' failure cases. By describing generalizable rules about spurious patterns in the explanation, more training examples can be matched and regularized, tackling the challenge of regularization coverage. We additionally introduce a regularization term for feature interaction to support more complex human rationale in refining the model. We demonstrate the effectiveness of the proposed approach on two text classification tasks by showing improved performance in target domain after refinement.
Efficiently Mitigating Classification Bias via Transfer Learning
Oct 24, 2020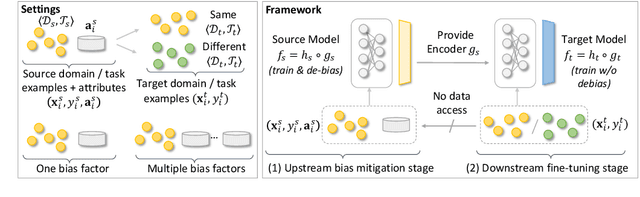
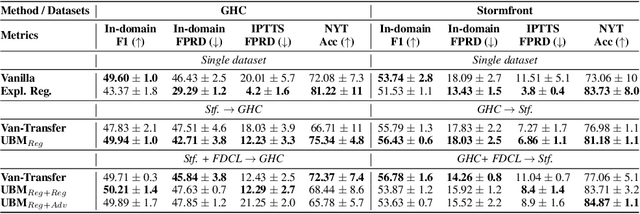
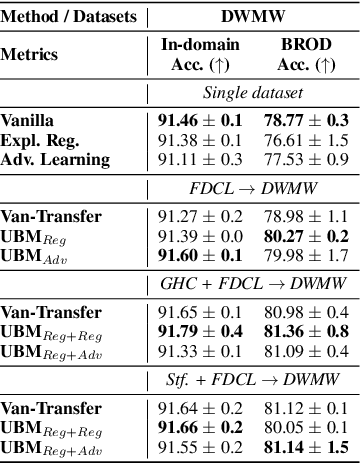
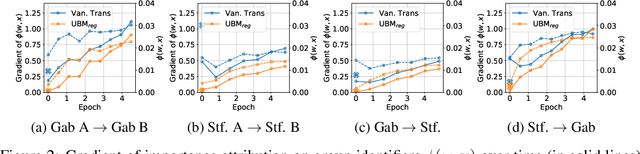
Prediction bias in machine learning models refers to unintended model behaviors that discriminate against inputs mentioning or produced by certain groups; for example, hate speech classifiers predict more false positives for neutral text mentioning specific social groups. Mitigating bias for each task or domain is inefficient, as it requires repetitive model training, data annotation (e.g., demographic information), and evaluation. In pursuit of a more accessible solution, we propose the Upstream Bias Mitigation for Downstream Fine-Tuning (UBM) framework, which mitigate one or multiple bias factors in downstream classifiers by transfer learning from an upstream model. In the upstream bias mitigation stage, explanation regularization and adversarial training are applied to mitigate multiple bias factors. In the downstream fine-tuning stage, the classifier layer of the model is re-initialized, and the entire model is fine-tuned to downstream tasks in potentially novel domains without any further bias mitigation. We expect downstream classifiers to be less biased by transfer learning from de-biased upstream models. We conduct extensive experiments varying the similarity between the source and target data, as well as varying the number of dimensions of bias (e.g., discrimination against specific social groups or dialects). Our results indicate the proposed UBM framework can effectively reduce bias in downstream classifiers.
Gradient Based Memory Editing for Task-Free Continual Learning
Jun 27, 2020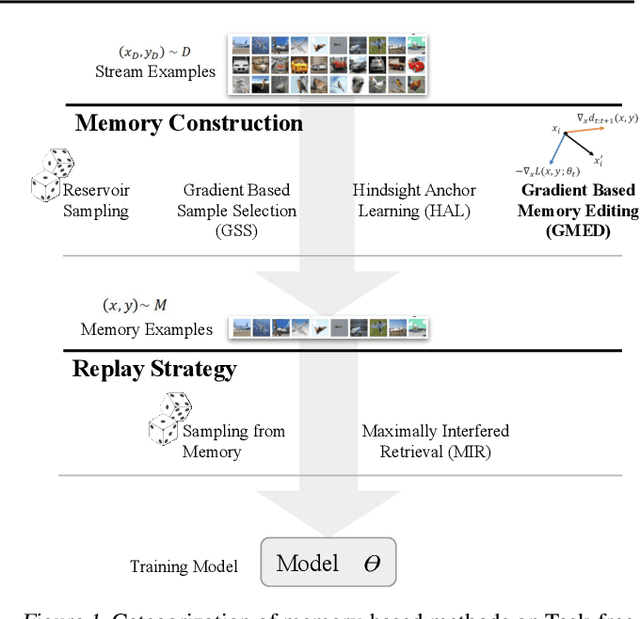
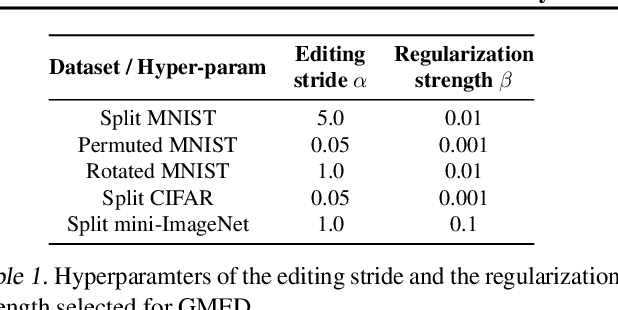
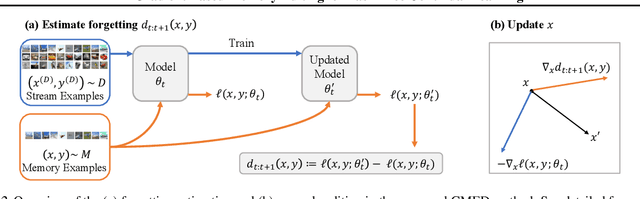
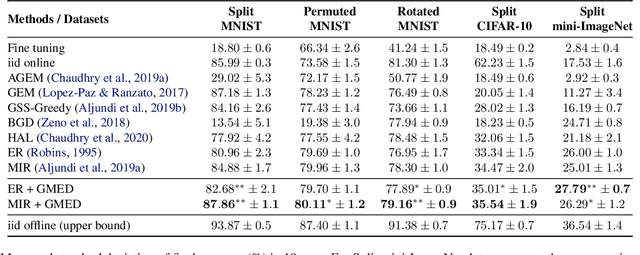
Prior work on continual learning often operate in a "task-aware" manner, by assuming that the task boundaries and identifies of the data instances are known at all times. While in practice, it is rarely the case that such information are exposed to the methods (i.e., thus called "task-free")--a setting that is relatively underexplored. Recent attempts on task-free continual learning build on previous memory replay methods and focus on developing memory management strategies such that model performance over priorly seen instances can be best retained. In this paper, looking from a complementary angle, we propose a principled approach to "edit" stored examples which aims to carry more updated information from the data stream in the memory. We use gradient updates to edit stored examples so that they are more likely to be forgotten in future updates. Experiments on five benchmark datasets show the proposed method can be seamlessly combined with baselines to significantly improve the performance. Code has been released at https://github.com/INK-USC/GMED.
Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 05, 2020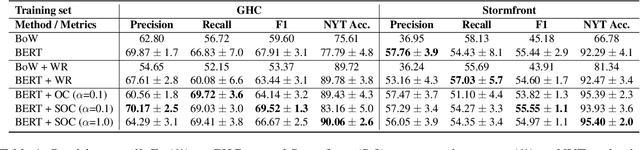
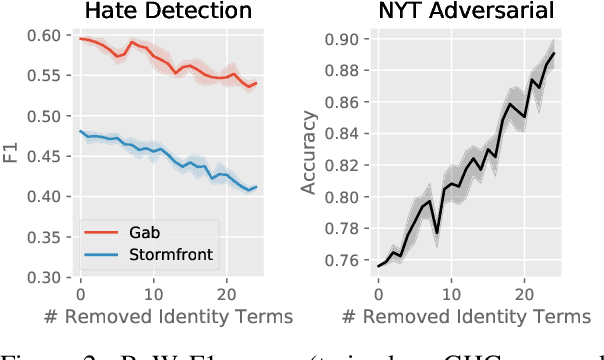
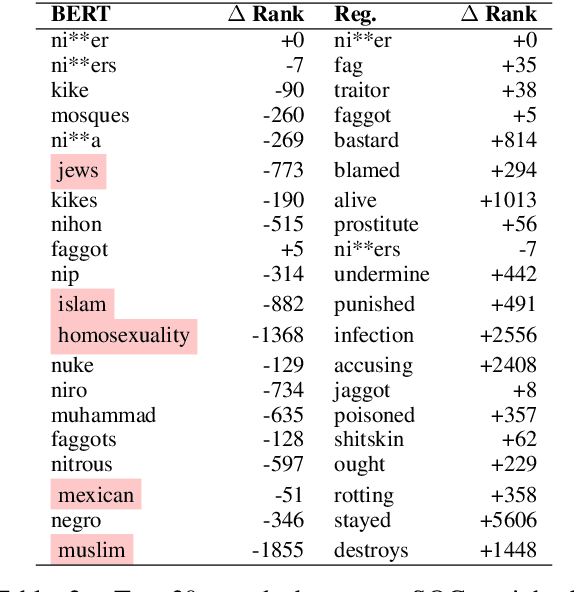

Hate speech classifiers trained on imbalanced datasets struggle to determine if group identifiers like "gay" or "black" are used in offensive or prejudiced ways. Such biases manifest in false positives when these identifiers are present, due to models' inability to learn the contexts which constitute a hateful usage of identifiers. We extract post-hoc explanations from fine-tuned BERT classifiers to detect bias towards identity terms. Then, we propose a novel regularization technique based on these explanations that encourages models to learn from the context of group identifiers in addition to the identifiers themselves. Our approach improved over baselines in limiting false positives on out-of-domain data while maintaining or improving in-domain performance.