 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Robustness of Large Language Models
May 28, 2025


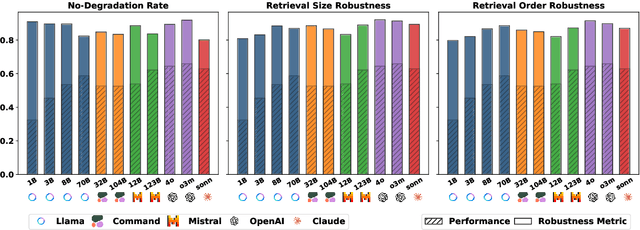
Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
An Alternative to FLOPS Regularization to Effectively Productionize SPLADE-Doc
May 21, 2025

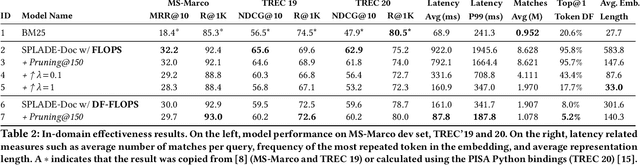

Learned Sparse Retrieval (LSR) models encode text as weighted term vectors, which need to be sparse to leverage inverted index structures during retrieval. SPLADE, the most popular LSR model, uses FLOPS regularization to encourage vector sparsity during training. However, FLOPS regularization does not ensure sparsity among terms - only within a given query or document. Terms with very high Document Frequencies (DFs) substantially increase latency in production retrieval engines, such as Apache Solr, due to their lengthy posting lists. To address the issue of high DFs, we present a new variant of FLOPS regularization: DF-FLOPS. This new regularization technique penalizes the usage of high-DF terms, thereby shortening posting lists and reducing retrieval latency. Unlike other inference-time sparsification methods, such as stopword removal, DF-FLOPS regularization allows for the selective inclusion of high-frequency terms in cases where the terms are truly salient. We find that DF-FLOPS successfully reduces the prevalence of high-DF terms and lowers retrieval latency (around 10x faster) in a production-grade engine while maintaining effectiveness both in-domain (only a 2.2-point drop in MRR@10) and cross-domain (improved performance in 12 out of 13 tasks on which we tested). With retrieval latencies on par with BM25, this work provides an important step towards making LSR practical for deployment in production-grade search engines.
Improving Instruct Models for Free: A Study on Partial Adaptation
Apr 15, 2025Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model being overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.
Unsupervised Contrast-Consistent Ranking with Language Models
Sep 13, 2023

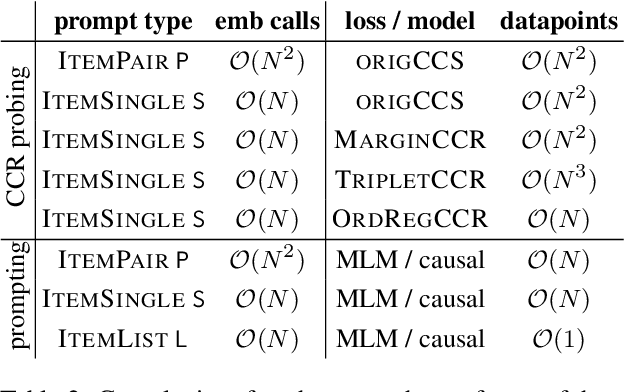
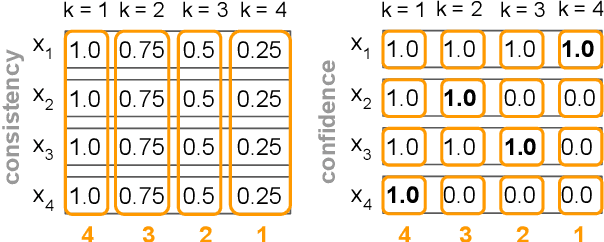
Language models contain ranking-based knowledge and are powerful solvers of in-context ranking tasks. For instance, they may have parametric knowledge about the ordering of countries by size or may be able to rank reviews by sentiment. Recent work focuses on pairwise, pointwise, and listwise prompting techniques to elicit a language model's ranking knowledge. However, we find that even with careful calibration and constrained decoding, prompting-based techniques may not always be self-consistent in the rankings they produce. This motivates us to explore an alternative approach that is inspired by an unsupervised probing method called Contrast-Consistent Search (CCS). The idea is to train a probing model guided by a logical constraint: a model's representation of a statement and its negation must be mapped to contrastive true-false poles consistently across multiple statements. We hypothesize that similar constraints apply to ranking tasks where all items are related via consistent pairwise or listwise comparisons. To this end, we extend the binary CCS method to Contrast-Consistent Ranking (CCR) by adapting existing ranking methods such as the Max-Margin Loss, Triplet Loss, and Ordinal Regression objective. Our results confirm that, for the same language model, CCR probing outperforms prompting and even performs on a par with prompting much larger language models.
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023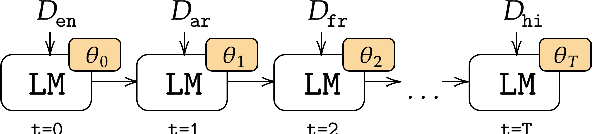
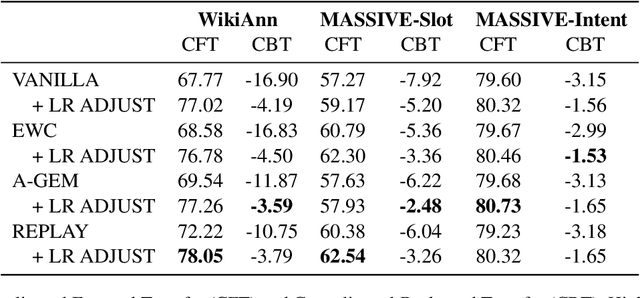
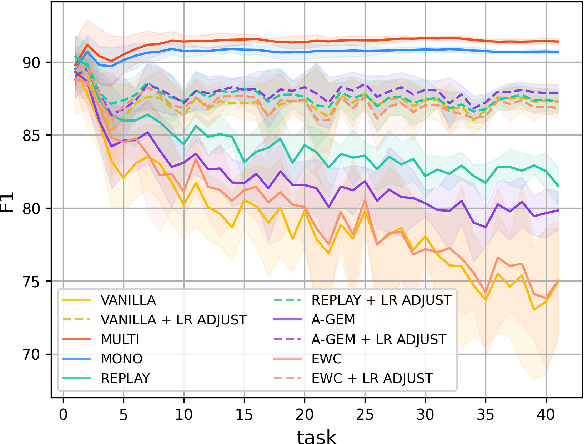
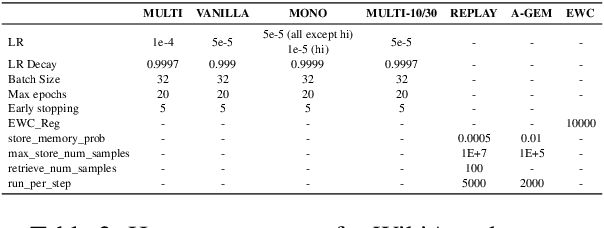
Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
Bounding System-Induced Biases in Recommender Systems with A Randomized Dataset
Mar 21, 2023Debiased recommendation with a randomized dataset has shown very promising results in mitigating the system-induced biases. However, it still lacks more theoretical insights or an ideal optimization objective function compared with the other more well studied route without a randomized dataset. To bridge this gap, we study the debiasing problem from a new perspective and propose to directly minimize the upper bound of an ideal objective function, which facilitates a better potential solution to the system-induced biases. Firstly, we formulate a new ideal optimization objective function with a randomized dataset. Secondly, according to the prior constraints that an adopted loss function may satisfy, we derive two different upper bounds of the objective function, i.e., a generalization error bound with the triangle inequality and a generalization error bound with the separability. Thirdly, we show that most existing related methods can be regarded as the insufficient optimization of these two upper bounds. Fourthly, we propose a novel method called debiasing approximate upper bound with a randomized dataset (DUB), which achieves a more sufficient optimization of these upper bounds. Finally, we conduct extensive experiments on a public dataset and a real product dataset to verify the effectiveness of our DUB.
Dataless Knowledge Fusion by Merging Weights of Language Models
Dec 19, 2022



Fine-tuning pre-trained language models has become the prevalent paradigm for building downstream NLP models. Oftentimes fine-tuned models are readily available but their training data is not, due to data privacy or intellectual property concerns. This creates a barrier to fusing knowledge across individual models to yield a better single model. In this paper, we study the problem of merging individual models built on different training data sets to obtain a single model that performs well both across all data set domains and can generalize on out-of-domain data. We propose a dataless knowledge fusion method that merges models in their parameter space, guided by weights that minimize prediction differences between the merged model and the individual models. Over a battery of evaluation settings, we show that the proposed method significantly outperforms baselines such as Fisher-weighted averaging or model ensembling. Further, we find that our method is a promising alternative to multi-task learning that can preserve or sometimes improve over the individual models without access to the training data. Finally, model merging is more efficient than training a multi-task model, thus making it applicable to a wider set of scenarios.
DIWIFT: Discovering Instance-wise Influential Features for Tabular Data
Jul 06, 2022
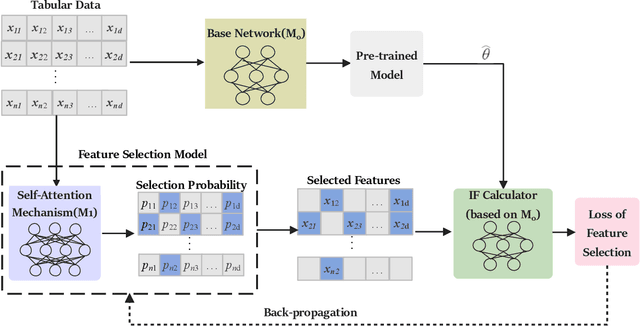
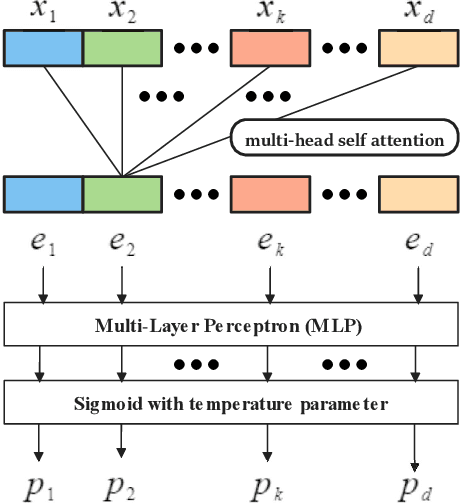
Tabular data is one of the most common data storage formats in business applications, ranging from retail, bank and E-commerce. These applications rely heavily on machine learning models to achieve business success. One of the critical problems in learning tabular data is to distinguish influential features from all the predetermined features. Global feature selection has been well-studied for quite some time, assuming that all instances have the same influential feature subsets. However, different instances rely on different feature subsets in practice, which also gives rise to that instance-wise feature selection receiving increasing attention in recent studies. In this paper, we first propose a novel method for discovering instance-wise influential features for tabular data (DIWIFT), the core of which is to introduce the influence function to measure the importance of an instance-wise feature. DIWIFT is capable of automatically discovering influential feature subsets of different sizes in different instances, which is different from global feature selection that considers all instances with the same influential feature subset. On the other hand, different from the previous instance-wise feature selection, DIWIFT minimizes the validation loss on the validation set and is thus more robust to the distribution shift existing in the training dataset and test dataset, which is important in tabular data. Finally, we conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness of our DIWIFT, compared it with baseline methods. Moreover, we also demonstrate the robustness of our method via some ablation experiments.
MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection
Feb 13, 2020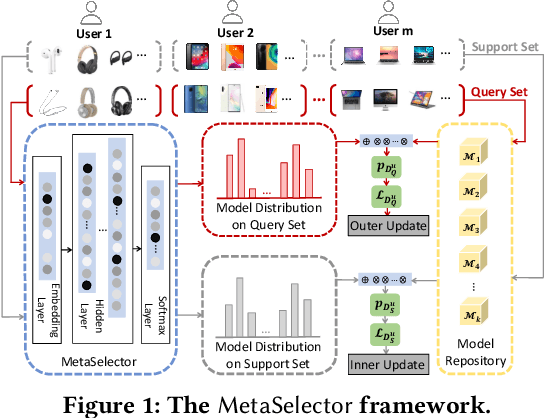
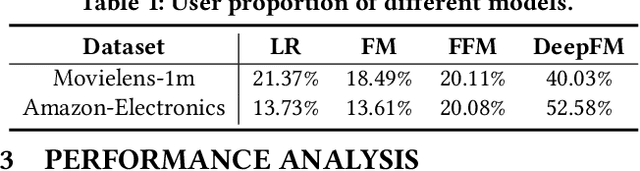
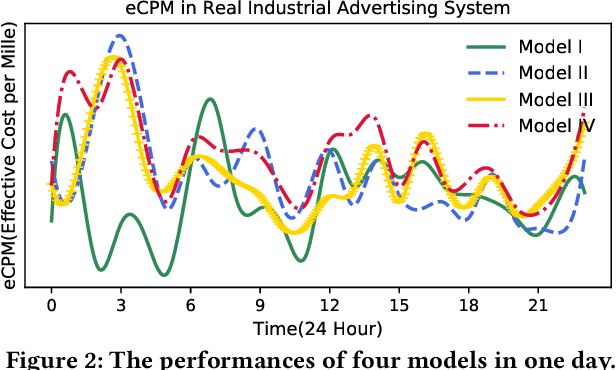
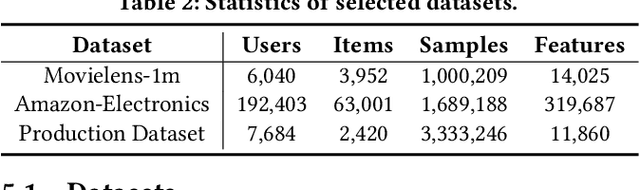
Recommender systems often face heterogeneous datasets containing highly personalized historical data of users, where no single model could give the best recommendation for every user. We observe this ubiquitous phenomenon on both public and private datasets and address the model selection problem in pursuit of optimizing the quality of recommendation for each user. We propose a meta-learning framework to facilitate user-level adaptive model selection in recommender systems. In this framework, a collection of recommenders is trained with data from all users, on top of which a model selector is trained via meta-learning to select the best single model for each user with the user-specific historical data. We conduct extensive experiments on two public datasets and a real-world production dataset, demonstrating that our proposed framework achieves improvements over single model baselines and sample-level model selector in terms of AUC and LogLoss. In particular, the improvements may lead to huge profit gain when deployed in online recommender systems.
Attending to Entities for Better Text Understanding
Nov 11, 2019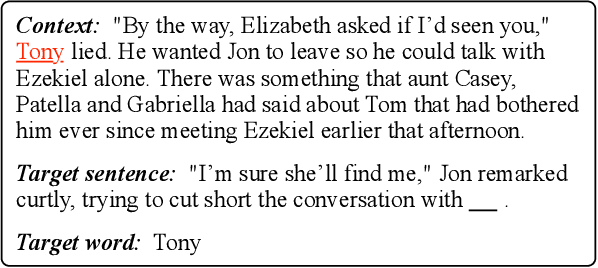

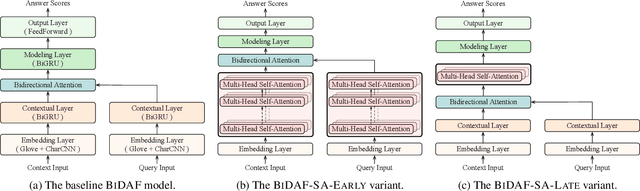

Recent progress in NLP witnessed the development of large-scale pre-trained language models (GPT, BERT, XLNet, etc.) based on Transformer (Vaswani et al. 2017), and in a range of end tasks, such models have achieved state-of-the-art results, approaching human performance. This demonstrates the power of the stacked self-attention architecture when paired with a sufficient number of layers and a large amount of pre-training data. However, on tasks that require complex and long-distance reasoning where surface-level cues are not enough, there is still a large gap between the pre-trained models and human performance. Strubell et al. (2018) recently showed that it is possible to inject knowledge of syntactic structure into a model through supervised self-attention. We conjecture that a similar injection of semantic knowledge, in particular, coreference information, into an existing model would improve performance on such complex problems. On the LAMBADA (Paperno et al. 2016) task, we show that a model trained from scratch with coreference as auxiliary supervision for self-attention outperforms the largest GPT-2 model, setting the new state-of-the-art, while only containing a tiny fraction of parameters compared to GPT-2. We also conduct a thorough analysis of different variants of model architectures and supervision configurations, suggesting future directions on applying similar techniques to other problems.