 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIWIFT: Discovering Instance-wise Influential Features for Tabular Data
Paper and Code
Jul 06, 2022
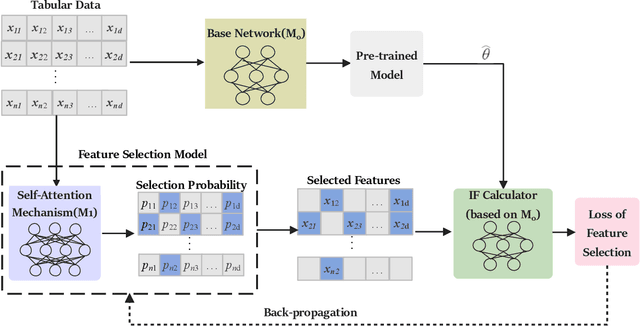
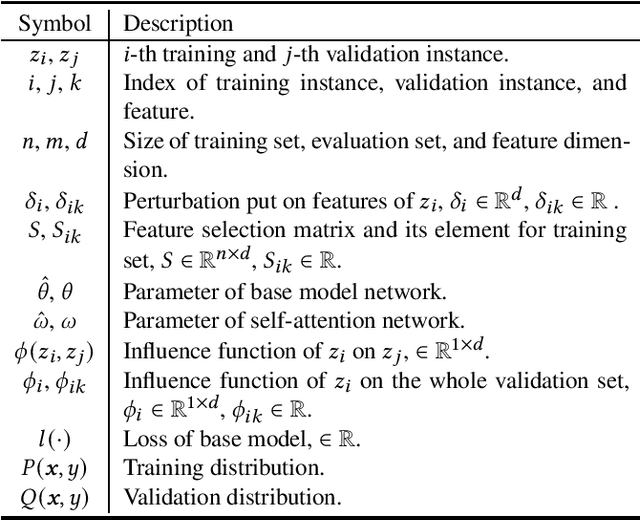
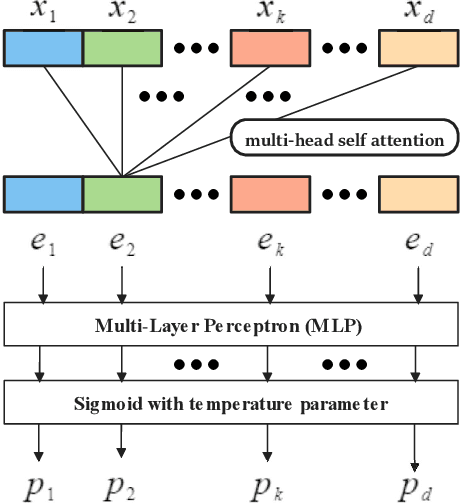
Tabular data is one of the most common data storage formats in business applications, ranging from retail, bank and E-commerce. These applications rely heavily on machine learning models to achieve business success. One of the critical problems in learning tabular data is to distinguish influential features from all the predetermined features. Global feature selection has been well-studied for quite some time, assuming that all instances have the same influential feature subsets. However, different instances rely on different feature subsets in practice, which also gives rise to that instance-wise feature selection receiving increasing attention in recent studies. In this paper, we first propose a novel method for discovering instance-wise influential features for tabular data (DIWIFT), the core of which is to introduce the influence function to measure the importance of an instance-wise feature. DIWIFT is capable of automatically discovering influential feature subsets of different sizes in different instances, which is different from global feature selection that considers all instances with the same influential feature subset. On the other hand, different from the previous instance-wise feature selection, DIWIFT minimizes the validation loss on the validation set and is thus more robust to the distribution shift existing in the training dataset and test dataset, which is important in tabular data. Finally, we conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness of our DIWIFT, compared it with baseline methods. Moreover, we also demonstrate the robustness of our method via some ablation experiments.