 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Robustness of Large Language Models
May 28, 2025


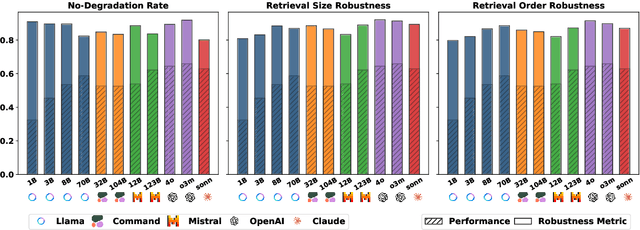
Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
An Alternative to FLOPS Regularization to Effectively Productionize SPLADE-Doc
May 21, 2025

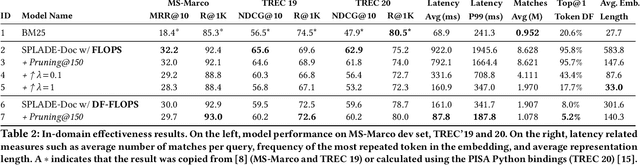

Learned Sparse Retrieval (LSR) models encode text as weighted term vectors, which need to be sparse to leverage inverted index structures during retrieval. SPLADE, the most popular LSR model, uses FLOPS regularization to encourage vector sparsity during training. However, FLOPS regularization does not ensure sparsity among terms - only within a given query or document. Terms with very high Document Frequencies (DFs) substantially increase latency in production retrieval engines, such as Apache Solr, due to their lengthy posting lists. To address the issue of high DFs, we present a new variant of FLOPS regularization: DF-FLOPS. This new regularization technique penalizes the usage of high-DF terms, thereby shortening posting lists and reducing retrieval latency. Unlike other inference-time sparsification methods, such as stopword removal, DF-FLOPS regularization allows for the selective inclusion of high-frequency terms in cases where the terms are truly salient. We find that DF-FLOPS successfully reduces the prevalence of high-DF terms and lowers retrieval latency (around 10x faster) in a production-grade engine while maintaining effectiveness both in-domain (only a 2.2-point drop in MRR@10) and cross-domain (improved performance in 12 out of 13 tasks on which we tested). With retrieval latencies on par with BM25, this work provides an important step towards making LSR practical for deployment in production-grade search engines.
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023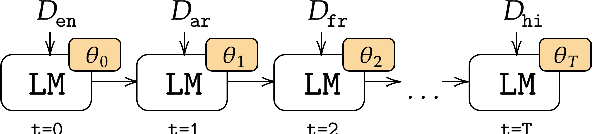
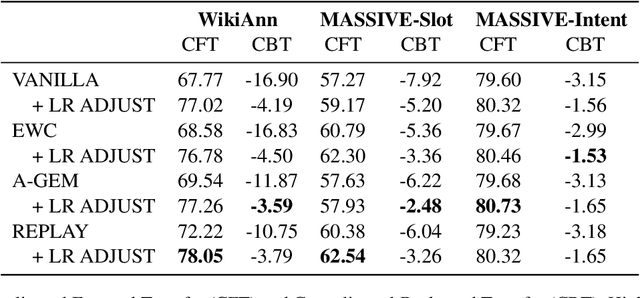
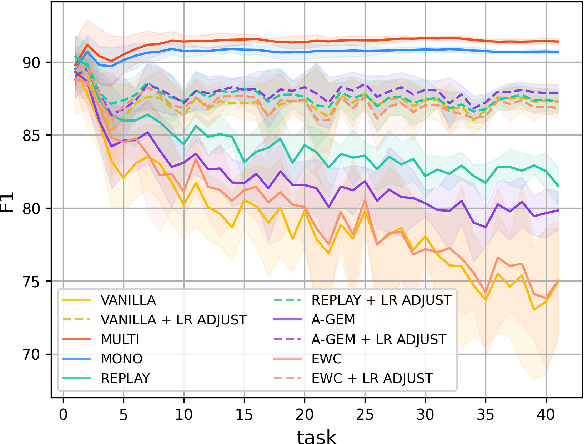
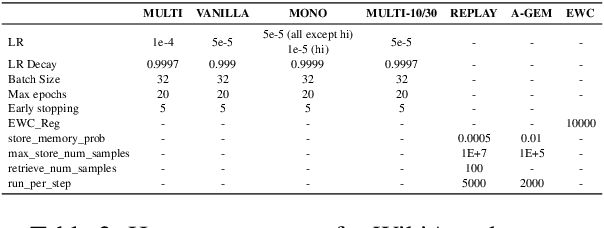
Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
Detecting Community Sensitive Norm Violations in Online Conversations
Oct 09, 2021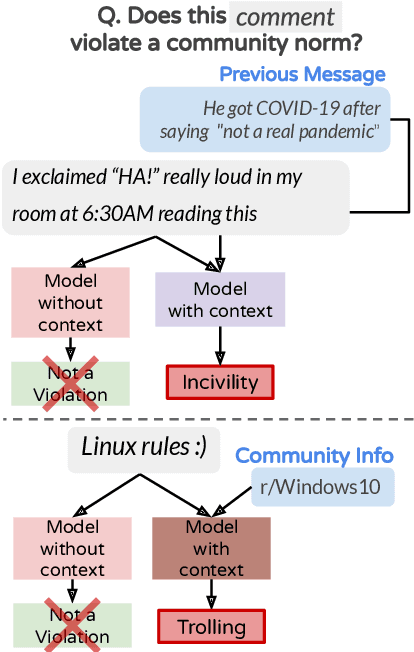
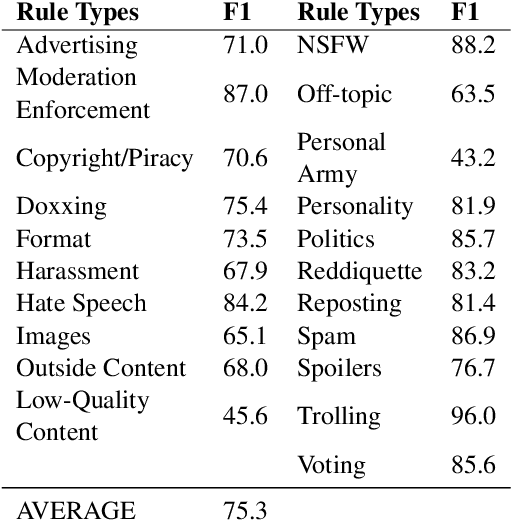
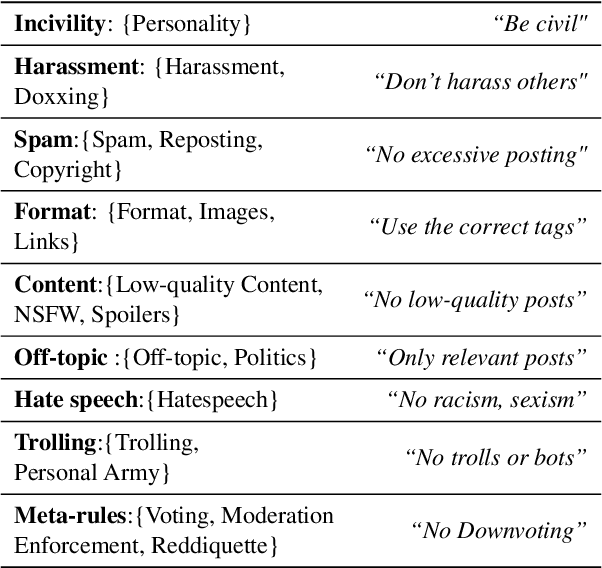
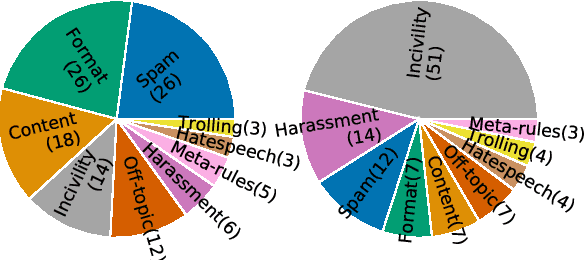
Online platforms and communities establish their own norms that govern what behavior is acceptable within the community. Substantial effort in NLP has focused on identifying unacceptable behaviors and, recently, on forecasting them before they occur. However, these efforts have largely focused on toxicity as the sole form of community norm violation. Such focus has overlooked the much larger set of rules that moderators enforce. Here, we introduce a new dataset focusing on a more complete spectrum of community norms and their violations in the local conversational and global community contexts. We introduce a series of models that use this data to develop context- and community-sensitive norm violation detection, showing that these changes give high performance.
ColloQL: Robust Cross-Domain Text-to-SQL Over Search Queries
Oct 19, 2020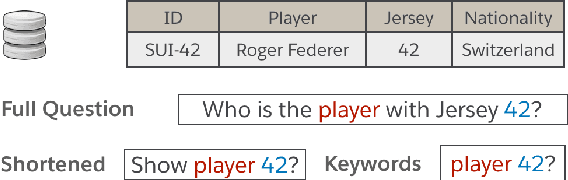

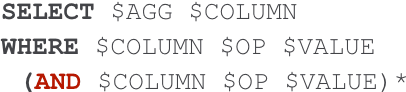

Translating natural language utterances to executable queries is a helpful technique in making the vast amount of data stored in relational databases accessible to a wider range of non-tech-savvy end users. Prior work in this area has largely focused on textual input that is linguistically correct and semantically unambiguous. However, real-world user queries are often succinct, colloquial, and noisy, resembling the input of a search engine. In this work, we introduce data augmentation techniques and a sampling-based content-aware BERT model (ColloQL) to achieve robust text-to-SQL modeling over natural language search (NLS) questions. Due to the lack of evaluation data, we curate a new dataset of NLS questions and demonstrate the efficacy of our approach. ColloQL's superior performance extends to well-formed text, achieving 84.9% (logical) and 90.7% (execution) accuracy on the WikiSQL dataset, making it, to the best of our knowledge, the highest performing model that does not use execution guided decoding.