 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen People are Floods: Analyzing Dehumanizing Metaphors in Immigration Discourse with Large Language Models
Feb 18, 2025Metaphor, discussing one concept in terms of another, is abundant in politics and can shape how people understand important issues. We develop a computational approach to measure metaphorical language, focusing on immigration discourse on social media. Grounded in qualitative social science research, we identify seven concepts evoked in immigration discourse (e.g. "water" or "vermin"). We propose and evaluate a novel technique that leverages both word-level and document-level signals to measure metaphor with respect to these concepts. We then study the relationship between metaphor, political ideology, and user engagement in 400K US tweets about immigration. While conservatives tend to use dehumanizing metaphors more than liberals, this effect varies widely across concepts. Moreover, creature-related metaphor is associated with more retweets, especially for liberal authors. Our work highlights the potential for computational methods to complement qualitative approaches in understanding subtle and implicit language in political discourse.
AI-LieDar: Examine the Trade-off Between Utility and Truthfulness in LLM Agents
Sep 13, 2024


To be safely and successfully deployed, LLMs must simultaneously satisfy truthfulness and utility goals. Yet, often these two goals compete (e.g., an AI agent assisting a used car salesman selling a car with flaws), partly due to ambiguous or misleading user instructions. We propose AI-LieDar, a framework to study how LLM-based agents navigate scenarios with utility-truthfulness conflicts in a multi-turn interactive setting. We design a set of realistic scenarios where language agents are instructed to achieve goals that are in conflict with being truthful during a multi-turn conversation with simulated human agents. To evaluate the truthfulness at large scale, we develop a truthfulness detector inspired by psychological literature to assess the agents' responses. Our experiment demonstrates that all models are truthful less than 50% of the time, although truthfulness and goal achievement (utility) rates vary across models. We further test the steerability of LLMs towards truthfulness, finding that models follow malicious instructions to deceive, and even truth-steered models can still lie. These findings reveal the complex nature of truthfulness in LLMs and underscore the importance of further research to ensure the safe and reliable deployment of LLMs and AI agents.
Framing Social Movements on Social Media: Unpacking Diagnostic, Prognostic, and Motivational Strategies
Jun 19, 2024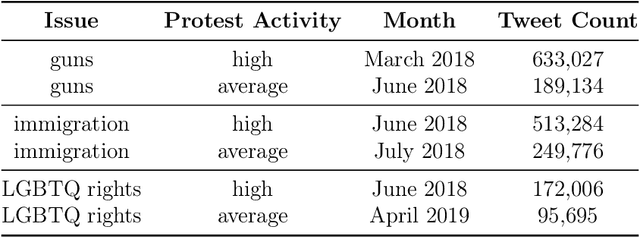
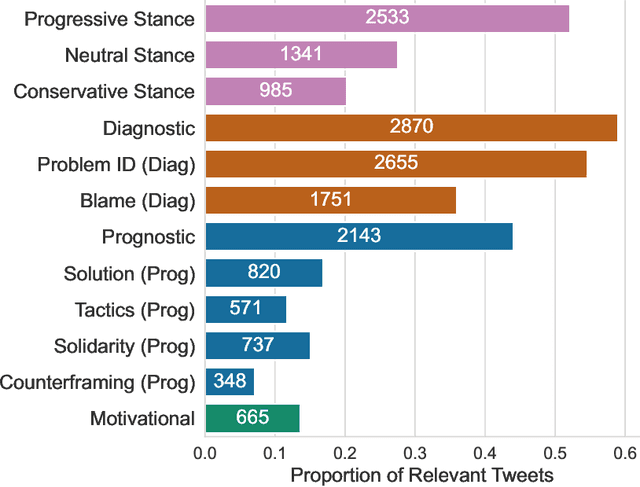
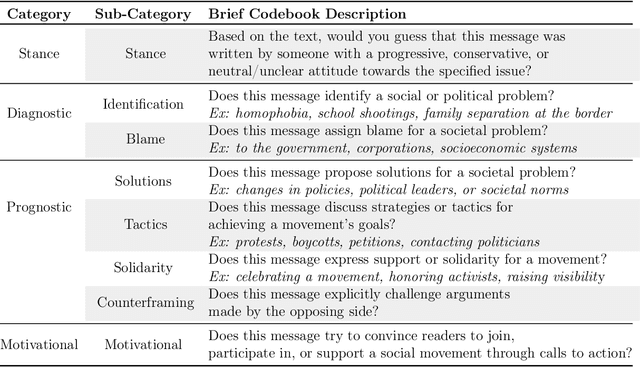
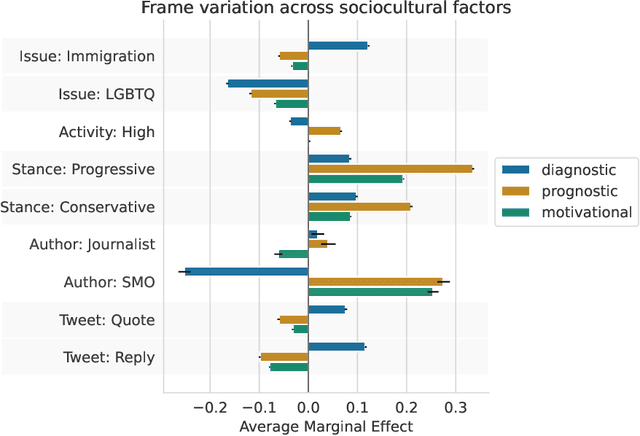
Social media enables activists to directly communicate with the public and provides a space for movement leaders, participants, bystanders, and opponents to collectively construct and contest narratives. Focusing on Twitter messages from social movements surrounding three issues in 2018-2019 (guns, immigration, and LGBTQ rights), we create a codebook, annotated dataset, and computational models to detect diagnostic (problem identification and attribution), prognostic (proposed solutions and tactics), and motivational (calls to action) framing strategies. We conduct an in-depth unsupervised linguistic analysis of each framing strategy, and uncover cross-movement similarities in associations between framing and linguistic features such as pronouns and deontic modal verbs. Finally, we compare framing strategies across issues and other social, cultural, and interactional contexts. For example, we show that diagnostic framing is more common in replies than original broadcast posts, and that social movement organizations focus much more on prognostic and motivational framing than journalists and ordinary citizens.
* Published in ICWSM Special Issue of the Journal of Quantitative Description: Digital Media
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Jun 17, 2024



Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
How AI Ideas Affect the Creativity, Diversity, and Evolution of Human Ideas: Evidence From a Large, Dynamic Experiment
Jan 24, 2024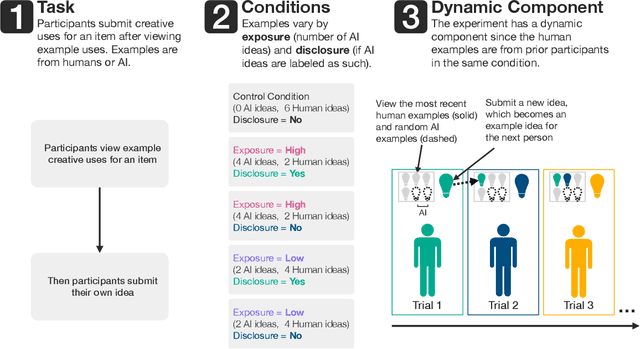
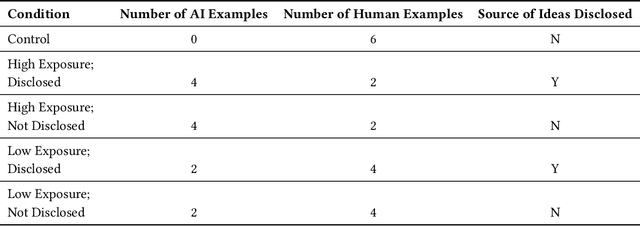


Exposure to large language model output is rapidly increasing. How will seeing AI-generated ideas affect human ideas? We conducted an experiment (800+ participants, 40+ countries) where participants viewed creative ideas that were from ChatGPT or prior experimental participants and then brainstormed their own idea. We varied the number of AI-generated examples (none, low, or high exposure) and if the examples were labeled as 'AI' (disclosure). Our dynamic experiment design -- ideas from prior participants in an experimental condition are used as stimuli for future participants in the same experimental condition -- mimics the interdependent process of cultural creation: creative ideas are built upon prior ideas. Hence, we capture the compounding effects of having LLMs 'in the culture loop'. We find that high AI exposure (but not low AI exposure) did not affect the creativity of individual ideas but did increase the average amount and rate of change of collective idea diversity. AI made ideas different, not better. There were no main effects of disclosure. We also found that self-reported creative people were less influenced by knowing an idea was from AI, and that participants were more likely to knowingly adopt AI ideas when the task was difficult. Our findings suggest that introducing AI ideas into society may increase collective diversity but not individual creativity.
From Dogwhistles to Bullhorns: Unveiling Coded Rhetoric with Language Models
May 26, 2023Dogwhistles are coded expressions that simultaneously convey one meaning to a broad audience and a second one, often hateful or provocative, to a narrow in-group; they are deployed to evade both political repercussions and algorithmic content moderation. For example, in the sentence 'we need to end the cosmopolitan experiment,' the word 'cosmopolitan' likely means 'worldly' to many, but secretly means 'Jewish' to a select few. We present the first large-scale computational investigation of dogwhistles. We develop a typology of dogwhistles, curate the largest-to-date glossary of over 300 dogwhistles with rich contextual information and examples, and analyze their usage in historical U.S. politicians' speeches. We then assess whether a large language model (GPT-3) can identify dogwhistles and their meanings, and find that GPT-3's performance varies widely across types of dogwhistles and targeted groups. Finally, we show that harmful content containing dogwhistles avoids toxicity detection, highlighting online risks of such coded language. This work sheds light on the theoretical and applied importance of dogwhistles in both NLP and computational social science, and provides resources for future research in modeling dogwhistles and mitigating their online harms.
Bridging Nations: Quantifying the Role of Multilinguals in Communication on Social Media
Apr 07, 2023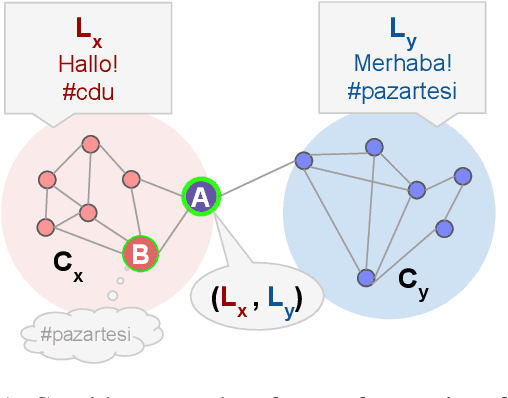
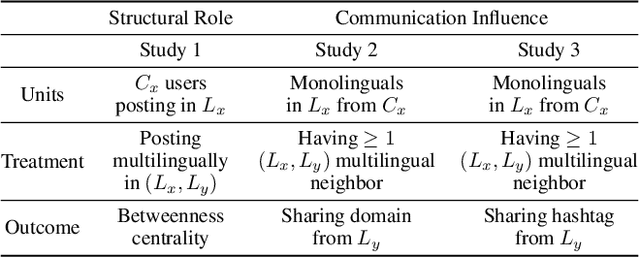

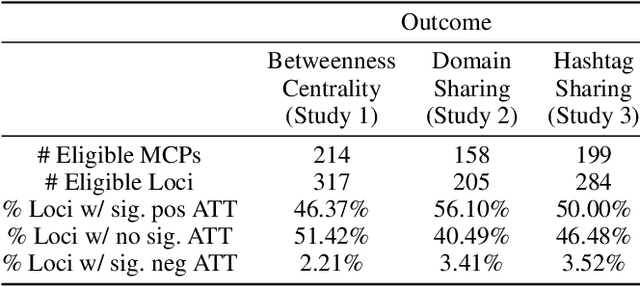
Social media enables the rapid spread of many kinds of information, from memes to social movements. However, little is known about how information crosses linguistic boundaries. We apply causal inference techniques on the European Twitter network to quantify multilingual users' structural role and communication influence in cross-lingual information exchange. Overall, multilinguals play an essential role; posting in multiple languages increases betweenness centrality by 13%, and having a multilingual network neighbor increases monolinguals' odds of sharing domains and hashtags from another language 16-fold and 4-fold, respectively. We further show that multilinguals have a greater impact on diffusing information less accessible to their monolingual compatriots, such as information from far-away countries and content about regional politics, nascent social movements, and job opportunities. By highlighting information exchange across borders, this work sheds light on a crucial component of how information and ideas spread around the world.
VoynaSlov: A Data Set of Russian Social Media Activity during the 2022 Ukraine-Russia War
May 24, 2022
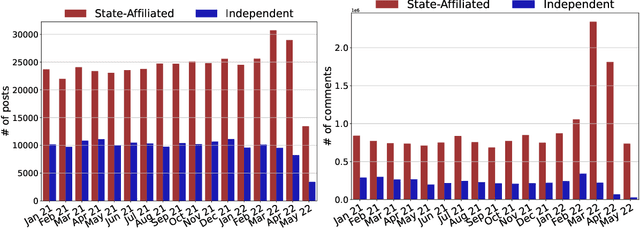
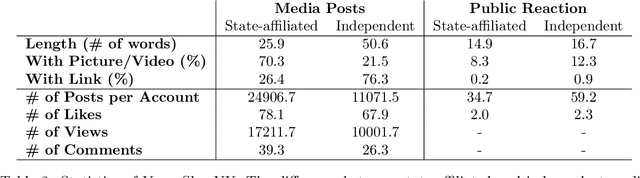
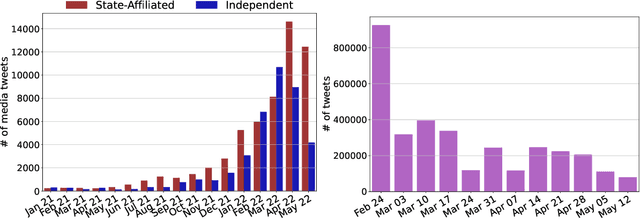
In this report, we describe a new data set called VoynaSlov which contains 21M+ Russian-language social media activities (i.e. tweets, posts, comments) made by Russian media outlets and by the general public during the time of war between Ukraine and Russia. We scraped the data from two major platforms that are widely used in Russia: Twitter and VKontakte (VK), a Russian social media platform based in Saint Petersburg commonly referred to as "Russian Facebook". We provide descriptions of our data collection process and data statistics that compare state-affiliated and independent Russian media, and also the two platforms, VK and Twitter. The main differences that distinguish our data from previously released data related to the ongoing war are its focus on Russian media and consideration of state-affiliation as well as the inclusion of data from VK, which is more suitable than Twitter for understanding Russian public sentiment considering its wide use within Russia. We hope our data set can facilitate future research on information warfare and ultimately enable the reduction and prevention of disinformation and opinion manipulation campaigns. The data set is available at https://github.com/chan0park/VoynaSlov and will be regularly updated as we continuously collect more data.
Detecting Community Sensitive Norm Violations in Online Conversations
Oct 09, 2021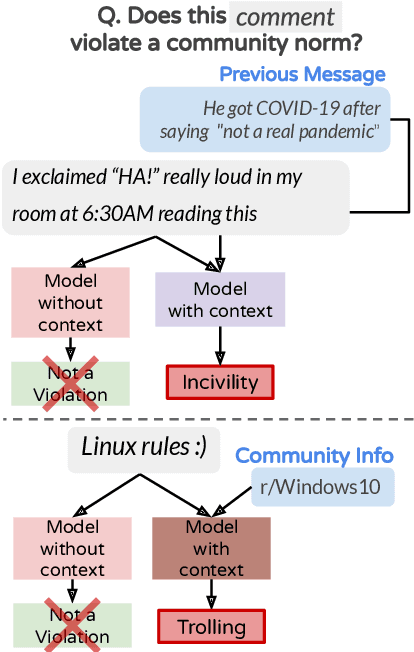
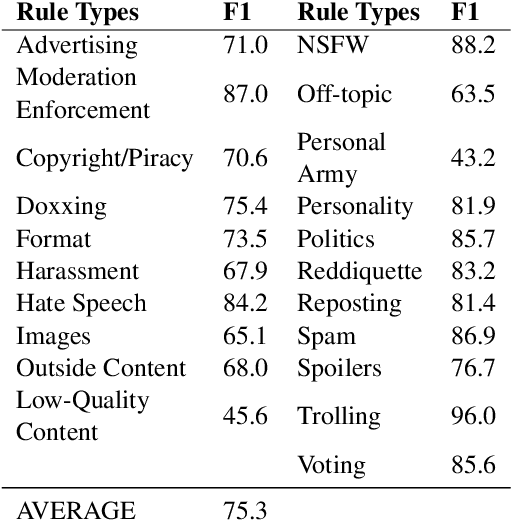
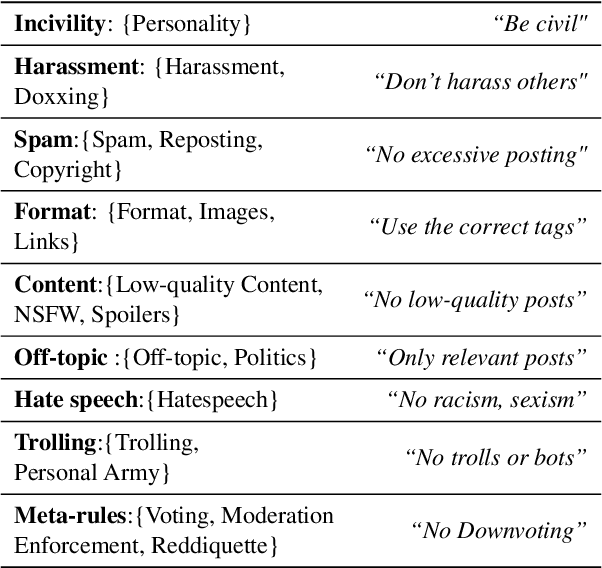
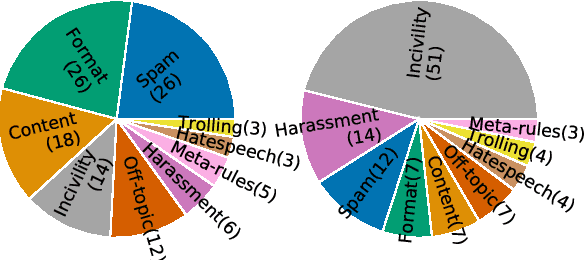
Online platforms and communities establish their own norms that govern what behavior is acceptable within the community. Substantial effort in NLP has focused on identifying unacceptable behaviors and, recently, on forecasting them before they occur. However, these efforts have largely focused on toxicity as the sole form of community norm violation. Such focus has overlooked the much larger set of rules that moderators enforce. Here, we introduce a new dataset focusing on a more complete spectrum of community norms and their violations in the local conversational and global community contexts. We introduce a series of models that use this data to develop context- and community-sensitive norm violation detection, showing that these changes give high performance.
Modeling Framing in Immigration Discourse on Social Media
Apr 13, 2021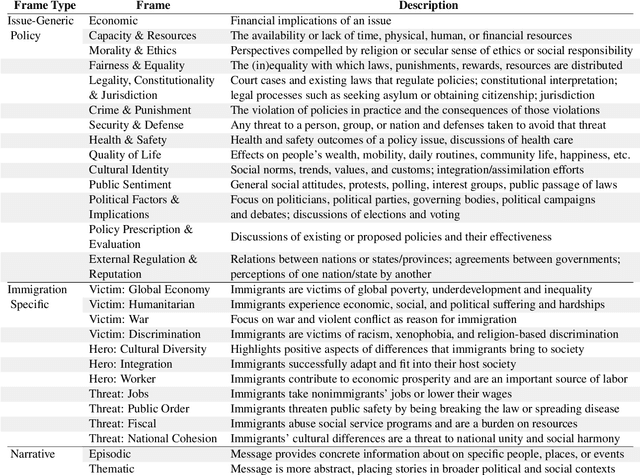
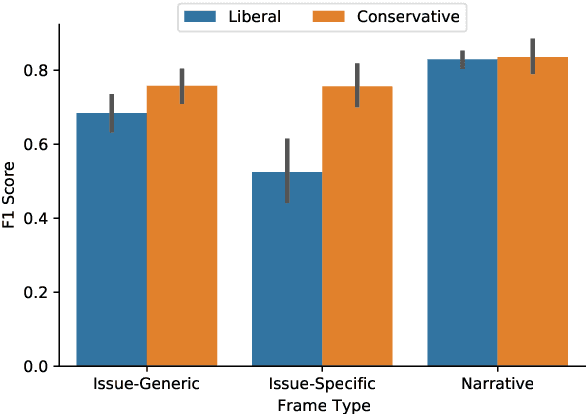
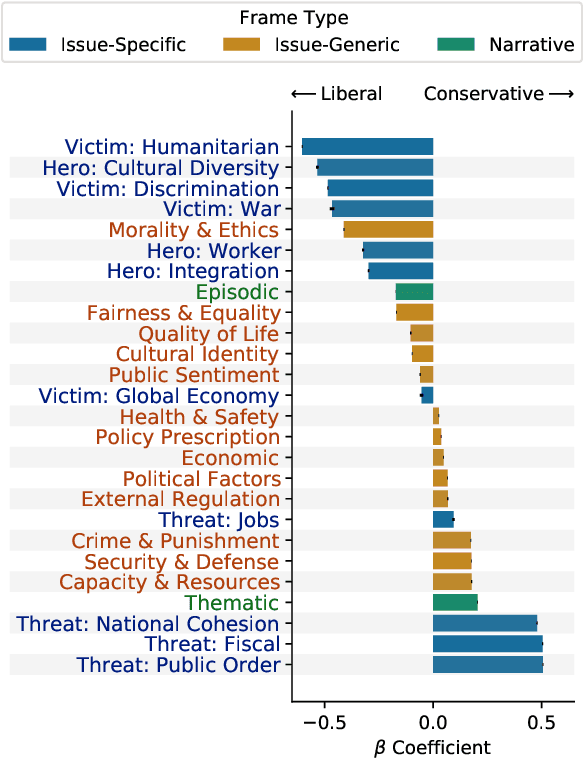

The framing of political issues can influence policy and public opinion. Even though the public plays a key role in creating and spreading frames, little is known about how ordinary people on social media frame political issues. By creating a new dataset of immigration-related tweets labeled for multiple framing typologies from political communication theory, we develop supervised models to detect frames. We demonstrate how users' ideology and region impact framing choices, and how a message's framing influences audience responses. We find that the more commonly-used issue-generic frames obscure important ideological and regional patterns that are only revealed by immigration-specific frames. Furthermore, frames oriented towards human interests, culture, and politics are associated with higher user engagement. This large-scale analysis of a complex social and linguistic phenomenon contributes to both NLP and social science research.