 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Instruct Models for Free: A Study on Partial Adaptation
Apr 15, 2025Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model being overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.
Incorporating Human Explanations for Robust Hate Speech Detection
Nov 09, 2024
Given the black-box nature and complexity of large transformer language models (LM), concerns about generalizability and robustness present ethical implications for domains such as hate speech (HS) detection. Using the content rich Social Bias Frames dataset, containing human-annotated stereotypes, intent, and targeted groups, we develop a three stage analysis to evaluate if LMs faithfully assess hate speech. First, we observe the need for modeling contextually grounded stereotype intents to capture implicit semantic meaning. Next, we design a new task, Stereotype Intent Entailment (SIE), which encourages a model to contextually understand stereotype presence. Finally, through ablation tests and user studies, we find a SIE objective improves content understanding, but challenges remain in modeling implicit intent.
Exploring Gender Disparities in Time to Diagnosis
Nov 15, 2020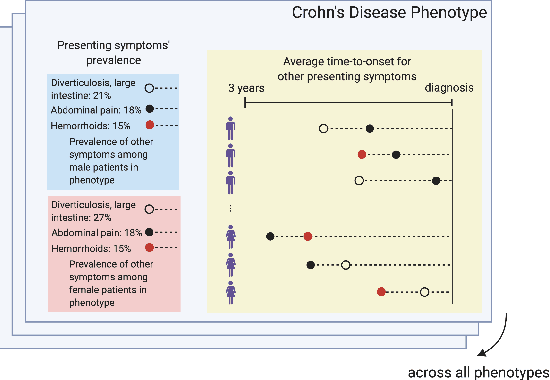

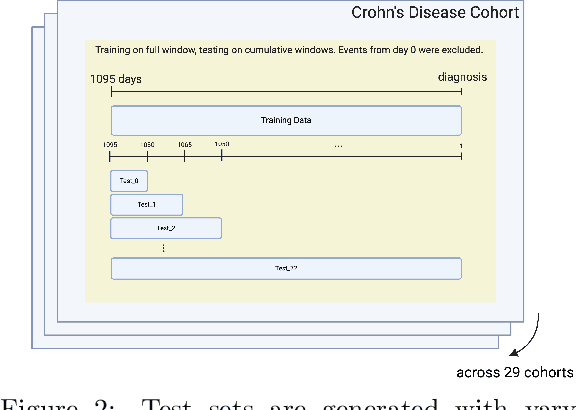
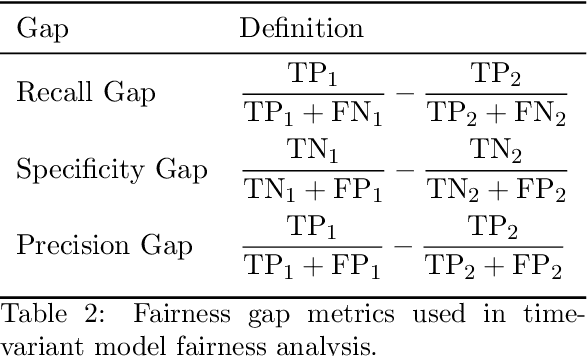
Sex and gender-based healthcare disparities contribute to differences in health outcomes. We focus on time to diagnosis (TTD) by conducting two large-scale, complementary analyses among men and women across 29 phenotypes and 195K patients. We first find that women are consistently more likely to experience a longer TTD than men, even when presenting with the same conditions. We further explore how TTD disparities affect diagnostic performance between genders, both across and persistent to time, by evaluating gender-agnostic disease classifiers across increasing diagnostic information. In both fairness analyses, the diagnostic process favors men over women, contradicting the previous observation that women may demonstrate relevant symptoms earlier than men. These analyses suggest that TTD is an important yet complex aspect when studying gender disparities, and warrants further investigation.