 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Neural Retrieval via In-batch Balancing Regularization
May 18, 2022
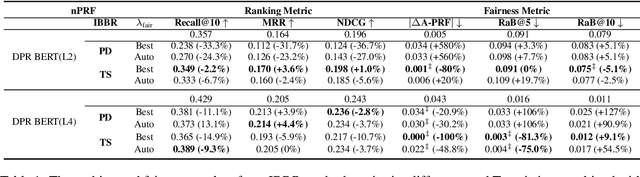
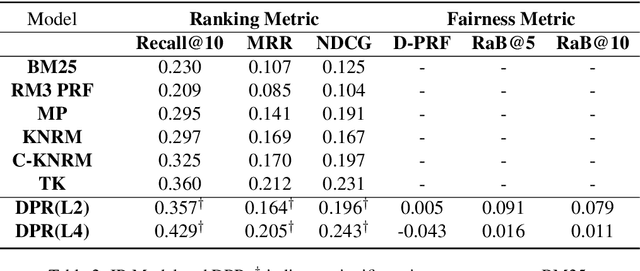
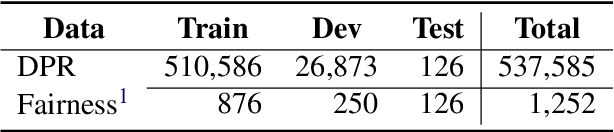
People frequently interact with information retrieval (IR) systems, however, IR models exhibit biases and discrimination towards various demographics. The in-processing fair ranking methods provide a trade-offs between accuracy and fairness through adding a fairness-related regularization term in the loss function. However, there haven't been intuitive objective functions that depend on the click probability and user engagement to directly optimize towards this. In this work, we propose the In-Batch Balancing Regularization (IBBR) to mitigate the ranking disparity among subgroups. In particular, we develop a differentiable \textit{normed Pairwise Ranking Fairness} (nPRF) and leverage the T-statistics on top of nPRF over subgroups as a regularization to improve fairness. Empirical results with the BERT-based neural rankers on the MS MARCO Passage Retrieval dataset with the human-annotated non-gendered queries benchmark \citep{rekabsaz2020neural} show that our IBBR method with nPRF achieves significantly less bias with minimal degradation in ranking performance compared with the baseline.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022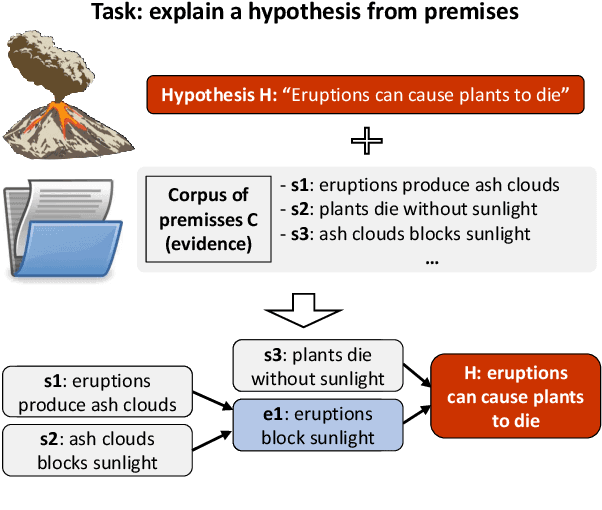
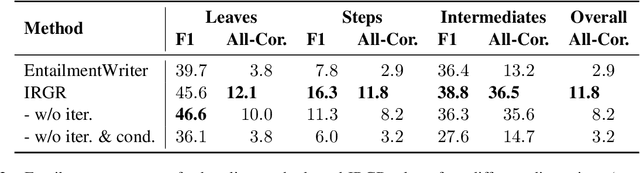
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
Mar 21, 2022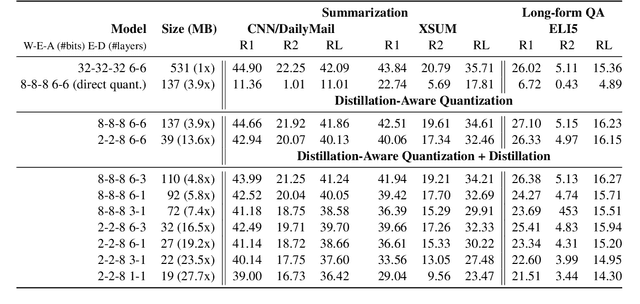
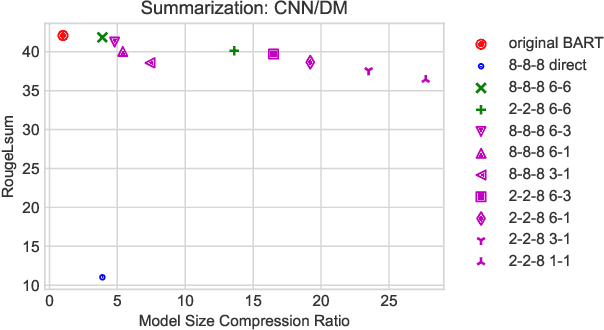
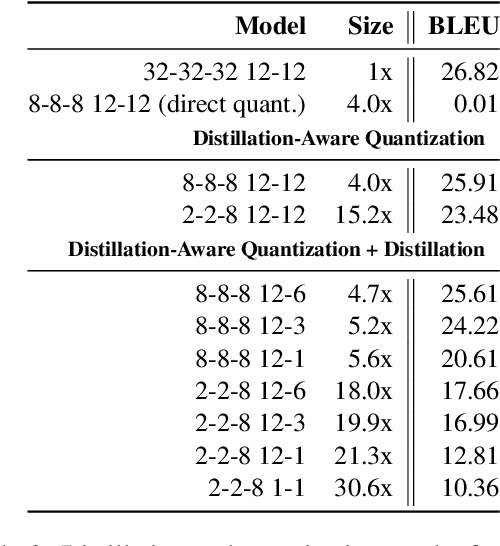
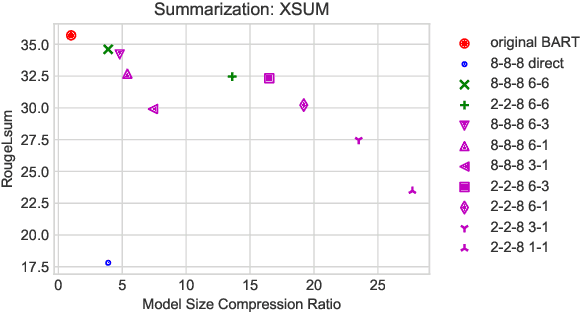
Large-scale pre-trained sequence-to-sequence models like BART and T5 achieve state-of-the-art performance on many generative NLP tasks. However, such models pose a great challenge in resource-constrained scenarios owing to their large memory requirements and high latency. To alleviate this issue, we propose to jointly distill and quantize the model, where knowledge is transferred from the full-precision teacher model to the quantized and distilled low-precision student model. Empirical analyses show that, despite the challenging nature of generative tasks, we were able to achieve a 16.5x model footprint compression ratio with little performance drop relative to the full-precision counterparts on multiple summarization and QA datasets. We further pushed the limit of compression ratio to 27.7x and presented the performance-efficiency trade-off for generative tasks using pre-trained models. To the best of our knowledge, this is the first work aiming to effectively distill and quantize sequence-to-sequence pre-trained models for language generation tasks.
QaNER: Prompting Question Answering Models for Few-shot Named Entity Recognition
Mar 04, 2022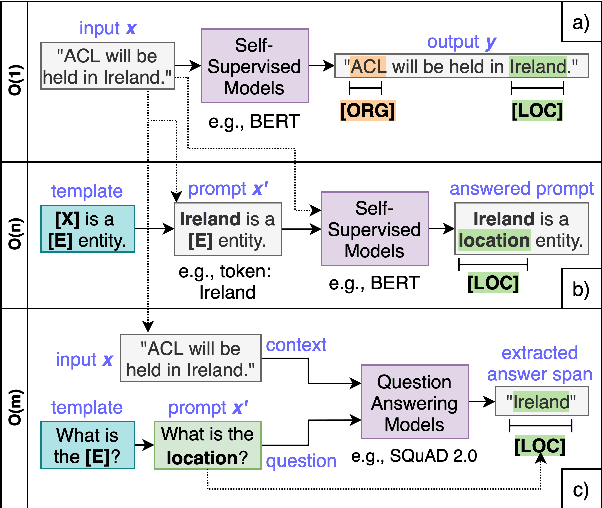

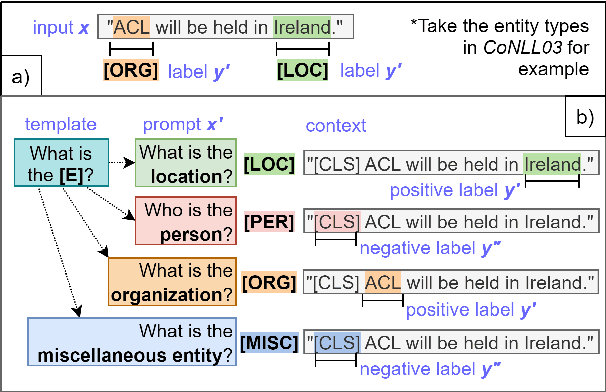
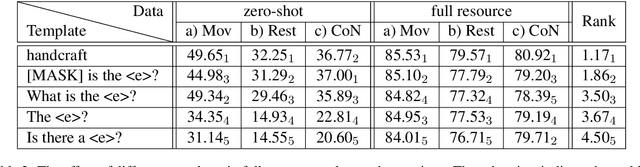
Recently, prompt-based learning for pre-trained language models has succeeded in few-shot Named Entity Recognition (NER) by exploiting prompts as task guidance to increase label efficiency. However, previous prompt-based methods for few-shot NER have limitations such as a higher computational complexity, poor zero-shot ability, requiring manual prompt engineering, or lack of prompt robustness. In this work, we address these shortcomings by proposing a new prompt-based learning NER method with Question Answering (QA), called QaNER. Our approach includes 1) a refined strategy for converting NER problems into the QA formulation; 2) NER prompt generation for QA models; 3) prompt-based tuning with QA models on a few annotated NER examples; 4) zero-shot NER by prompting the QA model. Comparing the proposed approach with previous methods, QaNER is faster at inference, insensitive to the prompt quality, and robust to hyper-parameters, as well as demonstrating significantly better low-resource performance and zero-shot capability.
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021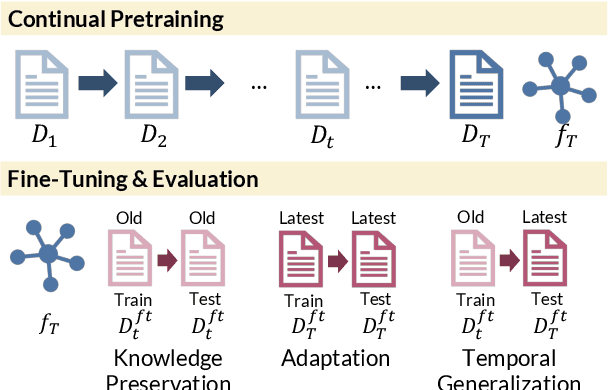
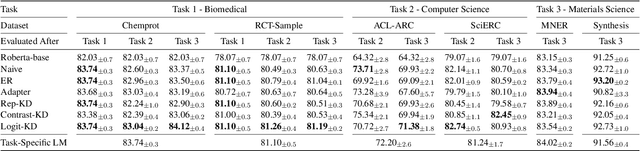
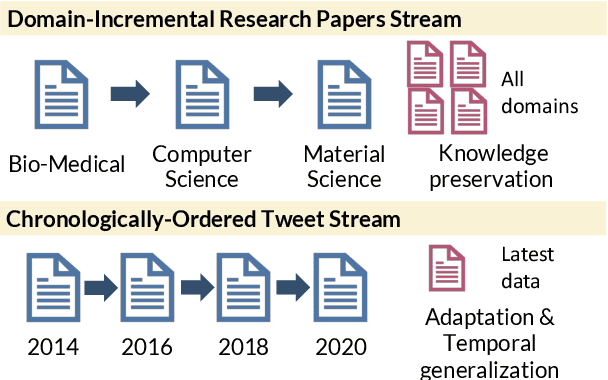
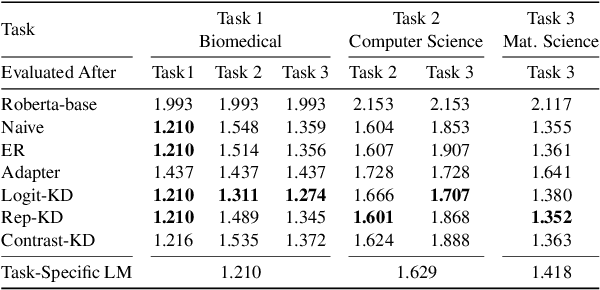
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Knowledge Enhanced Pretrained Language Models: A Compreshensive Survey
Oct 16, 2021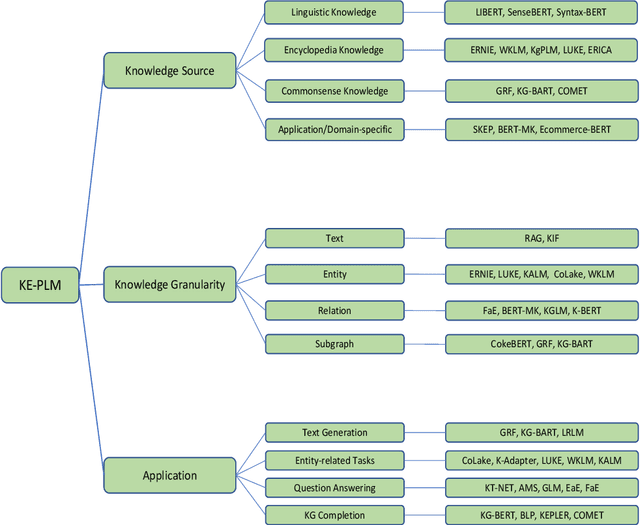

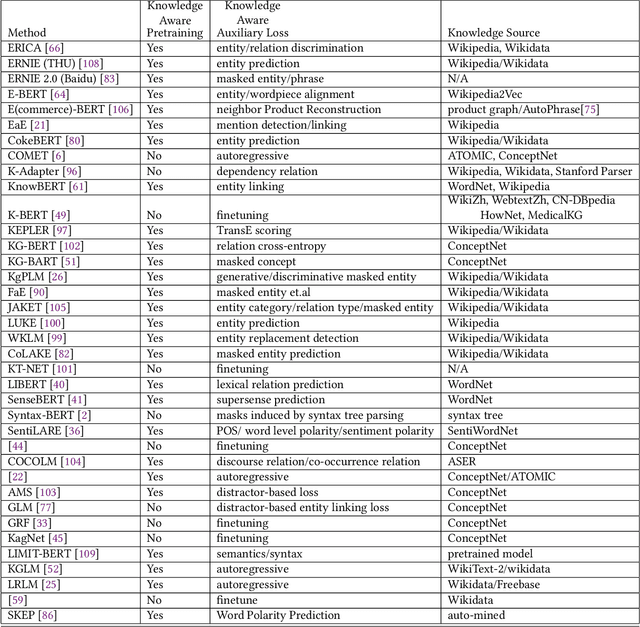
Pretrained Language Models (PLM) have established a new paradigm through learning informative contextualized representations on large-scale text corpus. This new paradigm has revolutionized the entire field of natural language processing, and set the new state-of-the-art performance for a wide variety of NLP tasks. However, though PLMs could store certain knowledge/facts from training corpus, their knowledge awareness is still far from satisfactory. To address this issue, integrating knowledge into PLMs have recently become a very active research area and a variety of approaches have been developed. In this paper, we provide a comprehensive survey of the literature on this emerging and fast-growing field - Knowledge Enhanced Pretrained Language Models (KE-PLMs). We introduce three taxonomies to categorize existing work. Besides, we also survey the various NLU and NLG applications on which KE-PLM has demonstrated superior performance over vanilla PLMs. Finally, we discuss challenges that face KE-PLMs and also promising directions for future research.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
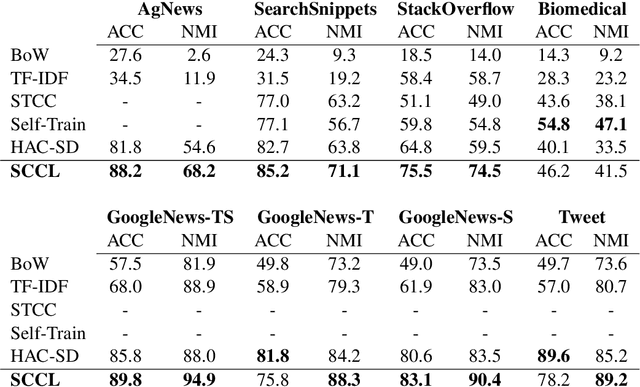
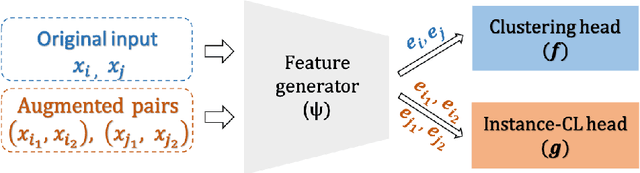
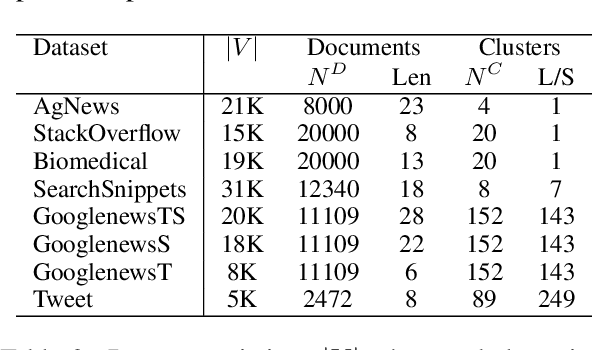
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels
Neural document expansion for ad-hoc information retrieval
Dec 27, 2020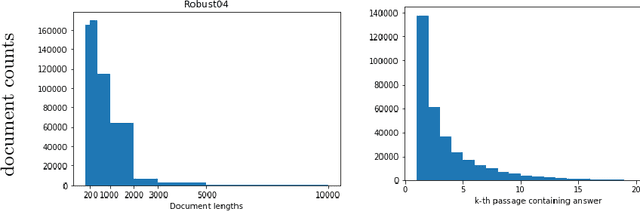
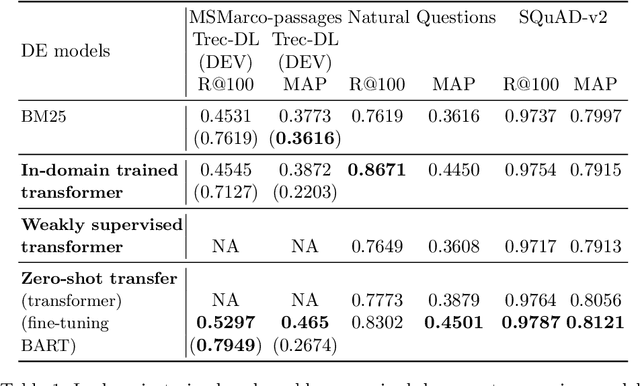
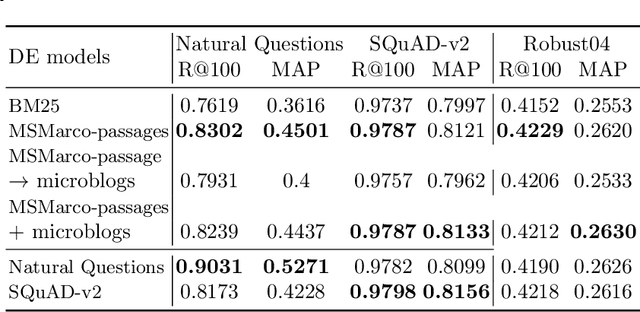
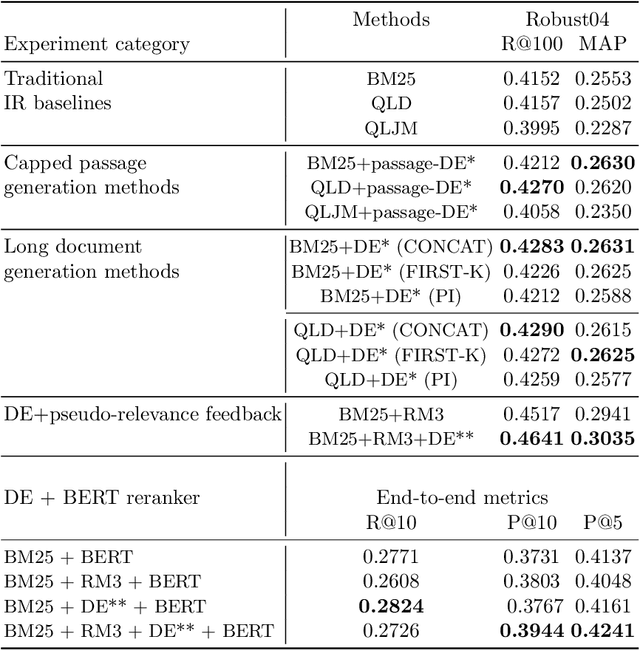
Recently, Nogueira et al. [2019] proposed a new approach to document expansion based on a neural Seq2Seq model, showing significant improvement on short text retrieval task. However, this approach needs a large amount of in-domain training data. In this paper, we show that this neural document expansion approach can be effectively adapted to standard IR tasks, where labels are scarce and many long documents are present.