Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural document expansion for ad-hoc information retrieval
Paper and Code
Dec 27, 2020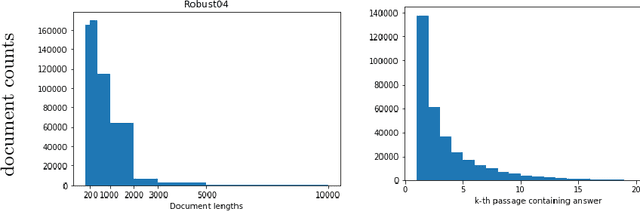
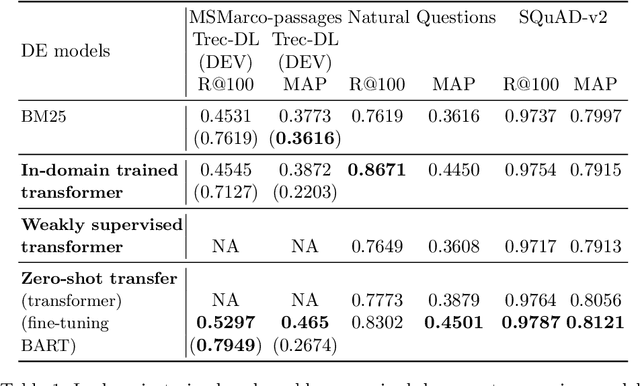
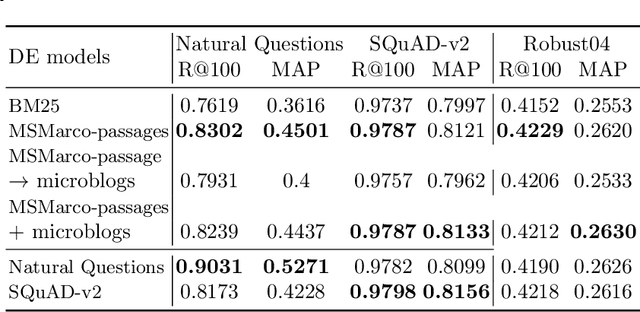
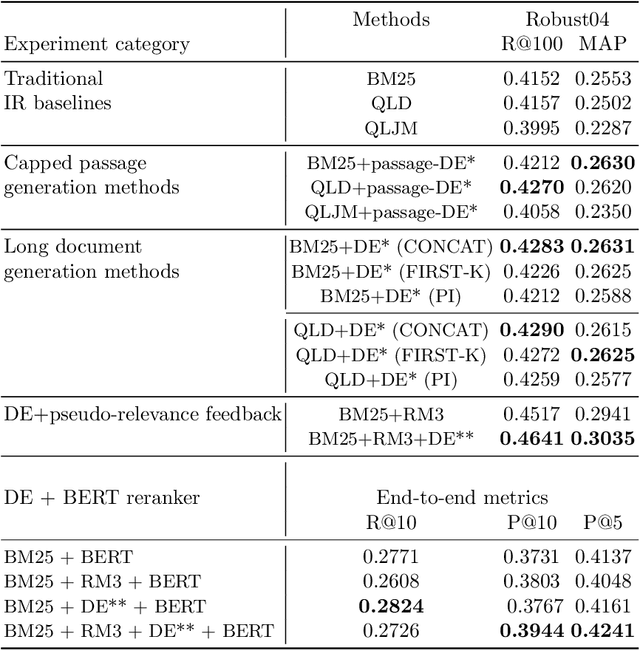
Recently, Nogueira et al. [2019] proposed a new approach to document expansion based on a neural Seq2Seq model, showing significant improvement on short text retrieval task. However, this approach needs a large amount of in-domain training data. In this paper, we show that this neural document expansion approach can be effectively adapted to standard IR tasks, where labels are scarce and many long documents are present.
View paper on