 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Procedure-aware Video Representation from Instructional Videos and Their Narrations
Mar 31, 2023The abundance of instructional videos and their narrations over the Internet offers an exciting avenue for understanding procedural activities. In this work, we propose to learn video representation that encodes both action steps and their temporal ordering, based on a large-scale dataset of web instructional videos and their narrations, without using human annotations. Our method jointly learns a video representation to encode individual step concepts, and a deep probabilistic model to capture both temporal dependencies and immense individual variations in the step ordering. We empirically demonstrate that learning temporal ordering not only enables new capabilities for procedure reasoning, but also reinforces the recognition of individual steps. Our model significantly advances the state-of-the-art results on step classification (+2.8% / +3.3% on COIN / EPIC-Kitchens) and step forecasting (+7.4% on COIN). Moreover, our model attains promising results in zero-shot inference for step classification and forecasting, as well as in predicting diverse and plausible steps for incomplete procedures. Our code is available at https://github.com/facebookresearch/ProcedureVRL.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
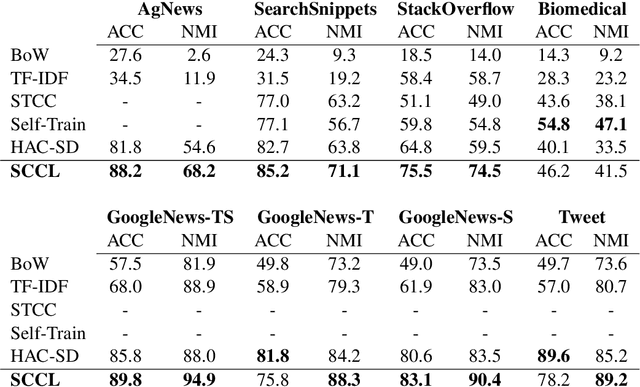
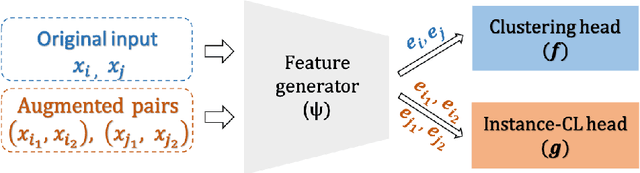
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels
Measuring and Predicting Tag Importance for Image Retrieval
Jan 09, 2017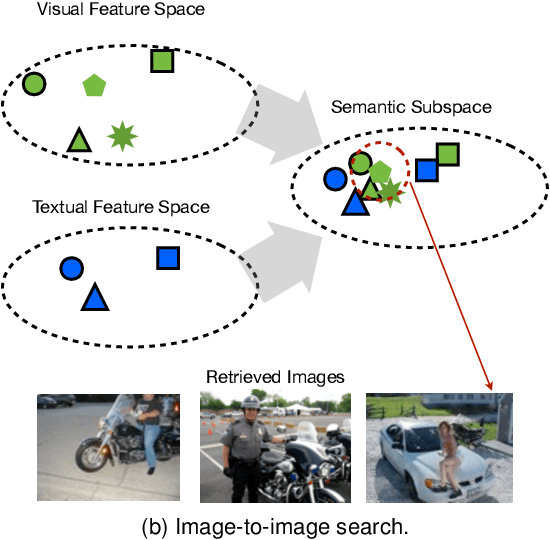
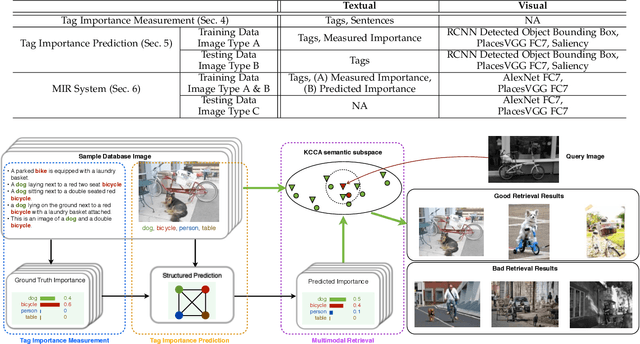

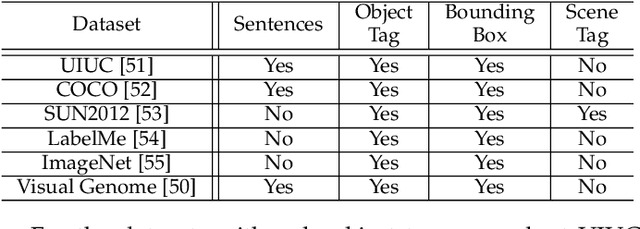
Textual data such as tags, sentence descriptions are combined with visual cues to reduce the semantic gap for image retrieval applications in today's Multimodal Image Retrieval (MIR) systems. However, all tags are treated as equally important in these systems, which may result in misalignment between visual and textual modalities during MIR training. This will further lead to degenerated retrieval performance at query time. To address this issue, we investigate the problem of tag importance prediction, where the goal is to automatically predict the tag importance and use it in image retrieval. To achieve this, we first propose a method to measure the relative importance of object and scene tags from image sentence descriptions. Using this as the ground truth, we present a tag importance prediction model to jointly exploit visual, semantic and context cues. The Structural Support Vector Machine (SSVM) formulation is adopted to ensure efficient training of the prediction model. Then, the Canonical Correlation Analysis (CCA) is employed to learn the relation between the image visual feature and tag importance to obtain robust retrieval performance. Experimental results on three real-world datasets show a significant performance improvement of the proposed MIR with Tag Importance Prediction (MIR/TIP) system over other MIR systems.
A Coarse-to-Fine Indoor Layout Estimation Method
Jul 03, 2016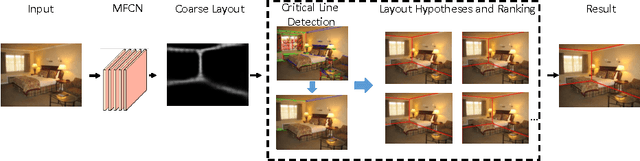

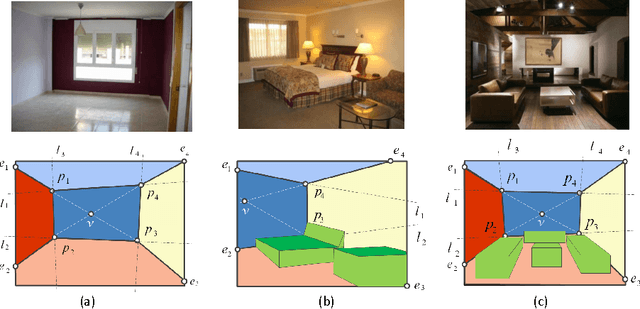
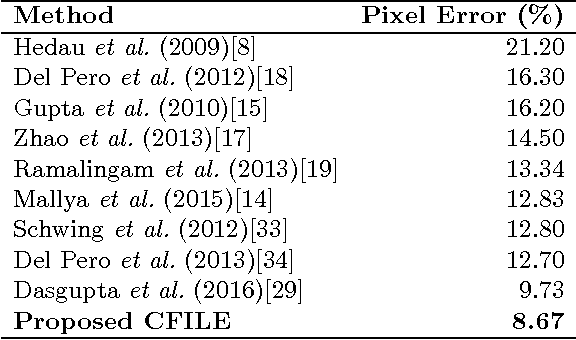
The task of estimating the spatial layout of cluttered indoor scenes from a single RGB image is addressed in this work. Existing solutions to this problems largely rely on hand-craft features and vanishing lines, and they often fail in highly cluttered indoor rooms. The proposed coarse-to-fine indoor layout estimation (CFILE) method consists of two stages: 1) coarse layout estimation; and 2) fine layout localization. In the first stage, we adopt a fully convolutional neural network (FCN) to obtain a coarse-scale room layout estimate that is close to the ground truth globally. The proposed FCN considers combines the layout contour property and the surface property so as to provide a robust estimate in the presence of cluttered objects. In the second stage, we formulate an optimization framework that enforces several constraints such as layout contour straightness, surface smoothness and geometric constraints for layout detail refinement. Our proposed system offers the state-of-the-art performance on two commonly used benchmark datasets.
GAL: A Global-Attributes Assisted Labeling System for Outdoor Scenes
Apr 03, 2016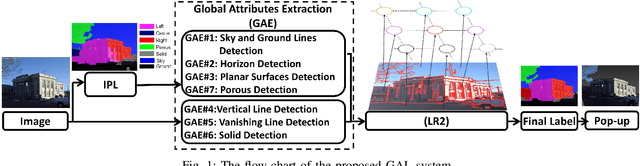

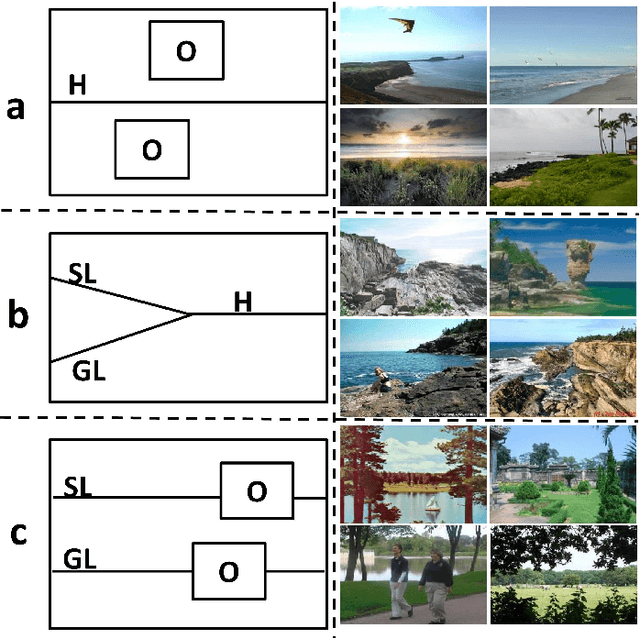

An approach that extracts global attributes from outdoor images to facilitate geometric layout labeling is investigated in this work. The proposed Global-attributes Assisted Labeling (GAL) system exploits both local features and global attributes. First, by following a classical method, we use local features to provide initial labels for all super-pixels. Then, we develop a set of techniques to extract global attributes from 2D outdoor images. They include sky lines, ground lines, vanishing lines, etc. Finally, we propose the GAL system that integrates global attributes in the conditional random field (CRF) framework to improve initial labels so as to offer a more robust labeling result. The performance of the proposed GAL system is demonstrated and benchmarked with several state-of-the-art algorithms against a popular outdoor scene layout dataset.