 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Blending for Multi-Camera Harmonization for Automotive Surround View Systems
Jun 16, 2024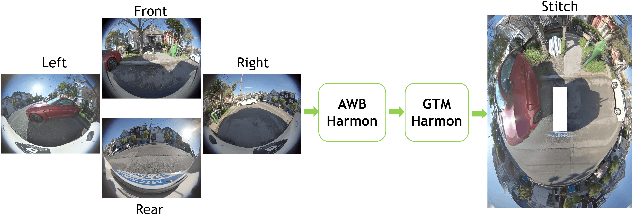


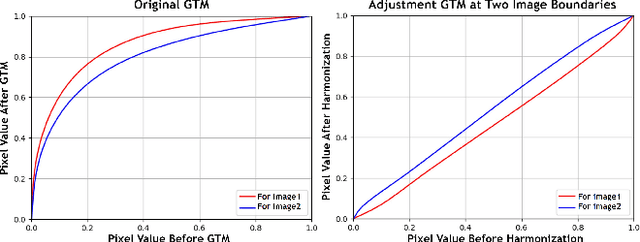
In a surround view system, the image color and tone captured by multiple cameras can be different due to cameras applying auto white balance (AWB), global tone mapping (GTM) individually for each camera. The color and brightness along stitched seam location may look discontinuous among multiple cameras which impacts overall stitched image visual quality. To improve the color transition between adjacent cameras in stitching algorithm, we propose harmonization algorithm which applies before stitching to adjust multiple cameras' color and tone so that stitched image has smoother color and tone transition between adjacent cameras. Our proposed harmonization algorithm consists of AWB harmonization and GTM harmonization leveraging Image Signal Processor (ISP)'s AWB and GTM metadata statistics. Experiment result shows that our proposed algorithm outperforms global color transfer method in both visual quality and computational cost.
Dual Attention Network for Heart Rate and Respiratory Rate Estimation
Oct 31, 2021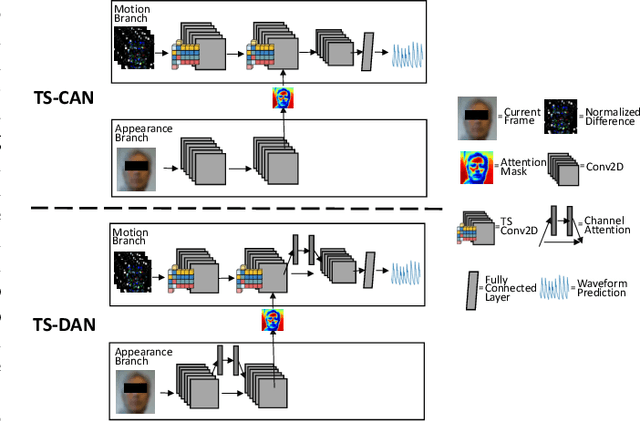
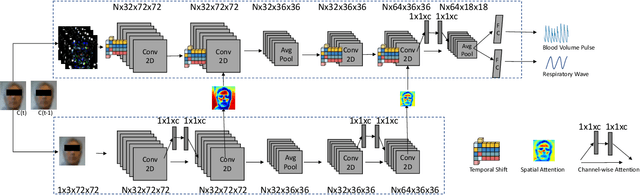
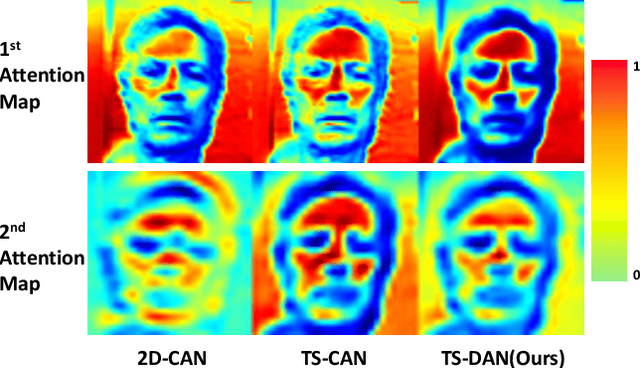

Heart rate and respiratory rate measurement is a vital step for diagnosing many diseases. Non-contact camera based physiological measurement is more accessible and convenient in Telehealth nowadays than contact instruments such as fingertip oximeters since non-contact methods reduce risk of infection. However, remote physiological signal measurement is challenging due to environment illumination variations, head motion, facial expression, etc. It's also desirable to have a unified network which could estimate both heart rate and respiratory rate to reduce system complexity and latency. We propose a convolutional neural network which leverages spatial attention and channel attention, which we call it dual attention network (DAN) to jointly estimate heart rate and respiratory rate with camera video as input. Extensive experiments demonstrate that our proposed system significantly improves heart rate and respiratory rate measurement accuracy.
Camera Calibration with Pose Guidance
Feb 19, 2021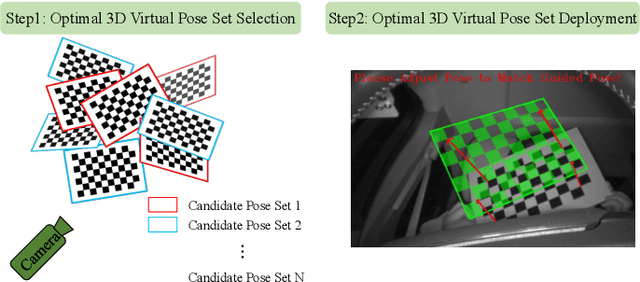
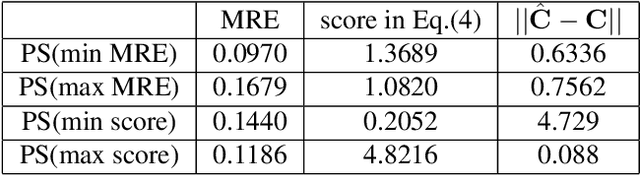
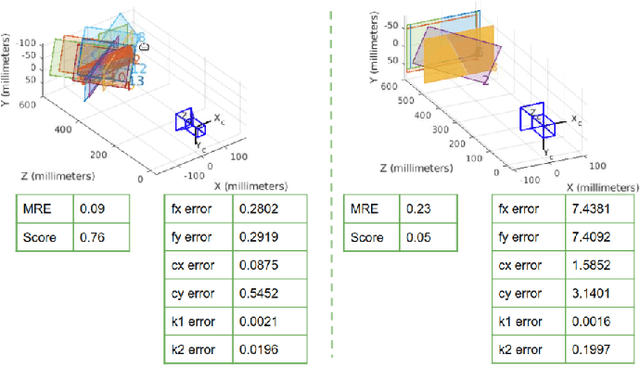
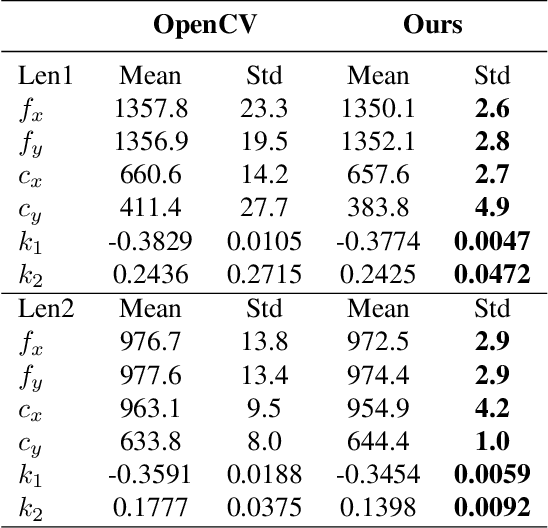
Camera calibration plays a critical role in various computer vision tasks such as autonomous driving or augmented reality. Widely used camera calibration tools utilize plane pattern based methodology, such as using a chessboard or AprilTag board, user's calibration expertise level significantly affects calibration accuracy and consistency when without clear instruction. Furthermore, calibration is a recurring task that has to be performed each time the camera is changed or moved. It's also a great burden to calibrate huge amounts of cameras such as Driver Monitoring System (DMS) cameras in a production line with millions of vehicles. To resolve above issues, we propose a calibration system called Calibration with Pose Guidance to improve calibration accuracy, reduce calibration variance among different users or different trials of the same person. Experiment result shows that our proposed method achieves more accurate and consistent calibration than traditional calibration tools.
Image Splicing Localization Using A Multi-Task Fully Convolutional Network (MFCN)
Sep 06, 2017



In this work, we propose a technique that utilizes a fully convolutional network (FCN) to localize image splicing attacks. We first evaluated a single-task FCN (SFCN) trained only on the surface label. Although the SFCN is shown to provide superior performance over existing methods, it still provides a coarse localization output in certain cases. Therefore, we propose the use of a multi-task FCN (MFCN) that utilizes two output branches for multi-task learning. One branch is used to learn the surface label, while the other branch is used to learn the edge or boundary of the spliced region. We trained the networks using the CASIA v2.0 dataset, and tested the trained models on the CASIA v1.0, Columbia Uncompressed, Carvalho, and the DARPA/NIST Nimble Challenge 2016 SCI datasets. Experiments show that the SFCN and MFCN outperform existing splicing localization algorithms, and that the MFCN can achieve finer localization than the SFCN.
* This manuscript was submitted for publication
Measuring and Predicting Tag Importance for Image Retrieval
Jan 09, 2017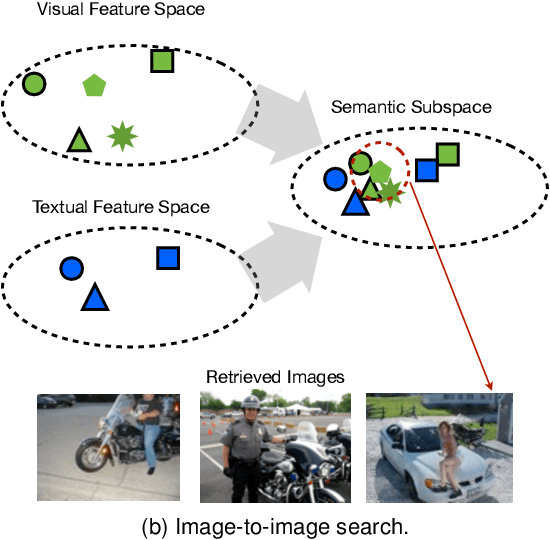
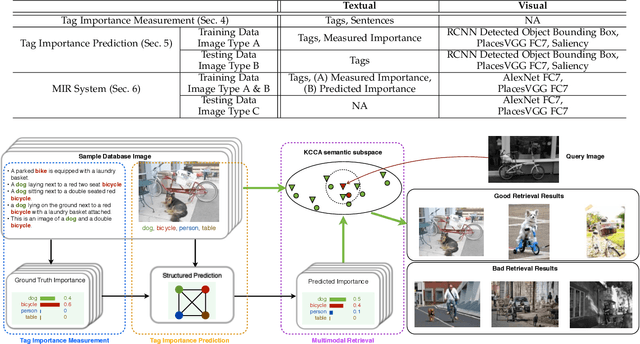

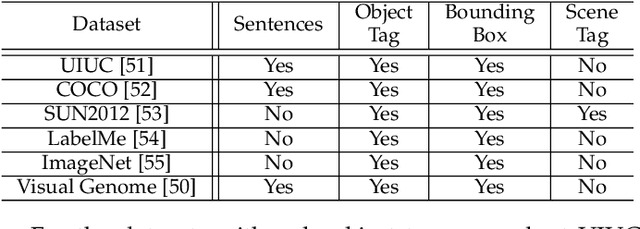
Textual data such as tags, sentence descriptions are combined with visual cues to reduce the semantic gap for image retrieval applications in today's Multimodal Image Retrieval (MIR) systems. However, all tags are treated as equally important in these systems, which may result in misalignment between visual and textual modalities during MIR training. This will further lead to degenerated retrieval performance at query time. To address this issue, we investigate the problem of tag importance prediction, where the goal is to automatically predict the tag importance and use it in image retrieval. To achieve this, we first propose a method to measure the relative importance of object and scene tags from image sentence descriptions. Using this as the ground truth, we present a tag importance prediction model to jointly exploit visual, semantic and context cues. The Structural Support Vector Machine (SSVM) formulation is adopted to ensure efficient training of the prediction model. Then, the Canonical Correlation Analysis (CCA) is employed to learn the relation between the image visual feature and tag importance to obtain robust retrieval performance. Experimental results on three real-world datasets show a significant performance improvement of the proposed MIR with Tag Importance Prediction (MIR/TIP) system over other MIR systems.
A Coarse-to-Fine Indoor Layout Estimation Method
Jul 03, 2016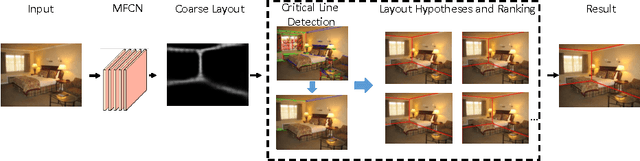

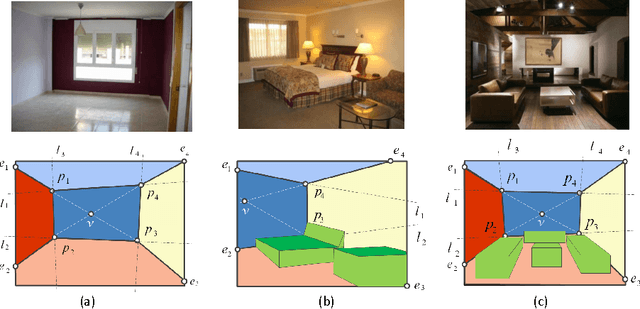
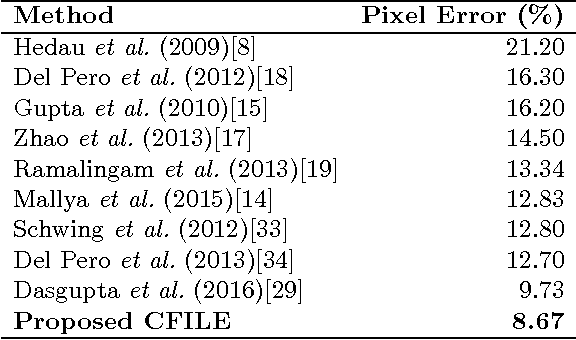
The task of estimating the spatial layout of cluttered indoor scenes from a single RGB image is addressed in this work. Existing solutions to this problems largely rely on hand-craft features and vanishing lines, and they often fail in highly cluttered indoor rooms. The proposed coarse-to-fine indoor layout estimation (CFILE) method consists of two stages: 1) coarse layout estimation; and 2) fine layout localization. In the first stage, we adopt a fully convolutional neural network (FCN) to obtain a coarse-scale room layout estimate that is close to the ground truth globally. The proposed FCN considers combines the layout contour property and the surface property so as to provide a robust estimate in the presence of cluttered objects. In the second stage, we formulate an optimization framework that enforces several constraints such as layout contour straightness, surface smoothness and geometric constraints for layout detail refinement. Our proposed system offers the state-of-the-art performance on two commonly used benchmark datasets.
GAL: A Global-Attributes Assisted Labeling System for Outdoor Scenes
Apr 03, 2016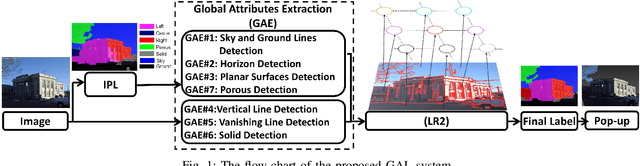

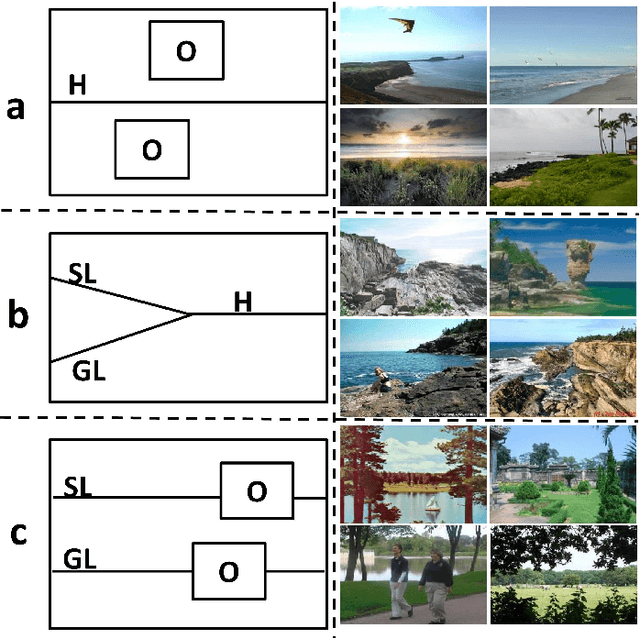

An approach that extracts global attributes from outdoor images to facilitate geometric layout labeling is investigated in this work. The proposed Global-attributes Assisted Labeling (GAL) system exploits both local features and global attributes. First, by following a classical method, we use local features to provide initial labels for all super-pixels. Then, we develop a set of techniques to extract global attributes from 2D outdoor images. They include sky lines, ground lines, vanishing lines, etc. Finally, we propose the GAL system that integrates global attributes in the conditional random field (CRF) framework to improve initial labels so as to offer a more robust labeling result. The performance of the proposed GAL system is demonstrated and benchmarked with several state-of-the-art algorithms against a popular outdoor scene layout dataset.